Das könnte Ihnen auch gefallen
- Introduction To Data ScienceDokument74 SeitenIntroduction To Data ScienceMichael Wee75% (4)
- STAT121 / AC209 / E-109: CS109 Data ScienceDokument74 SeitenSTAT121 / AC209 / E-109: CS109 Data ScienceMatheus SilvaNoch keine Bewertungen
- Data Warehousing: Lecture No 01Dokument33 SeitenData Warehousing: Lecture No 01Anonymous I3Ath48dNoch keine Bewertungen
- Introduction To Data VisualizationDokument28 SeitenIntroduction To Data VisualizationMuhammad ZuhairuddinNoch keine Bewertungen
- COGS9 SyllabusDokument3 SeitenCOGS9 SyllabusantsereneNoch keine Bewertungen
- Introduction To Data Science: Dan Potter Carsten Binnig Eli Upfal Tim KraskaDokument71 SeitenIntroduction To Data Science: Dan Potter Carsten Binnig Eli Upfal Tim Kraskaanon_621996886Noch keine Bewertungen
- Intro To Data Science With DBDokument33 SeitenIntro To Data Science With DBSoumya Kanti ChakrabortyNoch keine Bewertungen
- Data Science ApplicationsDokument25 SeitenData Science ApplicationsVitorNoch keine Bewertungen
- Introduction To Data Science: For-Ian V. Sandoval Asst. Professor II Laguna State Polytechnic UniversityDokument62 SeitenIntroduction To Data Science: For-Ian V. Sandoval Asst. Professor II Laguna State Polytechnic Universitymaroua aouadiNoch keine Bewertungen
- IDS1 IntroductionDokument27 SeitenIDS1 IntroductionT DoNoch keine Bewertungen
- Data Science: Principles and Practice: Lecture 1: IntroductionDokument36 SeitenData Science: Principles and Practice: Lecture 1: IntroductionYoussef AbdalnabyNoch keine Bewertungen
- PP - Hong Qu Data Visualization Workshop HKS Fall 2021Dokument27 SeitenPP - Hong Qu Data Visualization Workshop HKS Fall 2021Luis CarvajalNoch keine Bewertungen
- Introduction To Data ScienceDokument16 SeitenIntroduction To Data ScienceTopo ChandraNoch keine Bewertungen
- Chess AI Base PaperDokument7 SeitenChess AI Base PaperEchizen RyomaNoch keine Bewertungen
- Libro Azul de ApproDokument46 SeitenLibro Azul de ApproEduard MartiNoch keine Bewertungen
- KIT306/606: Data Analytics Unit Coordinator: A/Prof. Quan Bai University of TasmaniaDokument51 SeitenKIT306/606: Data Analytics Unit Coordinator: A/Prof. Quan Bai University of TasmaniaJason ZengNoch keine Bewertungen
- Data Science: What Is Data Science and Who Is Data ScientistDokument26 SeitenData Science: What Is Data Science and Who Is Data ScientistZaib KhanNoch keine Bewertungen
- IDS Sec-1 CS1-CS8 Merged SlidesDokument419 SeitenIDS Sec-1 CS1-CS8 Merged Slidessourab jainNoch keine Bewertungen
- Prepare Your Data for Tableau: A Practical Guide to the Tableau Data Prep ToolVon EverandPrepare Your Data for Tableau: A Practical Guide to the Tableau Data Prep ToolNoch keine Bewertungen
- Introduction & Data Science PlatformsDokument31 SeitenIntroduction & Data Science PlatformsnaldoNoch keine Bewertungen
- To Data Science: Prof. Padmavati SarodeDokument61 SeitenTo Data Science: Prof. Padmavati SarodeJane ridriguezNoch keine Bewertungen
- AI Intro Cmu - EduDokument25 SeitenAI Intro Cmu - EduDanielNoch keine Bewertungen
- Unit I Introduction To Data ScienceDokument79 SeitenUnit I Introduction To Data ScienceJaydeep DodiyaNoch keine Bewertungen
- Blue Ribon Task Force Final ReportDokument116 SeitenBlue Ribon Task Force Final Reportalvaro malagutiNoch keine Bewertungen
- Feedback From Last Class, Emails, Piazza Postings, EtcDokument22 SeitenFeedback From Last Class, Emails, Piazza Postings, EtcHarsh PatelNoch keine Bewertungen
- Data Science Overview NewDokument23 SeitenData Science Overview NewManish KumarNoch keine Bewertungen
- The Field Guide To Data Science 1673920642Dokument84 SeitenThe Field Guide To Data Science 1673920642Mariappan RNoch keine Bewertungen
- Computer Science For The Masses: Robert Sedgewick Princeton UniversityDokument50 SeitenComputer Science For The Masses: Robert Sedgewick Princeton University김형진Noch keine Bewertungen
- What Is Eresearch ProcterDokument33 SeitenWhat Is Eresearch ProcterTingoNoch keine Bewertungen
- What Is Data Science GDIDokument24 SeitenWhat Is Data Science GDISenka Anđelković0% (1)
- Data AnalysisDokument18 SeitenData AnalysisEng Ahmed OsmanNoch keine Bewertungen
- 0 IntroDokument28 Seiten0 IntroChirag KocharNoch keine Bewertungen
- Thesis Data MiningDokument7 SeitenThesis Data MiningPaySomeoneToWritePaperCanada100% (4)
- Getting Started With Data Science: Grade VIIIDokument32 SeitenGetting Started With Data Science: Grade VIIIPriyansu PratapNoch keine Bewertungen
- Data Science Intro MulawarmanDokument89 SeitenData Science Intro Mulawarmanmade anggaNoch keine Bewertungen
- Online Learning For Big Data AnalyticsDokument116 SeitenOnline Learning For Big Data AnalyticsWarren Smith QC (Quantum Cryptanalyst)Noch keine Bewertungen
- Data Science-1Dokument65 SeitenData Science-1BasavarajuNoch keine Bewertungen
- LLS A of Expertise: SKI AREDokument2 SeitenLLS A of Expertise: SKI AREKyu ChoNoch keine Bewertungen
- Data Science 1ADokument53 SeitenData Science 1AkagomeNoch keine Bewertungen
- Exploratory Data AnalysisDokument104 SeitenExploratory Data AnalysisSASIKUMAR BNoch keine Bewertungen
- Data Analysis: What Can Be Learned From the Past 50 YearsVon EverandData Analysis: What Can Be Learned From the Past 50 YearsNoch keine Bewertungen
- Survive or Thrive AgendaDokument4 SeitenSurvive or Thrive AgendajukesieNoch keine Bewertungen
- CS583 Chapter 1 IntroductionDokument22 SeitenCS583 Chapter 1 IntroductionKunal DeoreNoch keine Bewertungen
- Data Science To Do From Quora PostsDokument4 SeitenData Science To Do From Quora PostsNilpa JhaNoch keine Bewertungen
- What Is Data ScienceDokument4 SeitenWhat Is Data ScienceArtatrana DashNoch keine Bewertungen
- 01 00intro 2x2Dokument4 Seiten01 00intro 2x2HyunJong LeeNoch keine Bewertungen
- Introduction To Data Science Interactive Visualization: CS 194 Fall 2015 John CannyDokument65 SeitenIntroduction To Data Science Interactive Visualization: CS 194 Fall 2015 John Cannyankit_malikair2009Noch keine Bewertungen
- Basics of Data LiteracyDokument33 SeitenBasics of Data LiteracyJULIENoch keine Bewertungen
- Financial Cryptography and Data Security 2005Dokument386 SeitenFinancial Cryptography and Data Security 2005Saurabh AdeNoch keine Bewertungen
- DM Lecture 1 Introudction and PoliciesDokument17 SeitenDM Lecture 1 Introudction and PoliciesFaizad UllahNoch keine Bewertungen
- Data Science Solutions on Azure: Tools and Techniques Using Databricks and MLOpsVon EverandData Science Solutions on Azure: Tools and Techniques Using Databricks and MLOpsNoch keine Bewertungen
- Data ScienceDokument85 SeitenData SciencesriharinecgNoch keine Bewertungen
- Data ScienceDokument87 SeitenData Sciencetha9s9catal9Noch keine Bewertungen
- Deductive and Object-Oriented Databases: Proceedings of the First International Conference on Deductive and Object-Oriented Databases (DOOD89) Kyoto Research Park, Kyoto, Japan, 4-6 December 1989Von EverandDeductive and Object-Oriented Databases: Proceedings of the First International Conference on Deductive and Object-Oriented Databases (DOOD89) Kyoto Research Park, Kyoto, Japan, 4-6 December 1989Noch keine Bewertungen
- Resume - George A. MihailaDokument9 SeitenResume - George A. Mihailagamihaila100% (2)
- IT Intro - IntroductionDokument21 SeitenIT Intro - IntroductionSha EemNoch keine Bewertungen
- PHD Thesis Topics in Image ProcessingDokument6 SeitenPHD Thesis Topics in Image Processingafcnahwvk100% (2)
- Big Data 101Dokument32 SeitenBig Data 101anjanasundaramNoch keine Bewertungen
- Slide 1 - CSE 564 IntroDokument57 SeitenSlide 1 - CSE 564 IntroRahul VenkatNoch keine Bewertungen
- 16 L 3 ResolutionDokument82 Seiten16 L 3 ResolutionRahul VenkatNoch keine Bewertungen
- Yelp Business Rating PredictionDokument8 SeitenYelp Business Rating PredictionRahul VenkatNoch keine Bewertungen
- Sujeet's Milli Blog - 7 Lessons I Learnt During Facebook InternshipDokument7 SeitenSujeet's Milli Blog - 7 Lessons I Learnt During Facebook InternshipRahul VenkatNoch keine Bewertungen
- Sujeet's Milli Blog - Internship at Facebook.Dokument8 SeitenSujeet's Milli Blog - Internship at Facebook.Rahul VenkatNoch keine Bewertungen
- Hackamonth - Mixing Things UpDokument2 SeitenHackamonth - Mixing Things UpRahul VenkatNoch keine Bewertungen
- Std10 EnglishDokument196 SeitenStd10 EnglishRahul VenkatNoch keine Bewertungen
- Saudi Aramco Inspection ChecklistDokument3 SeitenSaudi Aramco Inspection ChecklistManoj KumarNoch keine Bewertungen
- Serial NumberDokument3 SeitenSerial NumberNidal Nakhalah67% (3)
- Community Needs Assessments and Sample QuestionaireDokument16 SeitenCommunity Needs Assessments and Sample QuestionaireLemuel C. Fernandez100% (2)
- Reynolds EqnDokument27 SeitenReynolds EqnSuman KhanalNoch keine Bewertungen
- DLS RSeriesManual PDFDokument9 SeitenDLS RSeriesManual PDFdanysan2525Noch keine Bewertungen
- B777 ChecklistDokument2 SeitenB777 ChecklistMarkus Schütz100% (1)
- Transition SignalsDokument10 SeitenTransition Signalshana nixmaNoch keine Bewertungen
- Resolume Arena DMX Auto Map SheetDokument8 SeitenResolume Arena DMX Auto Map SheetAdolfo GonzalezNoch keine Bewertungen
- Training BookletDokument20 SeitenTraining BookletMohamedAliJlidiNoch keine Bewertungen
- CatalogDokument42 SeitenCatalogOnerom LeuhanNoch keine Bewertungen
- 1 Calibrating The Venturi Meter and Orifice MeterDokument5 Seiten1 Calibrating The Venturi Meter and Orifice MeterRaghavanNoch keine Bewertungen
- The Impact of Greed On Academic Medicine and Patient CareDokument5 SeitenThe Impact of Greed On Academic Medicine and Patient CareBhawana Prashant AgrawalNoch keine Bewertungen
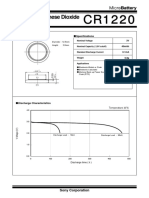
- Sony CR1220 PDFDokument2 SeitenSony CR1220 PDFdiego742000Noch keine Bewertungen
- View/Update Profile Apply For STC: Upload Sponsorship STC Applied Download Certificate Change PasswordDokument2 SeitenView/Update Profile Apply For STC: Upload Sponsorship STC Applied Download Certificate Change PasswordlakshmilavanyaNoch keine Bewertungen
- AIX PowerHA (HACMP) CommandsDokument3 SeitenAIX PowerHA (HACMP) CommandsdanilaixNoch keine Bewertungen
- E85005-0126 - FireShield Plus Conventional Fire Alarm Systems PDFDokument8 SeitenE85005-0126 - FireShield Plus Conventional Fire Alarm Systems PDFLuis TovarNoch keine Bewertungen
- Seguridad en Reactores de Investigación PDFDokument152 SeitenSeguridad en Reactores de Investigación PDFJorge PáezNoch keine Bewertungen
- Analyzing and Securing Social Media: Cloud-Based Assured Information SharingDokument36 SeitenAnalyzing and Securing Social Media: Cloud-Based Assured Information SharingakrmbaNoch keine Bewertungen
- Stock Market Lesson PlanDokument4 SeitenStock Market Lesson PlanWilliam BaileyNoch keine Bewertungen
- Generic Roadmap For The Counties of Kenya V1.1Dokument33 SeitenGeneric Roadmap For The Counties of Kenya V1.1ICT AUTHORITYNoch keine Bewertungen
- 1 Chapter1 Introduction V5.5a1Dokument13 Seiten1 Chapter1 Introduction V5.5a1Alejandro LaraNoch keine Bewertungen
- Kumbh Mela 2019 Presentation Mela AuthorityDokument35 SeitenKumbh Mela 2019 Presentation Mela AuthorityBanibrataChoudhuryNoch keine Bewertungen
- Grade 7 and 8 November NewsletterDokument1 SeiteGrade 7 and 8 November Newsletterapi-296332562Noch keine Bewertungen
- Eurotherm 2604 PDFDokument2 SeitenEurotherm 2604 PDFLorena100% (1)
- 01 SQL ErrorsDokument2.085 Seiten01 SQL ErrorsM. temNoch keine Bewertungen
- WordFamilySorts 1Dokument38 SeitenWordFamilySorts 1Karen simpsonNoch keine Bewertungen
- Profile of The Aerospace Industry in Greater MontrealDokument48 SeitenProfile of The Aerospace Industry in Greater Montrealvigneshkumar rajanNoch keine Bewertungen
- Android VersionsDokument7 SeitenAndroid VersionsEdna Mae Salas GarciaNoch keine Bewertungen
- Gudenaaparken (Randers) - All You Need To Know BEFORE You GoDokument8 SeitenGudenaaparken (Randers) - All You Need To Know BEFORE You GoElaine Zarb GiorgioNoch keine Bewertungen
- CS467-textbook-Machine Learning-Ktustudents - in PDFDokument226 SeitenCS467-textbook-Machine Learning-Ktustudents - in PDFAmmu MoleNoch keine Bewertungen