Das könnte Ihnen auch gefallen
- Jackson V AEGLive - May 10 Transcripts, of Karen Faye-Michael Jackson - Make-up/HairDokument65 SeitenJackson V AEGLive - May 10 Transcripts, of Karen Faye-Michael Jackson - Make-up/HairTeamMichael100% (2)
- The RBG Blueprint For Black Power Study Cell GuidebookDokument8 SeitenThe RBG Blueprint For Black Power Study Cell GuidebookAra SparkmanNoch keine Bewertungen
- 6.1 Sampling and Reconstruction of Analog Signals: Piyush Kumar 20104148901 G.E.C, KaimurDokument9 Seiten6.1 Sampling and Reconstruction of Analog Signals: Piyush Kumar 20104148901 G.E.C, KaimurEr VishuuuNoch keine Bewertungen
- Wavelet Based ECG Signal De-Noising: AbstractDokument5 SeitenWavelet Based ECG Signal De-Noising: AbstractPushpek SinghNoch keine Bewertungen
- 1 AutocorrelationDokument38 Seiten1 AutocorrelationpadikkatteNoch keine Bewertungen
- Sources of Hindu LawDokument9 SeitenSources of Hindu LawKrishnaKousikiNoch keine Bewertungen
- Interlocking Block TechnologyDokument15 SeitenInterlocking Block TechnologyChaula Trivedi100% (5)
- DSP-1 (Intro) (S)Dokument77 SeitenDSP-1 (Intro) (S)karthik0433Noch keine Bewertungen
- ECE Companies ListDokument9 SeitenECE Companies ListPolaiah Geriki100% (1)
- Heart Sounds and Heart Murmurs SepataionDokument9 SeitenHeart Sounds and Heart Murmurs SepataionAbcdNoch keine Bewertungen
- ECG Signal Feature Extraction Using Wavelet Transforms: Ruqaiya Khanam, Ranjana Prasad, Vinay AroraDokument4 SeitenECG Signal Feature Extraction Using Wavelet Transforms: Ruqaiya Khanam, Ranjana Prasad, Vinay AroraPriyadarshy KumarNoch keine Bewertungen
- JBiSE20090400005 96872795Dokument6 SeitenJBiSE20090400005 96872795Faisal Ahmad100% (1)
- Time-Frequency Analysis Heart Murmurs: ChildrenDokument4 SeitenTime-Frequency Analysis Heart Murmurs: ChildrenAman KatariaNoch keine Bewertungen
- Lab 2Dokument6 SeitenLab 2api-272723910Noch keine Bewertungen
- Yamamoto NoiseDokument195 SeitenYamamoto Noiseboris berkopecNoch keine Bewertungen
- Aiboud 2015Dokument6 SeitenAiboud 2015Leandro ViscomiNoch keine Bewertungen
- Ax 2419441946Dokument3 SeitenAx 2419441946IJMERNoch keine Bewertungen
- Averaging FitlerDokument7 SeitenAveraging FitlerDavidNoch keine Bewertungen
- A Theoretical and Experimental Analysis of The Acoustic GuitarDokument10 SeitenA Theoretical and Experimental Analysis of The Acoustic GuitarnitesheduNoch keine Bewertungen
- ECG Signal ClassificationDokument34 SeitenECG Signal ClassificationKani MozhiNoch keine Bewertungen
- Ecg CompressionDokument28 SeitenEcg Compressionpawan_32Noch keine Bewertungen
- Signal Averaging To Improve S-N RatioDokument9 SeitenSignal Averaging To Improve S-N RatiokreatosNoch keine Bewertungen
- Discrete Time Signals and Fourier SeriesDokument34 SeitenDiscrete Time Signals and Fourier SeriesFatima AhsanNoch keine Bewertungen
- Biomedical Instrumentation Practical File: Group 1 Ice - 3 Semester 7Dokument26 SeitenBiomedical Instrumentation Practical File: Group 1 Ice - 3 Semester 7Prabhav SinghNoch keine Bewertungen
- Advances in QRS Detection: Modified Wavelet Energy Gradient MethodDokument7 SeitenAdvances in QRS Detection: Modified Wavelet Energy Gradient MethodInternational Journal of Emerging Trends in Signal Processing (IJETSP)Noch keine Bewertungen
- Ultrasonic Signal De-Noising Using Dual Filtering AlgorithmDokument8 SeitenUltrasonic Signal De-Noising Using Dual Filtering Algorithmvhito619Noch keine Bewertungen
- Noise Removal From ECG Signal by Thresholding With Comparing Different Types of WaveletDokument7 SeitenNoise Removal From ECG Signal by Thresholding With Comparing Different Types of WaveletInternational Journal of Application or Innovation in Engineering & ManagementNoch keine Bewertungen
- Speech Endpoint Detection Based On Sub-Band Energy and Harmonic Structure of VoiceDokument9 SeitenSpeech Endpoint Detection Based On Sub-Band Energy and Harmonic Structure of VoiceMicro TuấnNoch keine Bewertungen
- SpectrogramDokument17 SeitenSpectrogramShanmugaraj VskNoch keine Bewertungen
- Automation of ECG Heart Beat Detection Using Morphological Filtering and Daubechies Wavelet TransformDokument6 SeitenAutomation of ECG Heart Beat Detection Using Morphological Filtering and Daubechies Wavelet TransformIOSRJEN : hard copy, certificates, Call for Papers 2013, publishing of journalNoch keine Bewertungen
- Problem StatementDokument18 SeitenProblem StatementvmrekhateNoch keine Bewertungen
- Wavelet Based Normal and Abnormal Heart Sound Identification Using Spectrogram AnalysisDokument7 SeitenWavelet Based Normal and Abnormal Heart Sound Identification Using Spectrogram AnalysisVishwanath ShervegarNoch keine Bewertungen
- EWGAE 2010: Intelligent AE Signal Filtering MethodsDokument6 SeitenEWGAE 2010: Intelligent AE Signal Filtering Methodsvassili_iuNoch keine Bewertungen
- Lab 4 ECG Dan HuynhDokument13 SeitenLab 4 ECG Dan Huynhdhdan27Noch keine Bewertungen
- Detection of Heart Blocks by Cardiac Cycle Extraction Using Time - Scale AnalysisDokument5 SeitenDetection of Heart Blocks by Cardiac Cycle Extraction Using Time - Scale AnalysisInternational Journal of Emerging Trends in Signal Processing (IJETSP)Noch keine Bewertungen
- International Journal of Engineering Research and Development (IJERD)Dokument5 SeitenInternational Journal of Engineering Research and Development (IJERD)IJERDNoch keine Bewertungen
- Robust and Efficient Pitch Tracking For Query-by-Humming: Yongwei Zhu, Mohan S KankanhalliDokument5 SeitenRobust and Efficient Pitch Tracking For Query-by-Humming: Yongwei Zhu, Mohan S KankanhalliRam Krishna VodnalaNoch keine Bewertungen
- 3 Chapter BMSPDokument41 Seiten3 Chapter BMSPSravani KumariNoch keine Bewertungen
- Content-Based Classification of Musical Instrument Timbres: Agostini Longari PollastriDokument8 SeitenContent-Based Classification of Musical Instrument Timbres: Agostini Longari Pollastrihrishi30Noch keine Bewertungen
- Industrial Internship PPT - 2Dokument24 SeitenIndustrial Internship PPT - 2Atul DwivediNoch keine Bewertungen
- A Comparative Study of Heart Rate Estimation Via Air Pressure SensorDokument6 SeitenA Comparative Study of Heart Rate Estimation Via Air Pressure SensorJavier NavarroNoch keine Bewertungen
- Neural Network Based EEG Denoising: Yongjian Chen, Masatake Akutagawa, Masato Katayama, Qinyu Zhang and Yohsuke KinouchiDokument4 SeitenNeural Network Based EEG Denoising: Yongjian Chen, Masatake Akutagawa, Masato Katayama, Qinyu Zhang and Yohsuke KinouchiwriteahmedNoch keine Bewertungen
- Audio Analysis Using The Discrete Wavelet Transform: 1 2 Related WorkDokument6 SeitenAudio Analysis Using The Discrete Wavelet Transform: 1 2 Related WorkAlexandro NababanNoch keine Bewertungen
- Identification of Sudden Cardiac Death Using Spectral Domain Analysis of Electrocardiogram (ECG)Dokument6 SeitenIdentification of Sudden Cardiac Death Using Spectral Domain Analysis of Electrocardiogram (ECG)kalyanNoch keine Bewertungen
- CH03 DSP SignalDokument12 SeitenCH03 DSP SignalGözde NurNoch keine Bewertungen
- Noise Analysis and Different Denoising Techniques of ECG Signal - A SurveyDokument5 SeitenNoise Analysis and Different Denoising Techniques of ECG Signal - A SurveyMona NaiduNoch keine Bewertungen
- Sound Quality Analysis of CymbalsDokument9 SeitenSound Quality Analysis of Cymbalsapi-643891443Noch keine Bewertungen
- Muscle Noise Cancellation From ECG SignalDokument8 SeitenMuscle Noise Cancellation From ECG SignalAkilesh MDNoch keine Bewertungen
- Heart Arrhythmia Detection and Its Analysis Using Matlab IJERTV10IS110176Dokument5 SeitenHeart Arrhythmia Detection and Its Analysis Using Matlab IJERTV10IS110176EBXC 7S13Noch keine Bewertungen
- Ecg Signal Processing and Heart Rate Frequency Detection MethodsDokument6 SeitenEcg Signal Processing and Heart Rate Frequency Detection MethodsboyhuesdNoch keine Bewertungen
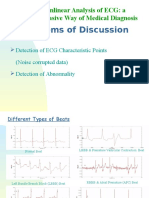
- Problems of Discussion: Nonlinear Analysis of ECG: A Noninvasive Way of Medical DiagnosisDokument48 SeitenProblems of Discussion: Nonlinear Analysis of ECG: A Noninvasive Way of Medical DiagnosisNur HossainNoch keine Bewertungen
- ST Wavelet FinalDokument4 SeitenST Wavelet Finalwrite2skNoch keine Bewertungen
- Medical Applications of DSP: Made By-Digisha Singhal 13bec026 Kinjal Aggrawal 13bec054 Guided by - Dr. Mehul NaikDokument16 SeitenMedical Applications of DSP: Made By-Digisha Singhal 13bec026 Kinjal Aggrawal 13bec054 Guided by - Dr. Mehul NaikPriyank KeniNoch keine Bewertungen
- The High-Frequency Weak Signal Detection Based On Stochastic ResonanceDokument4 SeitenThe High-Frequency Weak Signal Detection Based On Stochastic ResonanceEsteban RodriguezNoch keine Bewertungen
- KishalayVelaReport PDFDokument9 SeitenKishalayVelaReport PDFErwin SNoch keine Bewertungen
- Physiological Signal Processing Primer: Thought Technology LTDDokument5 SeitenPhysiological Signal Processing Primer: Thought Technology LTDJeff RobertNoch keine Bewertungen
- Spectral Analysis of A PWM SignalDokument4 SeitenSpectral Analysis of A PWM Signalpiyushvarsh0Noch keine Bewertungen
- K. Khaldi, A.O. Boudraa, B. Torr Esani, Th. Chonavel and M. TurkiDokument4 SeitenK. Khaldi, A.O. Boudraa, B. Torr Esani, Th. Chonavel and M. TurkiKhaled GharbiNoch keine Bewertungen
- Yongjune Shin, Sang-Won Nam, Chong-Koo An, and Edward J. PowersDokument4 SeitenYongjune Shin, Sang-Won Nam, Chong-Koo An, and Edward J. PowersJuan García LópezNoch keine Bewertungen
- Demodulation and Detection TechniquesDokument83 SeitenDemodulation and Detection TechniquesDotun OpasinaNoch keine Bewertungen
- BIOEN 481 Stethoscope Testing ReportDokument7 SeitenBIOEN 481 Stethoscope Testing ReportchaocharliehuangNoch keine Bewertungen
- Copied ChapterDokument10 SeitenCopied ChapterMagedNoch keine Bewertungen
- Time-Frequency Domain for Segmentation and Classification of Non-stationary Signals: The Stockwell Transform Applied on Bio-signals and Electric SignalsVon EverandTime-Frequency Domain for Segmentation and Classification of Non-stationary Signals: The Stockwell Transform Applied on Bio-signals and Electric SignalsNoch keine Bewertungen
- Progressive Muscle RelaxationDokument4 SeitenProgressive Muscle RelaxationEstéphany Rodrigues ZanonatoNoch keine Bewertungen
- Speech On Viewing SkillsDokument1 SeiteSpeech On Viewing SkillsMera Largosa ManlaweNoch keine Bewertungen
- PresentationDokument27 SeitenPresentationMenuka WatankachhiNoch keine Bewertungen
- Export Management EconomicsDokument30 SeitenExport Management EconomicsYash SampatNoch keine Bewertungen
- Chhay Chihour - SS402 Mid-Term 2020 - E4.2Dokument8 SeitenChhay Chihour - SS402 Mid-Term 2020 - E4.2Chi Hour100% (1)
- Kiritsis SolutionsDokument200 SeitenKiritsis SolutionsSagnik MisraNoch keine Bewertungen
- YIC Chapter 1 (2) MKTDokument63 SeitenYIC Chapter 1 (2) MKTMebre WelduNoch keine Bewertungen
- Apron CapacityDokument10 SeitenApron CapacityMuchammad Ulil AidiNoch keine Bewertungen
- Safety Procedures in Using Hand Tools and EquipmentDokument12 SeitenSafety Procedures in Using Hand Tools and EquipmentJan IcejimenezNoch keine Bewertungen
- MCI Approved Medical College in Uzbekistan PDFDokument3 SeitenMCI Approved Medical College in Uzbekistan PDFMBBS ABROADNoch keine Bewertungen
- Acute Appendicitis in Children - Diagnostic Imaging - UpToDateDokument28 SeitenAcute Appendicitis in Children - Diagnostic Imaging - UpToDateHafiz Hari NugrahaNoch keine Bewertungen
- Fundaciones Con PilotesDokument48 SeitenFundaciones Con PilotesReddy M.Ch.Noch keine Bewertungen
- Topic 3Dokument21 SeitenTopic 3Ivan SimonNoch keine Bewertungen
- Heimbach - Keeping Formingfabrics CleanDokument4 SeitenHeimbach - Keeping Formingfabrics CleanTunç TürkNoch keine Bewertungen
- Cable To Metal Surface, Cathodic - CAHAAW3Dokument2 SeitenCable To Metal Surface, Cathodic - CAHAAW3lhanx2Noch keine Bewertungen
- Lesson 6 - Vibration ControlDokument62 SeitenLesson 6 - Vibration ControlIzzat IkramNoch keine Bewertungen
- Lesson 3 - ReviewerDokument6 SeitenLesson 3 - ReviewerAdrian MarananNoch keine Bewertungen
- Applied Economics 2Dokument8 SeitenApplied Economics 2Sayra HidalgoNoch keine Bewertungen
- Fundamentals of Public Health ManagementDokument3 SeitenFundamentals of Public Health ManagementHPMA globalNoch keine Bewertungen
- Chapter 4 Achieving Clarity and Limiting Paragraph LengthDokument1 SeiteChapter 4 Achieving Clarity and Limiting Paragraph Lengthapi-550339812Noch keine Bewertungen
- Canon Powershot S50 Repair Manual (CHAPTER 4. PARTS CATALOG) PDFDokument13 SeitenCanon Powershot S50 Repair Manual (CHAPTER 4. PARTS CATALOG) PDFRita CaselliNoch keine Bewertungen
- Quiz 140322224412 Phpapp02Dokument26 SeitenQuiz 140322224412 Phpapp02Muhammad Mubeen Iqbal PuriNoch keine Bewertungen
- Micro Lab Midterm Study GuideDokument15 SeitenMicro Lab Midterm Study GuideYvette Salomé NievesNoch keine Bewertungen
- Shakespeare Sonnet EssayDokument3 SeitenShakespeare Sonnet Essayapi-5058594660% (1)
- Student Exploration: Inclined Plane - Simple MachineDokument9 SeitenStudent Exploration: Inclined Plane - Simple MachineLuka MkrtichyanNoch keine Bewertungen