Das könnte Ihnen auch gefallen
- Digital Electronics, Computer Architecture and Microprocessor Design PrinciplesVon EverandDigital Electronics, Computer Architecture and Microprocessor Design PrinciplesNoch keine Bewertungen
- Lecture 18 - RICS and CISC PropertiesDokument8 SeitenLecture 18 - RICS and CISC PropertiesPragya SinghNoch keine Bewertungen
- PLC: Programmable Logic Controller – Arktika.: EXPERIMENTAL PRODUCT BASED ON CPLD.Von EverandPLC: Programmable Logic Controller – Arktika.: EXPERIMENTAL PRODUCT BASED ON CPLD.Noch keine Bewertungen
- CH 2 Vector ProcessingDokument16 SeitenCH 2 Vector Processingdigvijay dholeNoch keine Bewertungen
- Processor ArchitectureDokument13 SeitenProcessor ArchitectureVinod kumarNoch keine Bewertungen
- SIMD PresentationDokument28 SeitenSIMD PresentationHuzaifaNoch keine Bewertungen
- Processor ArchitectureDokument13 SeitenProcessor ArchitectureAnonymous kAUFuWZjP2Noch keine Bewertungen
- Parallelism in Computer ArchitectureDokument27 SeitenParallelism in Computer ArchitectureKumarNoch keine Bewertungen
- Module-1 ACADokument44 SeitenModule-1 ACAVirupakshi PatilNoch keine Bewertungen
- Ca Unit 4 PrabuDokument24 SeitenCa Unit 4 Prabu6109 Sathish Kumar JNoch keine Bewertungen
- Cloud Computing - Lecture 3Dokument22 SeitenCloud Computing - Lecture 3Muhammad FahadNoch keine Bewertungen
- Advanced Computer Architecture: Presented By, KrishnaDokument35 SeitenAdvanced Computer Architecture: Presented By, KrishnaLekshmiNoch keine Bewertungen
- Microprocessor and Assembly Language Lecture Note For Ndii Computer EngineeringDokument25 SeitenMicroprocessor and Assembly Language Lecture Note For Ndii Computer EngineeringAbdulhamid DaudaNoch keine Bewertungen
- S 8 Mod 1Dokument33 SeitenS 8 Mod 1sheenaneesNoch keine Bewertungen
- Comparison of Multimedia SIMD, GPUs and VectorDokument13 SeitenComparison of Multimedia SIMD, GPUs and VectorHarsh PrasadNoch keine Bewertungen
- Processor Types: RISC Processor RISC Stands For Reduced Instruction SetDokument9 SeitenProcessor Types: RISC Processor RISC Stands For Reduced Instruction SetDebashish RoyNoch keine Bewertungen
- Design of 32-Bit Risc Cpu Based On Mips: Journal of Global Research in Computer ScienceDokument5 SeitenDesign of 32-Bit Risc Cpu Based On Mips: Journal of Global Research in Computer ScienceAkanksha Dixit ManodhyaNoch keine Bewertungen
- Cs8083 Notes McapDokument187 SeitenCs8083 Notes Mcapvkiruthiga390Noch keine Bewertungen
- 1 - Microcontroller Vs MicroprocessorDokument19 Seiten1 - Microcontroller Vs MicroprocessorLong NguyenNoch keine Bewertungen
- Coa CT 1 QBDokument43 SeitenCoa CT 1 QBNilesh bibhutiNoch keine Bewertungen
- Advanced Computer Architecture 1 1Dokument118 SeitenAdvanced Computer Architecture 1 1SharathMenonNoch keine Bewertungen
- 24-25 - Parallel Processing PDFDokument36 Seiten24-25 - Parallel Processing PDFfanna786Noch keine Bewertungen
- ModelDokument14 SeitenModelASHWANI MISHRANoch keine Bewertungen
- The Simplest Way To Examine The Advantages and Disadvantages of RISC Architecture Is by Contrasting It With ItDokument11 SeitenThe Simplest Way To Examine The Advantages and Disadvantages of RISC Architecture Is by Contrasting It With ItsaadawarNoch keine Bewertungen
- Lecture 10Dokument34 SeitenLecture 10MAIMONA KHALIDNoch keine Bewertungen
- CA Classes-236-240Dokument5 SeitenCA Classes-236-240SrinivasaRaoNoch keine Bewertungen
- Mcap NotesDokument186 SeitenMcap Notesbhuvanesh.cse23Noch keine Bewertungen
- CA Classes-221-225Dokument5 SeitenCA Classes-221-225SrinivasaRaoNoch keine Bewertungen
- ELT3047 Computer Architecture: Lesson 3: ISA Design PrinciplesDokument32 SeitenELT3047 Computer Architecture: Lesson 3: ISA Design PrinciplesHoang Anh VuNoch keine Bewertungen
- SIMD ArchitectureDokument16 SeitenSIMD Architecturebinzidd007100% (1)
- Unit 5 (Coa) NotesDokument35 SeitenUnit 5 (Coa) NotesmudiyalaruchithaNoch keine Bewertungen
- UNIT-1 Introduction To MicrocontrollersDokument8 SeitenUNIT-1 Introduction To MicrocontrollerssupriyaNoch keine Bewertungen
- Flynn'S Classification: Cs6303 Computer ArchitectureDokument11 SeitenFlynn'S Classification: Cs6303 Computer ArchitectureJeya Sheeba ANoch keine Bewertungen
- Structure of Computer SystemsDokument16 SeitenStructure of Computer SystemsMussie KebedeNoch keine Bewertungen
- MPMC (Unit 01) Part 02Dokument39 SeitenMPMC (Unit 01) Part 02bovas.biju2021Noch keine Bewertungen
- BCSE412L - Parallel Computing 04Dokument9 SeitenBCSE412L - Parallel Computing 04aavsgptNoch keine Bewertungen
- Multiprocessor Is A Computer Used For Processing and Executes IsolatedDokument6 SeitenMultiprocessor Is A Computer Used For Processing and Executes IsolatedAnubhav KumarNoch keine Bewertungen
- Introduction To Micro ProcessorsDokument9 SeitenIntroduction To Micro ProcessorsJapheth NgugiNoch keine Bewertungen
- CSE 259 Lecture4Dokument14 SeitenCSE 259 Lecture4robin haqueNoch keine Bewertungen
- Parallel ComputingDokument32 SeitenParallel ComputingKhushal BisaniNoch keine Bewertungen
- 1.2 Underlying Principles of Parallel and Distributed ComputingDokument42 Seiten1.2 Underlying Principles of Parallel and Distributed Computingbkentertainment56Noch keine Bewertungen
- Quad-Core Microprocessor Specific Architectures: Coordinating Teacher - Radescu RaduDokument23 SeitenQuad-Core Microprocessor Specific Architectures: Coordinating Teacher - Radescu RaduViorel CraciunNoch keine Bewertungen
- MICROPROCESSOR DESIGNING by UPKARDokument42 SeitenMICROPROCESSOR DESIGNING by UPKARUpkar ChauhanNoch keine Bewertungen
- 32 Bit Risc ProcessorDokument60 Seiten32 Bit Risc ProcessorMuruganantham MuthusamyNoch keine Bewertungen
- Complex Instruction Set ComputerDokument17 SeitenComplex Instruction Set ComputerkangkanpaulNoch keine Bewertungen
- DSP Mod 6Dokument6 SeitenDSP Mod 6Aabha KadamNoch keine Bewertungen
- Module-1 Theory of Parallelism: The State of Computing Computer Development MilestonesDokument48 SeitenModule-1 Theory of Parallelism: The State of Computing Computer Development MilestonesUdupiSri groupNoch keine Bewertungen
- Unit 3 NotesDokument9 SeitenUnit 3 NotesPurvi ChaurasiaNoch keine Bewertungen
- Multi ThreadingDokument168 SeitenMulti ThreadingPrashanth RajendranNoch keine Bewertungen
- Chapter-1 Parallel Computer Models: Module-1Dokument42 SeitenChapter-1 Parallel Computer Models: Module-1Rahul RajNoch keine Bewertungen
- Embedded Systems Btcse-Oe43: By: Naved Alam Assistant Professor (ECE) SEST, Jamia HamdardDokument42 SeitenEmbedded Systems Btcse-Oe43: By: Naved Alam Assistant Professor (ECE) SEST, Jamia Hamdardanon_947471502Noch keine Bewertungen
- High Performance Computing On GpuDokument37 SeitenHigh Performance Computing On GpuSushant SharmaNoch keine Bewertungen
- Lecture Notes-Computer Architecture-Module 1Dokument20 SeitenLecture Notes-Computer Architecture-Module 1mokshagnanare26Noch keine Bewertungen
- Advanced Computer ArchitectureDokument28 SeitenAdvanced Computer ArchitectureSameer KhudeNoch keine Bewertungen
- Design IssuesDokument12 SeitenDesign IssuesAnonymous uspYoqENoch keine Bewertungen
- ACA Notes TechJourney PDFDokument206 SeitenACA Notes TechJourney PDFPrakhyath JainNoch keine Bewertungen
- Module 1 ACADokument42 SeitenModule 1 ACARupesh Sapkota86% (7)
- Lecture 28Dokument22 SeitenLecture 28Udai ValluruNoch keine Bewertungen
- RTS Module 2 Part A NotesDokument11 SeitenRTS Module 2 Part A NotesVignesh H VNoch keine Bewertungen
- Parallel Processing in Processor Organization: Prabhudev S IrabashettiDokument4 SeitenParallel Processing in Processor Organization: Prabhudev S IrabashettiAdiq CoolNoch keine Bewertungen
- Enterprise Manager Cloud Control Administrators Guide 13.4Dokument1.205 SeitenEnterprise Manager Cloud Control Administrators Guide 13.4Shaik MujeebNoch keine Bewertungen
- Picoblaze 2022Dokument57 SeitenPicoblaze 2022Alex PérezNoch keine Bewertungen
- Veritas Backup Exec 16 DsDokument5 SeitenVeritas Backup Exec 16 Dsjuan.pasion3696Noch keine Bewertungen
- 2.2.4.9 Packet Tracer - Configuring Switch Port SecurityDokument21 Seiten2.2.4.9 Packet Tracer - Configuring Switch Port Securityedward alberto silva bolivarNoch keine Bewertungen
- M365 Modern Desktop Administrator Learning Path (Oct 2019)Dokument1 SeiteM365 Modern Desktop Administrator Learning Path (Oct 2019)m00anj00Noch keine Bewertungen
- Manual ScadaBRDokument70 SeitenManual ScadaBRpeter de scheterNoch keine Bewertungen
- Leica Infinity DS 808992 0422 en LRDokument4 SeitenLeica Infinity DS 808992 0422 en LRRiko DoanxNoch keine Bewertungen
- MCU IO Expander IntelDokument11 SeitenMCU IO Expander IntelPrabakaran EllaiyappanNoch keine Bewertungen
- Passive Optical NetworksDokument7 SeitenPassive Optical NetworksTarundeep RainaNoch keine Bewertungen
- Video Graphics ArrayDokument11 SeitenVideo Graphics ArrayIdris DinNoch keine Bewertungen
- Lenovo Legion 5 15IAH7H: 82RB0000SBDokument2 SeitenLenovo Legion 5 15IAH7H: 82RB0000SBVasudev GovindanNoch keine Bewertungen
- TutorialDokument113 SeitenTutorialSerge charpentierNoch keine Bewertungen
- AMERICAN MonitorUsersGuideDokument7 SeitenAMERICAN MonitorUsersGuideAbraão MunizNoch keine Bewertungen
- IT Change Management PolicyDokument25 SeitenIT Change Management Policyowen100% (1)
- Reovib Smart: Phase-Angle Controller For Vibratory FeedersDokument2 SeitenReovib Smart: Phase-Angle Controller For Vibratory Feederschris bourNoch keine Bewertungen
- Illustrated Assembly Manual k4306 PDFDokument16 SeitenIllustrated Assembly Manual k4306 PDFcicero220358Noch keine Bewertungen
- Epicor905 Install Guide SQLDokument112 SeitenEpicor905 Install Guide SQLhereje73Noch keine Bewertungen
- AtmDokument33 SeitenAtmShayani BatabyalNoch keine Bewertungen
- Client - Server Architecture: A Basic IntroductionDokument12 SeitenClient - Server Architecture: A Basic IntroductionRodel D DosanoNoch keine Bewertungen
- Notes Oopm Unit 1Dokument38 SeitenNotes Oopm Unit 1elishasupreme30Noch keine Bewertungen
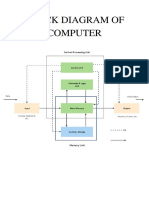
- Block Diagram of ComputerDokument19 SeitenBlock Diagram of ComputerMrNothing100% (2)
- Electronic NoseDokument30 SeitenElectronic NoseLanka Vinay NagNoch keine Bewertungen
- Aviator 200 300 350 700 Software Update READ THIS FIRST Revision 1.30.2024Dokument2 SeitenAviator 200 300 350 700 Software Update READ THIS FIRST Revision 1.30.202458splitrailNoch keine Bewertungen
- ABAP - PO HistoryDokument4 SeitenABAP - PO HistoryinasapNoch keine Bewertungen
- Taw12 2Dokument2 SeitenTaw12 2Amol NagapNoch keine Bewertungen
- 808D Diagnostics Manual 0615 en en-USDokument566 Seiten808D Diagnostics Manual 0615 en en-USSatish KumarNoch keine Bewertungen
- Nexia Main Control Trouble ShootingDokument9 SeitenNexia Main Control Trouble ShootingSaul BarocioNoch keine Bewertungen
- .Java Tricks For Competitive Programming (For Java 8) - GeeksforGeeksDokument8 Seiten.Java Tricks For Competitive Programming (For Java 8) - GeeksforGeeksAkash ShawNoch keine Bewertungen
- Radio-Frequency Identification (Rfid) : Internal Test IDokument6 SeitenRadio-Frequency Identification (Rfid) : Internal Test IjayanthikrishnanNoch keine Bewertungen
- Veritas Cluster Tasks Create A Service GroupDokument4 SeitenVeritas Cluster Tasks Create A Service GroupRocky RayNoch keine Bewertungen