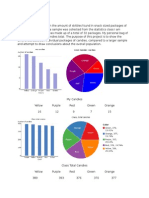
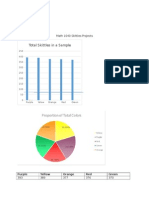
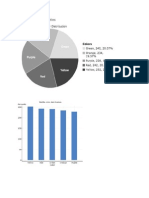
Das könnte Ihnen auch gefallen
- Final Math ProjectDokument7 SeitenFinal Math Projectapi-316775963Noch keine Bewertungen
- Math 1040 Skittles Term ProjectDokument9 SeitenMath 1040 Skittles Term Projectapi-319881085Noch keine Bewertungen
- Skittles Project FinalDokument5 SeitenSkittles Project Finalapi-271348941Noch keine Bewertungen
- Skittles ProjectDokument9 SeitenSkittles Projectapi-242873849Noch keine Bewertungen
- The Skittles Project FinalDokument8 SeitenThe Skittles Project Finalapi-316760667Noch keine Bewertungen
- Statistics Term Project E-Portfolio ReflectionDokument8 SeitenStatistics Term Project E-Portfolio Reflectionapi-258147701Noch keine Bewertungen
- Skittles ProDokument9 SeitenSkittles Proapi-241124972Noch keine Bewertungen
- SkittlesdataclassprojectDokument8 SeitenSkittlesdataclassprojectapi-399586872Noch keine Bewertungen
- Final ProjectDokument9 SeitenFinal Projectapi-262329757Noch keine Bewertungen
- The Rainbow ReportDokument11 SeitenThe Rainbow Reportapi-316991888Noch keine Bewertungen
- Skittles ProjectDokument6 SeitenSkittles Projectapi-319345408Noch keine Bewertungen
- Final ProjectDokument6 SeitenFinal Projectapi-283261340Noch keine Bewertungen
- Statistics Project 17Dokument13 SeitenStatistics Project 17api-271978152Noch keine Bewertungen
- Skittles Project 1Dokument7 SeitenSkittles Project 1api-299868669100% (2)
- Term Project - EportfolioDokument7 SeitenTerm Project - Eportfolioapi-251981709Noch keine Bewertungen
- Skittles Project Stats 1040Dokument8 SeitenSkittles Project Stats 1040api-301336765Noch keine Bewertungen
- Skittles FinalDokument12 SeitenSkittles Finalapi-241861434Noch keine Bewertungen
- Term Project ReportDokument9 SeitenTerm Project Reportapi-238585685Noch keine Bewertungen
- Math 1040 Term ProjectDokument7 SeitenMath 1040 Term Projectapi-340188424Noch keine Bewertungen
- Reflection and EportfolioDokument8 SeitenReflection and Eportfolioapi-252747849Noch keine Bewertungen
- Math 1040 Final ProjectDokument3 SeitenMath 1040 Final Projectapi-285380759Noch keine Bewertungen
- Skittles Proyect Part 5Dokument7 SeitenSkittles Proyect Part 5api-509398997Noch keine Bewertungen
- Skittles ProjectDokument9 SeitenSkittles Projectapi-252747849Noch keine Bewertungen
- Dulces Math 1040Dokument6 SeitenDulces Math 1040api-242193187Noch keine Bewertungen
- Skittles AssignmentDokument8 SeitenSkittles Assignmentapi-291800396Noch keine Bewertungen
- Stats ProjectDokument14 SeitenStats Projectapi-302666758Noch keine Bewertungen
- Skittles Project With ReflectionDokument7 SeitenSkittles Project With Reflectionapi-234712126100% (1)
- Skittle Pareto ChartDokument7 SeitenSkittle Pareto Chartapi-272391081Noch keine Bewertungen
- StatsfinalprojectDokument7 SeitenStatsfinalprojectapi-325102852Noch keine Bewertungen
- Croot Part6 EportfolioDokument16 SeitenCroot Part6 Eportfolioapi-276896975Noch keine Bewertungen
- Skittles Term Project - Kai Galbiso Stat1040Dokument6 SeitenSkittles Term Project - Kai Galbiso Stat1040api-316758771Noch keine Bewertungen
- TP 2 StatsDokument5 SeitenTP 2 Statsapi-240850453Noch keine Bewertungen
- Emily Gregorio Skittles Project FinalDokument3 SeitenEmily Gregorio Skittles Project Finalapi-288933258Noch keine Bewertungen
- EportfolioDokument8 SeitenEportfolioapi-242211470Noch keine Bewertungen
- Math 1040 Skittles Term Project EportfolioDokument7 SeitenMath 1040 Skittles Term Project Eportfolioapi-260817278Noch keine Bewertungen
- Skittles Project Math 1040Dokument8 SeitenSkittles Project Math 1040api-495044194Noch keine Bewertungen
- Math 1030 Skittles Term ProjectDokument8 SeitenMath 1030 Skittles Term Projectapi-340538273Noch keine Bewertungen
- Math 1040 ProjectDokument8 SeitenMath 1040 Projectapi-388517702Noch keine Bewertungen
- Group Project #1 - SkittlesDokument9 SeitenGroup Project #1 - Skittlesapi-245266056Noch keine Bewertungen
- The Full Skittles ProjectDokument6 SeitenThe Full Skittles Projectapi-340271527100% (1)
- Math 1040 Skittles Term ProjectDokument10 SeitenMath 1040 Skittles Term Projectapi-310671451Noch keine Bewertungen
- Skittles 2 FinalDokument12 SeitenSkittles 2 Finalapi-242194552Noch keine Bewertungen
- Kassem Hajj: Math 1040 Skittles Term ProjectDokument10 SeitenKassem Hajj: Math 1040 Skittles Term Projectapi-240347922Noch keine Bewertungen
- EportfolioDokument12 SeitenEportfolioapi-251934892Noch keine Bewertungen
- Skittles ProjectDokument5 SeitenSkittles Projectapi-441660843Noch keine Bewertungen
- Skittles Term Project StatsDokument8 SeitenSkittles Term Project Statsapi-302549779Noch keine Bewertungen
- Skittles Term ProjectDokument10 SeitenSkittles Term Projectapi-273060240Noch keine Bewertungen
- Skittles Term Project 11 9 14Dokument5 SeitenSkittles Term Project 11 9 14api-192489685Noch keine Bewertungen
- Full Skittles ProjectDokument13 SeitenFull Skittles Projectapi-537189505Noch keine Bewertungen
- Skittles Project Group Final WordDokument6 SeitenSkittles Project Group Final Wordapi-316239273Noch keine Bewertungen
- Skittles Project 5-02Dokument8 SeitenSkittles Project 5-02api-354040698Noch keine Bewertungen
- Skittles WordDokument5 SeitenSkittles Wordapi-285645725Noch keine Bewertungen
- Final Stats ProjectDokument8 SeitenFinal Stats Projectapi-238717717100% (2)
- Term Project Part 7Dokument8 SeitenTerm Project Part 7api-291870758Noch keine Bewertungen
- Math 1040Dokument5 SeitenMath 1040api-534403229Noch keine Bewertungen
- Skittle Term ProjectDokument15 SeitenSkittle Term Projectapi-260271892Noch keine Bewertungen
- Math Skittles Term Project-1Dokument6 SeitenMath Skittles Term Project-1api-241771020Noch keine Bewertungen
- Math 1040Dokument3 SeitenMath 1040api-219553415Noch keine Bewertungen
- Quantitative Data AnalysisDokument44 SeitenQuantitative Data AnalysisObote DanielNoch keine Bewertungen
- Statistics For Linguistics With R: Stefan Th. GriesDokument512 SeitenStatistics For Linguistics With R: Stefan Th. GriesSergio Verdejo OlivaNoch keine Bewertungen
- Memon Et Al. - Moderation Analysis Issue Adn Guidelines PDFDokument11 SeitenMemon Et Al. - Moderation Analysis Issue Adn Guidelines PDFsaqib ghiasNoch keine Bewertungen
- 01 Handout 19Dokument3 Seiten01 Handout 19Цедіе РамосNoch keine Bewertungen
- Variables Answers ReasonsDokument4 SeitenVariables Answers ReasonsEDEN FE D. QUIAPONoch keine Bewertungen
- Chapter 11 Study Guide - Chi-SquareDokument16 SeitenChapter 11 Study Guide - Chi-SquareChengineNoch keine Bewertungen
- Defining The Domains and Approaches of Quantitative and Qualitative ResearchDokument11 SeitenDefining The Domains and Approaches of Quantitative and Qualitative ResearchDiogo LimaNoch keine Bewertungen
- Bwinter Stats ProofsDokument326 SeitenBwinter Stats ProofsPradyuman SharmaNoch keine Bewertungen
- Assignment 3 Research Methodlogy 20040621068 PDFDokument2 SeitenAssignment 3 Research Methodlogy 20040621068 PDFDyuthi KuchuNoch keine Bewertungen
- Data Pre-Processing Python For BeginnerDokument12 SeitenData Pre-Processing Python For BeginnerBongkar TaktikNoch keine Bewertungen
- Parenting and Family Adjustment Among Parents 14-20 PDFDokument7 SeitenParenting and Family Adjustment Among Parents 14-20 PDFIndian Journal of Psychiatric Social WorkNoch keine Bewertungen
- Lesson 2 The Importance of Quantitative Research Across FieldsDokument8 SeitenLesson 2 The Importance of Quantitative Research Across FieldsTrixie TorresNoch keine Bewertungen
- Chapter 01 Data and StatisticsDokument44 SeitenChapter 01 Data and StatisticsDieu TruongNoch keine Bewertungen
- Data Presentation and AnalysisDokument1 SeiteData Presentation and AnalysisOUMA ESTHERNoch keine Bewertungen
- Fit A Gaussian Process Regression (GPR) Model - MATLAB Fitrgp - MathWorks España PDFDokument10 SeitenFit A Gaussian Process Regression (GPR) Model - MATLAB Fitrgp - MathWorks España PDFingjojedaNoch keine Bewertungen
- Chapter 1 Introduction To Statistics PDFDokument161 SeitenChapter 1 Introduction To Statistics PDFThanes RawNoch keine Bewertungen
- How Much Data Does Google Handle?Dokument132 SeitenHow Much Data Does Google Handle?Karl Erol PasionNoch keine Bewertungen
- Slides - Module-2 - Lesson-6Dokument55 SeitenSlides - Module-2 - Lesson-6Abhishek SharmaNoch keine Bewertungen
- PPT2 Types and Classification of VariablesDokument13 SeitenPPT2 Types and Classification of VariablesMary De CastroNoch keine Bewertungen
- Practical File Of: "Research Methodology Lab"Dokument73 SeitenPractical File Of: "Research Methodology Lab"Sahil RajputNoch keine Bewertungen
- Chapter 13Dokument11 SeitenChapter 13Fanny Sylvia C.Noch keine Bewertungen
- Statistics: Data ManagementDokument22 SeitenStatistics: Data ManagementGritzen OdiasNoch keine Bewertungen
- Auto Insurance Fraud DetectionDokument27 SeitenAuto Insurance Fraud Detectionap1450ajayNoch keine Bewertungen
- 07 Data Management & AnalysisDokument20 Seiten07 Data Management & AnalysisMahmoud FarahNoch keine Bewertungen
- Multilevel Analysis Association of Soil Transmitted Helminths and Stunting in Children Aged 6-12 Years Old in Pinrang District, South SulawesiDokument12 SeitenMultilevel Analysis Association of Soil Transmitted Helminths and Stunting in Children Aged 6-12 Years Old in Pinrang District, South SulawesiVania Petrina CalistaNoch keine Bewertungen
- TwoStep Cluster AnalysisDokument19 SeitenTwoStep Cluster Analysisana santosNoch keine Bewertungen
- INF30036 DataTypes Lecture2-1Dokument42 SeitenINF30036 DataTypes Lecture2-1Yehan AbayasingheNoch keine Bewertungen
- Chi SquareDokument15 SeitenChi SquareAllan DizonNoch keine Bewertungen
- Introduction To CRISP DM Framework For Data Science and Machine LearningDokument7 SeitenIntroduction To CRISP DM Framework For Data Science and Machine LearningrameshsripadaNoch keine Bewertungen
- Analysis of Variance (Anova) F-Test: C H A P T E R 9Dokument26 SeitenAnalysis of Variance (Anova) F-Test: C H A P T E R 9Algin ManglicmotNoch keine Bewertungen
- ParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)Von EverandParaPro Assessment Preparation 2023-2024: Study Guide with 300 Practice Questions and Answers for the ETS Praxis Test (Paraprofessional Exam Prep)Noch keine Bewertungen
- Basic Math & Pre-Algebra Workbook For Dummies with Online PracticeVon EverandBasic Math & Pre-Algebra Workbook For Dummies with Online PracticeBewertung: 4 von 5 Sternen4/5 (2)
- Build a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Von EverandBuild a Mathematical Mind - Even If You Think You Can't Have One: Become a Pattern Detective. Boost Your Critical and Logical Thinking Skills.Bewertung: 5 von 5 Sternen5/5 (1)
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsVon EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsBewertung: 4.5 von 5 Sternen4.5/5 (3)
- Images of Mathematics Viewed Through Number, Algebra, and GeometryVon EverandImages of Mathematics Viewed Through Number, Algebra, and GeometryNoch keine Bewertungen
- Mathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingVon EverandMathematical Mindsets: Unleashing Students' Potential through Creative Math, Inspiring Messages and Innovative TeachingBewertung: 4.5 von 5 Sternen4.5/5 (21)
- Calculus Workbook For Dummies with Online PracticeVon EverandCalculus Workbook For Dummies with Online PracticeBewertung: 3.5 von 5 Sternen3.5/5 (8)
- Fluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldVon EverandFluent in 3 Months: How Anyone at Any Age Can Learn to Speak Any Language from Anywhere in the WorldBewertung: 3 von 5 Sternen3/5 (80)
- Mental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)Von EverandMental Math: How to Develop a Mind for Numbers, Rapid Calculations and Creative Math Tricks (Including Special Speed Math for SAT, GMAT and GRE Students)Noch keine Bewertungen
- Who Tells the Truth?: Collection of Logical Puzzles to Make You ThinkVon EverandWho Tells the Truth?: Collection of Logical Puzzles to Make You ThinkBewertung: 5 von 5 Sternen5/5 (1)
- How Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsVon EverandHow Math Explains the World: A Guide to the Power of Numbers, from Car Repair to Modern PhysicsBewertung: 3.5 von 5 Sternen3.5/5 (9)
- A Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathVon EverandA Guide to Success with Math: An Interactive Approach to Understanding and Teaching Orton Gillingham MathBewertung: 5 von 5 Sternen5/5 (1)
- Transform Your 6-12 Math Class: Digital Age Tools to Spark LearningVon EverandTransform Your 6-12 Math Class: Digital Age Tools to Spark LearningNoch keine Bewertungen
- Magic Multiplication: Discover the Ultimate Formula for Fast MultiplicationVon EverandMagic Multiplication: Discover the Ultimate Formula for Fast MultiplicationNoch keine Bewertungen