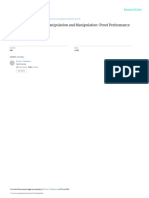
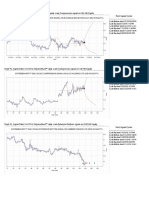
Das könnte Ihnen auch gefallen
- Pseudo-Mathematics and Financial Charlatanism. The Effects of Backtest Overfitting On Out of Sample Performance PDFDokument14 SeitenPseudo-Mathematics and Financial Charlatanism. The Effects of Backtest Overfitting On Out of Sample Performance PDFEduardo E. SalasNoch keine Bewertungen
- Me and YouDokument8 SeitenMe and YouLaffin Ebi LaffinNoch keine Bewertungen
- Back Ground of The StudyDokument6 SeitenBack Ground of The StudyTesfaye KebebawNoch keine Bewertungen
- Evaluating MFundsDokument46 SeitenEvaluating MFundssubratNoch keine Bewertungen
- SSRN Id2615667Dokument94 SeitenSSRN Id2615667szaszaszNoch keine Bewertungen
- Predictable Variation and Pro"table Trading of US Equities: A Trading Simulation Using Neural NetworksDokument19 SeitenPredictable Variation and Pro"table Trading of US Equities: A Trading Simulation Using Neural NetworksJulio OliveiraNoch keine Bewertungen
- Bhojraj and Lee - Week7 PDFDokument33 SeitenBhojraj and Lee - Week7 PDFRohit RajNoch keine Bewertungen
- SSRN Id937847Dokument18 SeitenSSRN Id937847Srinu BonuNoch keine Bewertungen
- Feature Learning For Stock Price Prediction Shows A Significant Role of Analyst RatingDokument20 SeitenFeature Learning For Stock Price Prediction Shows A Significant Role of Analyst RatingPrice MechanicsNoch keine Bewertungen
- Measuring Effectiveness of Quantitative Equity Portfolio Management MethodsDokument25 SeitenMeasuring Effectiveness of Quantitative Equity Portfolio Management MethodsNilesh SoniNoch keine Bewertungen
- Cf-Unit - IvDokument17 SeitenCf-Unit - IvSabha PathyNoch keine Bewertungen
- Robust Portfolio Optimization: A Categorized Bibliographic ReviewDokument20 SeitenRobust Portfolio Optimization: A Categorized Bibliographic ReviewDebNoch keine Bewertungen
- CH 1Dokument11 SeitenCH 1321312 312123Noch keine Bewertungen
- Backtest Overfitting Demonstration ToolDokument9 SeitenBacktest Overfitting Demonstration ToolmikhaillevNoch keine Bewertungen
- SSRN-id302815 2Dokument49 SeitenSSRN-id302815 2shahrukhmpenkerNoch keine Bewertungen
- Armitage1995 - Methods AR PDFDokument28 SeitenArmitage1995 - Methods AR PDFNicolas CopernicNoch keine Bewertungen
- Shortterm Stock Market Timing Prediction Under Reinforcement Learning SchemesDokument8 SeitenShortterm Stock Market Timing Prediction Under Reinforcement Learning SchemesbboyvnNoch keine Bewertungen
- Managerial Decisions and Long-Term Stock Price PerformanceDokument44 SeitenManagerial Decisions and Long-Term Stock Price PerformanceLeszek CzapiewskiNoch keine Bewertungen
- Pairs Trading G GRDokument31 SeitenPairs Trading G GRSrinu BonuNoch keine Bewertungen
- Demand ForecastingDokument23 SeitenDemand Forecastingp11ashishkNoch keine Bewertungen
- 2018 Alberto Rossi Fall Seminar Paper 1 Stock Market ReturnsDokument44 Seiten2018 Alberto Rossi Fall Seminar Paper 1 Stock Market Returns1by20is020Noch keine Bewertungen
- Man AHL Analysis Backtesting ENG 20152728Dokument33 SeitenMan AHL Analysis Backtesting ENG 20152728kevinNoch keine Bewertungen
- Hedge Fund Replication: A Model Combination Approach: Michael O'Doherty N. E. Savin Ashish TiwariDokument44 SeitenHedge Fund Replication: A Model Combination Approach: Michael O'Doherty N. E. Savin Ashish TiwariTarun SharmaNoch keine Bewertungen
- SAPM1Dokument5 SeitenSAPM1Shaan MahendraNoch keine Bewertungen
- EDHEC WhyBeatingTheMarketIsEasyDokument19 SeitenEDHEC WhyBeatingTheMarketIsEasyachmadtabaNoch keine Bewertungen
- Ratio AnalysisDokument34 SeitenRatio AnalysisChandan Srivastava100% (3)
- Evaluating Mutual Fund PerformanceDokument34 SeitenEvaluating Mutual Fund PerformanceAhmad Ismail HamdaniNoch keine Bewertungen
- Testing Density Forecasts, With Applications To Risk ManagementDokument36 SeitenTesting Density Forecasts, With Applications To Risk ManagementLisa MajminNoch keine Bewertungen
- Markowitz in Tactical Asset AllocationDokument12 SeitenMarkowitz in Tactical Asset AllocationsoumensahilNoch keine Bewertungen
- Portfolio Management With Heuristic Optimization MaringerDokument237 SeitenPortfolio Management With Heuristic Optimization MaringerArushSinghNoch keine Bewertungen
- Back TestingDokument33 SeitenBack Testingalexbernal0Noch keine Bewertungen
- Literature On CapmDokument14 SeitenLiterature On CapmHitesh ParmarNoch keine Bewertungen
- Dissertation Topics On Efficient Market HypothesisDokument8 SeitenDissertation Topics On Efficient Market HypothesisHelpWithWritingAPaperCanada100% (1)
- SSRN Id4336419Dokument26 SeitenSSRN Id4336419brineshrimpNoch keine Bewertungen
- Probability of Backtest OverfitDokument34 SeitenProbability of Backtest Overfitalexbernal0Noch keine Bewertungen
- A Dea Comparison of Systematic and Lump Sum Investment in Mutual FundsDokument10 SeitenA Dea Comparison of Systematic and Lump Sum Investment in Mutual FundspramodppppNoch keine Bewertungen
- Research Methodology and Quantitative TechniquesDokument102 SeitenResearch Methodology and Quantitative TechniquesAnshu MishraNoch keine Bewertungen
- Literature Review CompletedDokument13 SeitenLiterature Review CompletedRaji SinghNoch keine Bewertungen
- Secrets of Statistical Data Analysis and Management Science!Von EverandSecrets of Statistical Data Analysis and Management Science!Noch keine Bewertungen
- All That Glitters Is Not Gold - Comparing Backtest and Out-of-Sample Performance On A Large Cohort oDokument19 SeitenAll That Glitters Is Not Gold - Comparing Backtest and Out-of-Sample Performance On A Large Cohort opderby1Noch keine Bewertungen
- Eliciting Expert Opinion in Acquisition Cost and Schedule Estimating.Dokument22 SeitenEliciting Expert Opinion in Acquisition Cost and Schedule Estimating.Joli SmithNoch keine Bewertungen
- Literature Review 2Dokument9 SeitenLiterature Review 2Hari Priya0% (1)
- Real OptionsDokument14 SeitenReal OptionsRayCharlesCloud100% (1)
- A Literature Study On The Capital Asset Pricing MoDokument5 SeitenA Literature Study On The Capital Asset Pricing Momarcel XNoch keine Bewertungen
- Acc Theory QuestionDokument10 SeitenAcc Theory QuestionZHI QI chanNoch keine Bewertungen
- Edhec Working Paper An Integrated Framework For Style F - 1436259458413Dokument10 SeitenEdhec Working Paper An Integrated Framework For Style F - 1436259458413Raju KaliperumalNoch keine Bewertungen
- ForecastingDokument18 SeitenForecastingNikita Verma0% (1)
- A Review of Empirical Analysis in Value InvestingDokument6 SeitenA Review of Empirical Analysis in Value Investingcupucuboh.buconecaqNoch keine Bewertungen
- Multi-Asset Scenario Building For Trend-Following Trading StrategiesDokument34 SeitenMulti-Asset Scenario Building For Trend-Following Trading StrategiespanazeliaNoch keine Bewertungen
- Price and Value: A Guide to Equity Market Valuation MetricsVon EverandPrice and Value: A Guide to Equity Market Valuation MetricsNoch keine Bewertungen
- Benchmark DissertationDokument7 SeitenBenchmark DissertationCustomPaperWritingUK100% (1)
- Literature Review of Modern Portfolio TheoryDokument6 SeitenLiterature Review of Modern Portfolio Theoryjhnljzbnd100% (1)
- Literature Review Capital Asset Pricing ModelDokument8 SeitenLiterature Review Capital Asset Pricing Modelafdtakoea100% (1)
- A New Approach To Comparing VaRDokument23 SeitenA New Approach To Comparing VaRAnneHumayraAnasNoch keine Bewertungen
- Backtesting: Current Version: October 4, 2014Dokument28 SeitenBacktesting: Current Version: October 4, 2014gammasyncNoch keine Bewertungen
- Business Plan HypothesisDokument8 SeitenBusiness Plan Hypothesisafcnzfamt100% (2)
- SSRN Id2126478Dokument38 SeitenSSRN Id2126478nghks1Noch keine Bewertungen
- Investment AnalysisDokument9 SeitenInvestment AnalysisEric AwinoNoch keine Bewertungen
- Market Timing With Moving Averages: SSRN Electronic Journal November 2012Dokument40 SeitenMarket Timing With Moving Averages: SSRN Electronic Journal November 20124nagNoch keine Bewertungen
- Part 6: Evaluating Tools: The Tool Must Be AccurateDokument9 SeitenPart 6: Evaluating Tools: The Tool Must Be AccurateRabi ShankarNoch keine Bewertungen
- How The PowerFactors Microcaps Portfolio Works - Seeking AlphaDokument8 SeitenHow The PowerFactors Microcaps Portfolio Works - Seeking Alphaalexbernal0Noch keine Bewertungen
- First-Half FUBAR - Stocks Worst in 60 Years, Bonds & Bitcoin Worst Ever - ZeroHedgeDokument19 SeitenFirst-Half FUBAR - Stocks Worst in 60 Years, Bonds & Bitcoin Worst Ever - ZeroHedgealexbernal0Noch keine Bewertungen
- Risk-On, Risk Off, Revisited - Jay On The MarketsDokument6 SeitenRisk-On, Risk Off, Revisited - Jay On The Marketsalexbernal0Noch keine Bewertungen
- PP Investor Day 2021 Combined FINALDokument67 SeitenPP Investor Day 2021 Combined FINALalexbernal0Noch keine Bewertungen
- PV Crossovers - Parallax Financial ResearchDokument8 SeitenPV Crossovers - Parallax Financial Researchalexbernal0Noch keine Bewertungen
- A Bullish Signal For SPDR S&P 500 (NYSEARCA - SPY) - Seeking AlphaDokument9 SeitenA Bullish Signal For SPDR S&P 500 (NYSEARCA - SPY) - Seeking Alphaalexbernal0Noch keine Bewertungen
- Hong Kong Stocks May 7 Parallax SignalsDokument6 SeitenHong Kong Stocks May 7 Parallax Signalsalexbernal0Noch keine Bewertungen
- STOXX 600 ExtremeHurst Signals May 30 2016Dokument5 SeitenSTOXX 600 ExtremeHurst Signals May 30 2016alexbernal0Noch keine Bewertungen
- Parallax Predictor Testing MethodsDokument23 SeitenParallax Predictor Testing MethodsAlex BernalNoch keine Bewertungen
- Bombay Sensex Extreme Hurst Signals May 7Dokument5 SeitenBombay Sensex Extreme Hurst Signals May 7alexbernal0Noch keine Bewertungen
- Aether Gaviota Options VII StrategyDokument9 SeitenAether Gaviota Options VII Strategyalexbernal0100% (1)
- Backtest OverFittingDokument58 SeitenBacktest OverFittingalexbernal0Noch keine Bewertungen
- Back TestingDokument33 SeitenBack Testingalexbernal0Noch keine Bewertungen
- Deflated Sharpe RatioDokument22 SeitenDeflated Sharpe Ratioalexbernal0Noch keine Bewertungen
- Back TestingDokument33 SeitenBack Testingalexbernal0Noch keine Bewertungen
- Probability of Backtest OverfitDokument34 SeitenProbability of Backtest Overfitalexbernal0Noch keine Bewertungen
- How To Evaluate Trading SystemsDokument19 SeitenHow To Evaluate Trading Systemsalexbernal0Noch keine Bewertungen
- Running Head: HR ANALYTICS 1Dokument7 SeitenRunning Head: HR ANALYTICS 1DenizNoch keine Bewertungen
- Introductory Statistics With RDokument84 SeitenIntroductory Statistics With RTamim IqbalNoch keine Bewertungen
- Nursing Research Chapter 4: Types of Research ReportDokument5 SeitenNursing Research Chapter 4: Types of Research ReportSupriadi74Noch keine Bewertungen
- Introduction To Study Skills and Research Methods: Unit Leader: DR James BettsDokument15 SeitenIntroduction To Study Skills and Research Methods: Unit Leader: DR James BettsJhazmine OmaoengNoch keine Bewertungen
- Regression EquationDokument56 SeitenRegression EquationMuhammad TariqNoch keine Bewertungen
- Lab2b 2022 LDokument19 SeitenLab2b 2022 LNguyễn HiếuNoch keine Bewertungen
- A2 Math C3 DoneDokument53 SeitenA2 Math C3 DoneWuileapNoch keine Bewertungen
- Inverse-Gamma DistributionDokument4 SeitenInverse-Gamma Distributionkeisha555Noch keine Bewertungen
- Skittles AssignmentDokument8 SeitenSkittles Assignmentapi-291800396Noch keine Bewertungen
- Cheryl reyes-ACTIVITYDokument4 SeitenCheryl reyes-ACTIVITYCheryl ReyesNoch keine Bewertungen
- Probability: An Introduction To Modeling UncertaintyDokument98 SeitenProbability: An Introduction To Modeling UncertaintyjoseNoch keine Bewertungen
- Industrial Quality Control-Chapter 3-Merlina Fitri A.Dokument11 SeitenIndustrial Quality Control-Chapter 3-Merlina Fitri A.Irfan BakhtiarNoch keine Bewertungen
- 08 Problem Solving 1-PrefinalsDokument4 Seiten08 Problem Solving 1-PrefinalsGrace AndagNoch keine Bewertungen
- Use of Computer in Data AnalysisDokument48 SeitenUse of Computer in Data AnalysisHardeep KaurNoch keine Bewertungen
- Independent T-Test Using SPSSDokument6 SeitenIndependent T-Test Using SPSSGazal GuptaNoch keine Bewertungen
- Irt vs. CTTDokument4 SeitenIrt vs. CTTPacleb, Abema Joy V.Noch keine Bewertungen
- STAT 3001/7301: Mathematical Statistics: Week 3 - Lecture 8Dokument20 SeitenSTAT 3001/7301: Mathematical Statistics: Week 3 - Lecture 8Li NguyenNoch keine Bewertungen
- Awareness Towards Implementation of Solid Waste Management in The Coastal AreaDokument22 SeitenAwareness Towards Implementation of Solid Waste Management in The Coastal AreaCelmer100% (1)
- Measures of Dispersion 2.Dokument11 SeitenMeasures of Dispersion 2.deyaNoch keine Bewertungen
- Unit 8 TextbookDokument47 SeitenUnit 8 TextbookSteve Bishop0% (2)
- Quantitative & Qualitative ResearchDokument17 SeitenQuantitative & Qualitative ResearchMelvinNoch keine Bewertungen
- Young 2003 - Enhancing Learning Outcomes - The Effects of Instructional Technology, Learning Styles, Instructional Methods and Studen BehaviorDokument14 SeitenYoung 2003 - Enhancing Learning Outcomes - The Effects of Instructional Technology, Learning Styles, Instructional Methods and Studen BehaviorkambudurNoch keine Bewertungen
- Glossary: Instructor'S Manual Powerpoint Presentations Eztest Test Bank Spss Data SetsDokument12 SeitenGlossary: Instructor'S Manual Powerpoint Presentations Eztest Test Bank Spss Data SetsHANG NGUYEN KIMNoch keine Bewertungen
- Problem 1: Linear RegressionDokument14 SeitenProblem 1: Linear RegressionVijayalakshmi Palaniappan50% (12)
- Multivariate Statistical Analysis: Old SchoolDokument319 SeitenMultivariate Statistical Analysis: Old SchoolVivek11Noch keine Bewertungen
- Stability of Money Demand in An Emerging Market Economy: An Error Correction and ARDL Model For IndonesiaDokument9 SeitenStability of Money Demand in An Emerging Market Economy: An Error Correction and ARDL Model For Indonesiaahmad_subhan1832Noch keine Bewertungen
- Gujarat Technological UniversityDokument3 SeitenGujarat Technological University20IT003 Dharmik VanpariyaNoch keine Bewertungen
- Convergence of Random VariablesDokument7 SeitenConvergence of Random Variablesdaniel656Noch keine Bewertungen
- Growth Curve Analysis in RDokument33 SeitenGrowth Curve Analysis in RJosé Murilo Costa SilvaNoch keine Bewertungen
- Geographically Weighted Logistic RegressionDokument6 SeitenGeographically Weighted Logistic RegressionYe GeNoch keine Bewertungen