Das könnte Ihnen auch gefallen
- 6wind Support Intel DPDK PresentationDokument40 Seiten6wind Support Intel DPDK PresentationHuang Changhan100% (1)
- Intro To IxNetwork Feb 2012Dokument207 SeitenIntro To IxNetwork Feb 2012Brent Taira100% (1)
- Advanced C Programming: Gmake, GDBDokument25 SeitenAdvanced C Programming: Gmake, GDBJason SinnamonNoch keine Bewertungen
- DPDK Packet Processing Ia Overview PresentationDokument35 SeitenDPDK Packet Processing Ia Overview PresentationHassan WiloNoch keine Bewertungen
- FDIO Quick Start Guide PDFDokument22 SeitenFDIO Quick Start Guide PDFPraveen KumarNoch keine Bewertungen
- vIMS For Communications Service Providers: Solution BriefDokument12 SeitenvIMS For Communications Service Providers: Solution Briefvallala venkateshNoch keine Bewertungen
- O-RAN Future Wireless Mobile NetworksDokument11 SeitenO-RAN Future Wireless Mobile NetworksMohammad RezaNoch keine Bewertungen
- NVSwitchDokument23 SeitenNVSwitchMF KangNoch keine Bewertungen
- Kimchi: An On-Ramp Virtualization Management ApplicationDokument39 SeitenKimchi: An On-Ramp Virtualization Management ApplicationCarlos Torres Hanna100% (1)
- 6-SiFive Promotes RISC-V 20190905Dokument29 Seiten6-SiFive Promotes RISC-V 20190905nauman wazirNoch keine Bewertungen
- KVM Architecture OverviewDokument15 SeitenKVM Architecture Overviewdattbbk1Noch keine Bewertungen
- TW MX3D PacketWalkthroughDokument138 SeitenTW MX3D PacketWalkthroughviatr0nicNoch keine Bewertungen
- Sriov Vs DPDKDokument28 SeitenSriov Vs DPDKshilpee 90Noch keine Bewertungen
- 5G O-RAN Solution RevisedDokument15 Seiten5G O-RAN Solution RevisedThang DangNoch keine Bewertungen
- SR IovDokument82 SeitenSR IovSuresh KumarNoch keine Bewertungen
- Linux Device DriverDokument2 SeitenLinux Device DriverRaj KumarNoch keine Bewertungen
- DPDK Optimization TechniquesDokument37 SeitenDPDK Optimization TechniquesMohit GuptaNoch keine Bewertungen
- PIW Building A NetDevOps CI CD Pipeline Part IIDokument16 SeitenPIW Building A NetDevOps CI CD Pipeline Part IIpapanNoch keine Bewertungen
- Lecture 0: Cpus and Gpus: Prof. Mike GilesDokument36 SeitenLecture 0: Cpus and Gpus: Prof. Mike GilesAashishNoch keine Bewertungen
- Journey to Cloud Native - 5G Infrastructure RequirementsDokument28 SeitenJourney to Cloud Native - 5G Infrastructure RequirementsALEXANDRE JOSE FIGUEIREDO LOUREIRONoch keine Bewertungen
- Introduction To NFVDokument48 SeitenIntroduction To NFVMohamed Abdel MonemNoch keine Bewertungen
- Intro To Network Analysis 2nd Ed. - L. Chappell (Podbooks, 2001) WW PDFDokument205 SeitenIntro To Network Analysis 2nd Ed. - L. Chappell (Podbooks, 2001) WW PDFStanley Ochieng' OumaNoch keine Bewertungen
- Linux As A Real-Time Operating System: Manas Saksena Timesys CorporationDokument43 SeitenLinux As A Real-Time Operating System: Manas Saksena Timesys CorporationVáíbhàv Kálé PátílNoch keine Bewertungen
- Packet Through The Linux Network StackDokument32 SeitenPacket Through The Linux Network StackRAMUNoch keine Bewertungen
- RHEV - What, Why and How-To PDFDokument25 SeitenRHEV - What, Why and How-To PDFRakesh SinghNoch keine Bewertungen
- Debugging PDFDokument29 SeitenDebugging PDFAnkurNoch keine Bewertungen
- Iplook Vcore (Vepc) : Security LevelDokument17 SeitenIplook Vcore (Vepc) : Security LevelIPLOOK TechnologiesNoch keine Bewertungen
- Gpu1 - GPU IntroductionDokument20 SeitenGpu1 - GPU IntroductionRichik DuttaNoch keine Bewertungen
- Program For Exchanging Pairs of Array Values in Assembly Language Using Visual Studio PDFDokument2 SeitenProgram For Exchanging Pairs of Array Values in Assembly Language Using Visual Studio PDFDilawarNoch keine Bewertungen
- SILICA Xilinx Zynq ZedBoard Vivado Workshop Ver1.0Dokument61 SeitenSILICA Xilinx Zynq ZedBoard Vivado Workshop Ver1.0Chinavenkateswararao GNoch keine Bewertungen
- Pure Storage Fast FactsDokument1 SeitePure Storage Fast FactsBIT- Budget Indian Traveller IndiaNoch keine Bewertungen
- ThinkCentre MT-M4518 m91pDokument148 SeitenThinkCentre MT-M4518 m91pDenilson Antonio RabeloNoch keine Bewertungen
- BRKRST 1014Dokument92 SeitenBRKRST 1014cool dude911Noch keine Bewertungen
- CCIE ET Programmability PDFDokument75 SeitenCCIE ET Programmability PDFzeroit4100Noch keine Bewertungen
- CBT Nuggets Vmware NSX 17epubl PDFDokument4 SeitenCBT Nuggets Vmware NSX 17epubl PDFCariNoch keine Bewertungen
- Notes - On - Linux KernelDokument2 SeitenNotes - On - Linux KernelrwyqurunkcnfnmjdnyNoch keine Bewertungen
- Introduction To Single Root IO Virtualization SRIOVDokument27 SeitenIntroduction To Single Root IO Virtualization SRIOVAhmed SharifNoch keine Bewertungen
- SPRING - Advanced Use Cases: Aditya Kaul - Solution ArchitectDokument31 SeitenSPRING - Advanced Use Cases: Aditya Kaul - Solution ArchitectTuPro FessionalNoch keine Bewertungen
- Ug981 Petalinux Application Development DebugDokument25 SeitenUg981 Petalinux Application Development DebugappalanaidugNoch keine Bewertungen
- Asr9k NCS5000Dokument17 SeitenAsr9k NCS5000RobertAlSafiNoch keine Bewertungen
- NFV-Thesis Kalliosaari Metropolia-V2 PDFDokument55 SeitenNFV-Thesis Kalliosaari Metropolia-V2 PDFJuanMateoNoch keine Bewertungen
- Openstack Install Guide Yum GrizzlyDokument135 SeitenOpenstack Install Guide Yum GrizzlyMARCO FERRANTINoch keine Bewertungen
- BRKSPG 3334Dokument170 SeitenBRKSPG 3334Daniel VieceliNoch keine Bewertungen
- DC - UCS - Presentation PDFDokument126 SeitenDC - UCS - Presentation PDFWael AliNoch keine Bewertungen
- OTV Cheatsheet V1.00 PDFDokument2 SeitenOTV Cheatsheet V1.00 PDFOliver Asturiano AbdaláNoch keine Bewertungen
- Vxworks Rtos: Embedded Systems-AssignmentDokument6 SeitenVxworks Rtos: Embedded Systems-AssignmentPrashanth KumarNoch keine Bewertungen
- OpenwrtDokument42 SeitenOpenwrtSorin NeacsuNoch keine Bewertungen
- Introduction To Device Trees PDFDokument34 SeitenIntroduction To Device Trees PDFm3y54mNoch keine Bewertungen
- 10 - HeatDokument17 Seiten10 - HeatPedro BrizuelaNoch keine Bewertungen
- Networking Deep Dive PDFDokument6 SeitenNetworking Deep Dive PDFmbalascaNoch keine Bewertungen
- H3C Project Management LLD Process V01Dokument24 SeitenH3C Project Management LLD Process V01thepanicdollsNoch keine Bewertungen
- Brkarc 2001Dokument116 SeitenBrkarc 2001Gregory WillisNoch keine Bewertungen
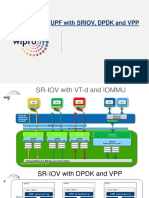
- Upf DPDK SriovDokument4 SeitenUpf DPDK SriovJayavardhan PothukuchiNoch keine Bewertungen
- GPU Programming Using openCLDokument13 SeitenGPU Programming Using openCLyhbaeNoch keine Bewertungen
- Presentation - Installing Red Hat OpenShift On Red Hat OpenStack Platform With Ansible by Red HatDokument46 SeitenPresentation - Installing Red Hat OpenShift On Red Hat OpenStack Platform With Ansible by Red Hatvadym_kovalenko4166Noch keine Bewertungen
- Asia-18-Wetzels Abassi Dissecting QNX WP PDFDokument22 SeitenAsia-18-Wetzels Abassi Dissecting QNX WP PDFZohaib AfridiNoch keine Bewertungen
- CPUs GPUs AcceleratorsDokument22 SeitenCPUs GPUs AcceleratorsKevin William DanielsNoch keine Bewertungen
- 04 MPLS Te PDFDokument69 Seiten04 MPLS Te PDFlamvan tuNoch keine Bewertungen
- Hands-On ZigBee: Implementing 802.15.4 with MicrocontrollersVon EverandHands-On ZigBee: Implementing 802.15.4 with MicrocontrollersNoch keine Bewertungen
- Cost Benefit Analysis of Hybrid VehiclesDokument24 SeitenCost Benefit Analysis of Hybrid Vehiclesramanj123Noch keine Bewertungen
- Gpon Epon Comparison Wp-107286Dokument10 SeitenGpon Epon Comparison Wp-107286ramanj123Noch keine Bewertungen
- Tele I - NGN 2011Dokument1 SeiteTele I - NGN 2011ramanj123Noch keine Bewertungen
- FortiGate 60DDokument5 SeitenFortiGate 60Dramanj123Noch keine Bewertungen
- P. Kumar: Control and Instrumentation EngineeringDokument2 SeitenP. Kumar: Control and Instrumentation Engineeringramanj123Noch keine Bewertungen
- IPv6 in the Enterprise: A Strategic GuideDokument14 SeitenIPv6 in the Enterprise: A Strategic Guideramanj123Noch keine Bewertungen
- Sonicwall TZ Series Datasheet 68221Dokument13 SeitenSonicwall TZ Series Datasheet 68221ramanj123Noch keine Bewertungen
- IPv6 in the Enterprise: A Strategic GuideDokument14 SeitenIPv6 in the Enterprise: A Strategic Guideramanj123Noch keine Bewertungen
- Sanog5 Ananth BroadbandDokument39 SeitenSanog5 Ananth Broadbandramanj123Noch keine Bewertungen
- Rama Rath NamDokument2 SeitenRama Rath Namramanj123Noch keine Bewertungen
- Pranayama by ThirumoolarDokument20 SeitenPranayama by Thirumoolaragbabu2596% (23)
- Cloud Computing Fore GovernanceDokument13 SeitenCloud Computing Fore GovernanceChandraveer Singh RathoreNoch keine Bewertungen
- The Siddha Pharmacopoeia of IndiaDokument224 SeitenThe Siddha Pharmacopoeia of Indiaponsooriya100% (5)
- Vedic MathDokument77 SeitenVedic Mathjagadeesh44Noch keine Bewertungen
- Ebook Five Key Steps Cloud TakeoffDokument16 SeitenEbook Five Key Steps Cloud Takeofframanj123Noch keine Bewertungen
- HanumaanchalisaaDokument5 SeitenHanumaanchalisaaBalaji SundaramNoch keine Bewertungen
- June 2012 OTT White Paper Schwarz SHORT PDFDokument25 SeitenJune 2012 OTT White Paper Schwarz SHORT PDFThai ThuyNoch keine Bewertungen
- DWDMDokument89 SeitenDWDMramanj123Noch keine Bewertungen
- Carrier Ethernet For Mobile Back Haul 2009Dokument39 SeitenCarrier Ethernet For Mobile Back Haul 2009ramanj123Noch keine Bewertungen
- Advances in Optical Networking in Coherent, Super-Channels and The Value of Integrated SwitchingDokument19 SeitenAdvances in Optical Networking in Coherent, Super-Channels and The Value of Integrated Switchingramanj123100% (1)
- The Siddha Pharmacopoeia of IndiaDokument224 SeitenThe Siddha Pharmacopoeia of Indiaponsooriya100% (5)
- MobilityDokument21 SeitenMobilityramanj123Noch keine Bewertungen
- Mpls TrafficDokument20 SeitenMpls Trafficramanj123Noch keine Bewertungen
- Corning Article - Tele Net - December 2012Dokument2 SeitenCorning Article - Tele Net - December 2012ramanj123Noch keine Bewertungen
- Vastu-Proof Your Home for Health, Happiness & ProsperityDokument8 SeitenVastu-Proof Your Home for Health, Happiness & Prosperityramanj123Noch keine Bewertungen
- Ip Over DWDMDokument19 SeitenIp Over DWDMramanj123Noch keine Bewertungen
- Atta Nayak eDokument8 SeitenAtta Nayak eramanj123Noch keine Bewertungen
- Vaastu Ayaadi ShadvargaDokument8 SeitenVaastu Ayaadi Shadvargaramanj12350% (2)
- Window & Door System: Let'S Build A Better FutureDokument4 SeitenWindow & Door System: Let'S Build A Better FutureAmir AlićNoch keine Bewertungen
- Engineering Standards Manual - Welding Standards M Anual - Volume 3 Welding Procedure SpecificationsDokument3 SeitenEngineering Standards Manual - Welding Standards M Anual - Volume 3 Welding Procedure Specificationslaz_k50% (2)
- Hearst Tower Feb 06Dokument0 SeitenHearst Tower Feb 06denis1808scribdNoch keine Bewertungen
- Wans and RoutersDokument17 SeitenWans and RoutersPaulo DembiNoch keine Bewertungen
- UiTM Structural Concrete Design AppendixDokument37 SeitenUiTM Structural Concrete Design AppendixMuhammad Farhan Gul67% (6)
- Cisco Model EPC2425Dokument110 SeitenCisco Model EPC2425apmihaiNoch keine Bewertungen
- Test Procedure and Acceptance Criteria For - Prime Painted Steel Surfaces For Steel Doors and FramesDokument15 SeitenTest Procedure and Acceptance Criteria For - Prime Painted Steel Surfaces For Steel Doors and FramesYel DGNoch keine Bewertungen
- Architecture in JapanDokument20 SeitenArchitecture in JapannimhaNoch keine Bewertungen
- Instruction Sets Addressing Modes FormatsDokument6 SeitenInstruction Sets Addressing Modes Formatsrongo024Noch keine Bewertungen
- Smith, JARCE 28 (1991), Askut and The Purpose of The Second Cataract FortsDokument27 SeitenSmith, JARCE 28 (1991), Askut and The Purpose of The Second Cataract FortsAnonymous 5ghkjNxNoch keine Bewertungen
- Guide To Optix OSN 3500 Service and Protection ConfigurationDokument35 SeitenGuide To Optix OSN 3500 Service and Protection Configurationshahramkarimi76100% (2)
- God of War Ghost of Sparta - IGNDokument27 SeitenGod of War Ghost of Sparta - IGNAndreas SchröderNoch keine Bewertungen
- 2 LTE Cell PlanningDokument30 Seiten2 LTE Cell PlanningRiyaz Ahmad Khan100% (12)
- New wave theories of cognition criticismDokument40 SeitenNew wave theories of cognition criticismJCNoch keine Bewertungen
- Uputstvo KlimaDokument15 SeitenUputstvo Klimacveleks100% (1)
- Dorothea Tanning's Eine Kleine Nachtmusik, 1943Dokument3 SeitenDorothea Tanning's Eine Kleine Nachtmusik, 1943Pēteris CedriņšNoch keine Bewertungen
- 8.0 Bibliography: 8.1 BOOKSDokument3 Seiten8.0 Bibliography: 8.1 BOOKSAh AnNoch keine Bewertungen
- Liray CertificationDokument4 SeitenLiray CertificationArquitect ArgeeNoch keine Bewertungen
- Steel UserguideDokument50 SeitenSteel UserguideBhanu Pratap ChoudhuryNoch keine Bewertungen
- BMC Atrium CMDB 2.1.00 Developer's Reference GuideDokument298 SeitenBMC Atrium CMDB 2.1.00 Developer's Reference GuidepisofNoch keine Bewertungen
- AIS Configuration WIZ107SRDokument4 SeitenAIS Configuration WIZ107SRmarcatiusNoch keine Bewertungen
- Life and Works of Architect Minoo P MistriDokument12 SeitenLife and Works of Architect Minoo P MistriabedinzNoch keine Bewertungen
- Grub Rescue From Live Ubuntu CD Opensource4beginnersDokument13 SeitenGrub Rescue From Live Ubuntu CD Opensource4beginnersSouravNoch keine Bewertungen
- Duct Presentation MaineDokument22 SeitenDuct Presentation MaineCharmaine ManliguezNoch keine Bewertungen
- In Plane Response of Wide Spaced Reinforced Masonry Shear WallsDokument323 SeitenIn Plane Response of Wide Spaced Reinforced Masonry Shear Wallstbrotea100% (1)
- About Trail and Training FilesDokument15 SeitenAbout Trail and Training FilesAziz Abbas0% (1)
- Column Shortening Effects and Prediction MethodsDokument28 SeitenColumn Shortening Effects and Prediction MethodsKhaled Ali AladwarNoch keine Bewertungen
- Manual MotherboardDokument171 SeitenManual Motherboardluzcy45Noch keine Bewertungen
- Prokon - Circular ColumnDokument10 SeitenProkon - Circular ColumnMasaba SolomonNoch keine Bewertungen
- AWS Well-Architected FrameworkDokument85 SeitenAWS Well-Architected FrameworkQory100% (1)