Das könnte Ihnen auch gefallen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5782)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (587)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (890)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (72)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (265)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2219)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (119)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Salting-Out Crystallisation Using NH Ina Laboratory-Scale Gas Lift ReactorDokument10 SeitenSalting-Out Crystallisation Using NH Ina Laboratory-Scale Gas Lift ReactorChester LowreyNoch keine Bewertungen
- Teamcenter 10.1 Business Modeler IDE Guide PLM00071 J PDFDokument1.062 SeitenTeamcenter 10.1 Business Modeler IDE Guide PLM00071 J PDFcad cad100% (1)
- Bildiri Sunum - 02Dokument12 SeitenBildiri Sunum - 02Orhan Veli KazancıNoch keine Bewertungen
- Please Note That Cypress Is An Infineon Technologies CompanyDokument22 SeitenPlease Note That Cypress Is An Infineon Technologies Company20c552244bNoch keine Bewertungen
- I-Plan Marketing List On Installments 11-Aug-23Dokument10 SeitenI-Plan Marketing List On Installments 11-Aug-23HuxaifaNoch keine Bewertungen
- Plastic RecyclingDokument14 SeitenPlastic RecyclingLevitaNoch keine Bewertungen
- Sujit Kumar Rout, Rupashree Ragini Sahoo, Soumya Ranjan Satapathy, Barada Prasad SethyDokument7 SeitenSujit Kumar Rout, Rupashree Ragini Sahoo, Soumya Ranjan Satapathy, Barada Prasad SethyPrabu ThannasiNoch keine Bewertungen
- Xbox - RGH E Ltu: Jogo 3.0 4.0 HD NºDokument11 SeitenXbox - RGH E Ltu: Jogo 3.0 4.0 HD NºGabriel DinhaNoch keine Bewertungen
- EM24DINDSDokument14 SeitenEM24DINDSJavaprima Dinamika AbadiNoch keine Bewertungen
- Corporations Defined and FormedDokument16 SeitenCorporations Defined and FormedSheryn Mae AlinNoch keine Bewertungen
- LAB-Histopath Midterms 01Dokument5 SeitenLAB-Histopath Midterms 01Jashmine May TadinaNoch keine Bewertungen
- Project Proposal ApprovedDokument2 SeitenProject Proposal ApprovedRonnel BechaydaNoch keine Bewertungen
- Physical GEOGRAPHY - TIEDokument432 SeitenPhysical GEOGRAPHY - TIEnassorussi9Noch keine Bewertungen
- Dermatitis Venenata Donald UDokument5 SeitenDermatitis Venenata Donald UIndahPertiwiNoch keine Bewertungen
- User Interface Analysis and Design TrendsDokument38 SeitenUser Interface Analysis and Design TrendsArbaz AliNoch keine Bewertungen
- Manual Cisco - DPC3925Dokument106 SeitenManual Cisco - DPC3925HábnerTeixeiraCostaNoch keine Bewertungen
- Komatsu PC01-1 (JPN) 14001-Up Shop ManualDokument217 SeitenKomatsu PC01-1 (JPN) 14001-Up Shop Manualhaimay118100% (2)
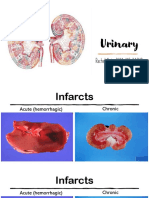
- Urinary: Rachel Neto, DVM, MS, DACVP May 28 2020Dokument15 SeitenUrinary: Rachel Neto, DVM, MS, DACVP May 28 2020Rachel AutranNoch keine Bewertungen
- MCQ InflationDokument6 SeitenMCQ Inflationashsalvi100% (4)
- Hiata 2Dokument21 SeitenHiata 2AnnJenn AsideraNoch keine Bewertungen
- A Psychologist Explains Why Everyone Is Suddenly On TiktokDokument3 SeitenA Psychologist Explains Why Everyone Is Suddenly On TiktokImen ImenNoch keine Bewertungen
- The Government-Created Subprime Mortgage Meltdown by Thomas DiLorenzoDokument3 SeitenThe Government-Created Subprime Mortgage Meltdown by Thomas DiLorenzodavid rockNoch keine Bewertungen
- Chapter 2 ResearchDokument14 SeitenChapter 2 ResearchabibualNoch keine Bewertungen
- SC WD 1 WashHandsFlyerFormatted JacobHahn Report 1Dokument3 SeitenSC WD 1 WashHandsFlyerFormatted JacobHahn Report 1jackson leeNoch keine Bewertungen
- Mercado - 10 Fabrikam Investments SolutionDokument3 SeitenMercado - 10 Fabrikam Investments SolutionMila MercadoNoch keine Bewertungen
- Knife Gate ValveDokument67 SeitenKnife Gate Valvekrishna100% (1)
- Lecture Notes On Revaluation and Impairment PDFDokument6 SeitenLecture Notes On Revaluation and Impairment PDFjudel ArielNoch keine Bewertungen
- Combined LoadingsDokument23 SeitenCombined LoadingsVinaasha BalakrishnanNoch keine Bewertungen
- Homework No1. Kenner Pérez TurizoDokument6 SeitenHomework No1. Kenner Pérez TurizoKenner PérezNoch keine Bewertungen
- The Minecraft Survival Quest ChallengeDokument4 SeitenThe Minecraft Survival Quest Challengeapi-269630780100% (1)