Das könnte Ihnen auch gefallen
- A Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"Von EverandA Brief Introduction to MATLAB: Taken From the Book "MATLAB for Beginners: A Gentle Approach"Bewertung: 2.5 von 5 Sternen2.5/5 (2)
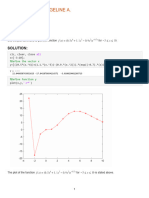
- Solved Problems: SolutionDokument30 SeitenSolved Problems: SolutionLucky DeltaNoch keine Bewertungen
- Matrices with MATLAB (Taken from "MATLAB for Beginners: A Gentle Approach")Von EverandMatrices with MATLAB (Taken from "MATLAB for Beginners: A Gentle Approach")Bewertung: 3 von 5 Sternen3/5 (4)
- Lec 18 Unidirectional Search PDFDokument32 SeitenLec 18 Unidirectional Search PDFMuhammad Bilal JunaidNoch keine Bewertungen
- Introductory Differential Equations: with Boundary Value Problems, Student Solutions Manual (e-only)Von EverandIntroductory Differential Equations: with Boundary Value Problems, Student Solutions Manual (e-only)Noch keine Bewertungen
- Pset 1 SolDokument8 SeitenPset 1 SolLJOCNoch keine Bewertungen
- hw1 Sols PDFDokument5 Seitenhw1 Sols PDFQuang H. LêNoch keine Bewertungen
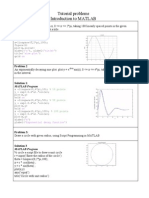
- 6 MatLab Tutorial ProblemsDokument27 Seiten6 MatLab Tutorial Problemsabhijeet834uNoch keine Bewertungen
- MATLAB Tutorial Exercises SolnsDokument5 SeitenMATLAB Tutorial Exercises SolnsBERRAK FIRATNoch keine Bewertungen
- Monte Carlo BasicsDokument23 SeitenMonte Carlo BasicsIon IvanNoch keine Bewertungen
- Digital Communication Digital Communication Digital CommunicationDokument9 SeitenDigital Communication Digital Communication Digital CommunicationFatima AdlyNoch keine Bewertungen
- AssignmentsDokument84 SeitenAssignmentsPrachi TannaNoch keine Bewertungen
- Matlab Code 3Dokument29 SeitenMatlab Code 3kthshlxyzNoch keine Bewertungen
- 1 SolutionDokument6 Seiten1 SolutionhaditgzdNoch keine Bewertungen
- HW7 SolDokument6 SeitenHW7 Solmetmet476Noch keine Bewertungen
- Trapezoidal Rule ProofDokument8 SeitenTrapezoidal Rule ProofAlanna SmithNoch keine Bewertungen
- Sample Solutions For A Concise Introduction To MATLAB by William J. Palm IIIDokument12 SeitenSample Solutions For A Concise Introduction To MATLAB by William J. Palm IIIMZSHBNoch keine Bewertungen
- ENGR 351 Numerical Methods College of Engineering Southern Illinois University Carbondale Exams Fall 2007 Instructor: Professor L.R. ChevalierDokument13 SeitenENGR 351 Numerical Methods College of Engineering Southern Illinois University Carbondale Exams Fall 2007 Instructor: Professor L.R. ChevalierAli O DalkiNoch keine Bewertungen
- Matlab HW PDFDokument3 SeitenMatlab HW PDFMohammed AbdulnaserNoch keine Bewertungen
- State-Space SystemDokument23 SeitenState-Space SystemOmar ElsayedNoch keine Bewertungen
- Sos 2Dokument16 SeitenSos 2youssef_dablizNoch keine Bewertungen
- Soln1 PsDokument6 SeitenSoln1 PsRafran Rosly100% (1)
- Solution Manual For Introduction To Applied Linear Algebra 1st by BoydDokument37 SeitenSolution Manual For Introduction To Applied Linear Algebra 1st by Boydernestocolonx88p100% (16)
- 5.2 Numerical Integration: I FXDDokument26 Seiten5.2 Numerical Integration: I FXDMuhammad FirdawsNoch keine Bewertungen
- Lab 8Dokument13 SeitenLab 8naimoonNoch keine Bewertungen
- MATLAB Handout - Feb 2018Dokument52 SeitenMATLAB Handout - Feb 2018Louis AduNoch keine Bewertungen
- 8.integration by Numerical MethodDokument7 Seiten8.integration by Numerical Methodمحمد اسماعيل يوسفNoch keine Bewertungen
- MExer01 FinalDokument11 SeitenMExer01 Finaljohannie ukaNoch keine Bewertungen
- Introduction To MATLAB For Engineers, Third Edition: Numerical Methods For Calculus and Differential EquationsDokument47 SeitenIntroduction To MATLAB For Engineers, Third Edition: Numerical Methods For Calculus and Differential EquationsSeyed SadeghNoch keine Bewertungen
- MATLAB Problem Set 4Dokument12 SeitenMATLAB Problem Set 4xman4243Noch keine Bewertungen
- Dsplab 2Dokument10 SeitenDsplab 2Jacob PopcornsNoch keine Bewertungen
- 5710 NM Tutorial 2Dokument8 Seiten5710 NM Tutorial 2Sivanesh KumarNoch keine Bewertungen
- 2019 Bme 109 Biomechanics Lab 0Dokument24 Seiten2019 Bme 109 Biomechanics Lab 0Asim BashirNoch keine Bewertungen
- Basic Matlab ExercisesDokument11 SeitenBasic Matlab ExercisesAntony Real100% (1)
- Massachusetts Institute of Technology: 6.867 Machine Learning, Fall 2006 Problem Set 2: SolutionsDokument7 SeitenMassachusetts Institute of Technology: 6.867 Machine Learning, Fall 2006 Problem Set 2: Solutionsjuanagallardo01Noch keine Bewertungen
- Hasbun PosterDokument21 SeitenHasbun PosterSuhailUmarNoch keine Bewertungen
- Correlation and Regression Skill SetDokument8 SeitenCorrelation and Regression Skill SetKahloon ThamNoch keine Bewertungen
- Trapezoidal RuleDokument4 SeitenTrapezoidal RuleFatema ShabbirNoch keine Bewertungen
- Chapter 8 HW Solution: (A) Position Vs Time. (B) Spatial PathDokument6 SeitenChapter 8 HW Solution: (A) Position Vs Time. (B) Spatial Pathrosita61Noch keine Bewertungen
- Experiment No.:03 Study of Frequency Properties of Signal Page NoDokument12 SeitenExperiment No.:03 Study of Frequency Properties of Signal Page No033Kanak SharmaNoch keine Bewertungen
- Examples - 1Dokument4 SeitenExamples - 1Simay OğuzkurtNoch keine Bewertungen
- Lecture 1: Module Overview: Zhenning Cai August 15, 2019Dokument5 SeitenLecture 1: Module Overview: Zhenning Cai August 15, 2019Liu JianghaoNoch keine Bewertungen
- Lab 5Dokument5 SeitenLab 5Kashif hussainNoch keine Bewertungen
- HW 4Dokument4 SeitenHW 4Muhammad Uzair RasheedNoch keine Bewertungen
- Lab Sheet 1: Analog To Digital Conversion (ADC) and Digital To Analog Conversion (DAC) FundamentalsDokument13 SeitenLab Sheet 1: Analog To Digital Conversion (ADC) and Digital To Analog Conversion (DAC) FundamentalsMasud SarkerNoch keine Bewertungen
- GenfitDokument2 SeitenGenfitMark Anthony CaroNoch keine Bewertungen
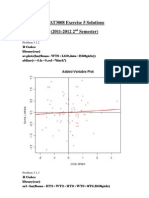
- STAT3008 Ex5 SolutionsDokument8 SeitenSTAT3008 Ex5 SolutionsKewell ChongNoch keine Bewertungen
- Darve Cme104 MatlabDokument24 SeitenDarve Cme104 MatlabArjun KumarNoch keine Bewertungen
- Image Compression Using DCTDokument17 SeitenImage Compression Using DCTapi-3853770100% (1)
- Ana 2008Dokument2 SeitenAna 2008Faber SaldanhaNoch keine Bewertungen
- Signals and SystemsDokument10 SeitenSignals and SystemsKiruthika AlagarNoch keine Bewertungen
- 27.1 The Solution Can Be Assumed To Be T E: B A B ADokument21 Seiten27.1 The Solution Can Be Assumed To Be T E: B A B Arecsa cahayaNoch keine Bewertungen
- Getting Help: Example: Look For A Function To Take The Inverse of A Matrix. Try Commands "HelpDokument24 SeitenGetting Help: Example: Look For A Function To Take The Inverse of A Matrix. Try Commands "Helpsherry mughalNoch keine Bewertungen
- MathCAD BasicsDokument10 SeitenMathCAD BasicsKrusovice15Noch keine Bewertungen
- Problem 11.1: (A) : F (Z) Z X (Z) F (Z) F Z + ZDokument9 SeitenProblem 11.1: (A) : F (Z) Z X (Z) F (Z) F Z + Zde8737Noch keine Bewertungen
- Set6s 03Dokument7 SeitenSet6s 03Akbar NafisNoch keine Bewertungen
- $R6GWGO6Dokument9 Seiten$R6GWGO6kalayil78Noch keine Bewertungen
- Assignment 1 LabDokument14 SeitenAssignment 1 LabUzair AshfaqNoch keine Bewertungen
- LABREPORT3Dokument16 SeitenLABREPORT3Tanzidul AzizNoch keine Bewertungen
- Children A Place in His ArmsDokument2 SeitenChildren A Place in His ArmsThiago AlvesNoch keine Bewertungen
- 01 - Forbes - A Lack of Cybersecurity Funding and Expertise Threatens U.S. InfrastructureDokument4 Seiten01 - Forbes - A Lack of Cybersecurity Funding and Expertise Threatens U.S. InfrastructureThiago AlvesNoch keine Bewertungen
- Alves Curriculum VitaeDokument4 SeitenAlves Curriculum VitaeThiago AlvesNoch keine Bewertungen
- FreyrSCADA DNP Client Simulator User ManualDokument12 SeitenFreyrSCADA DNP Client Simulator User ManualThiago AlvesNoch keine Bewertungen
- M221 Programming GuideDokument182 SeitenM221 Programming GuideAgus TrionoNoch keine Bewertungen
- Create A Linux System CallDokument3 SeitenCreate A Linux System CallThiago AlvesNoch keine Bewertungen
- IEEE Conference OpenPLCDokument6 SeitenIEEE Conference OpenPLCThiago AlvesNoch keine Bewertungen
- OpenPLC - An Opensource Alternative For AutomationDokument5 SeitenOpenPLC - An Opensource Alternative For AutomationThiago Alves100% (1)
- Review of Cyborg BabiesDokument3 SeitenReview of Cyborg BabiesNate GreenslitNoch keine Bewertungen
- Edci 67200 Abby Carlin Case Study FacilitationDokument9 SeitenEdci 67200 Abby Carlin Case Study Facilitationapi-265670845Noch keine Bewertungen
- Peranan Dan Tanggungjawab PPPDokument19 SeitenPeranan Dan Tanggungjawab PPPAcillz M. HaizanNoch keine Bewertungen
- Exercise of English LanguageDokument2 SeitenExercise of English LanguageErspnNoch keine Bewertungen
- Engineering Council of South Africa: 1 PurposeDokument5 SeitenEngineering Council of South Africa: 1 Purpose2lieNoch keine Bewertungen
- Rigstoreef Impact or Enhancement On Marine Biodiversity 2157 7625 1000187Dokument9 SeitenRigstoreef Impact or Enhancement On Marine Biodiversity 2157 7625 1000187tavis80Noch keine Bewertungen
- Session 5 - Marketing ManagementDokument6 SeitenSession 5 - Marketing ManagementJames MillsNoch keine Bewertungen
- Sri Lanka-ADB Partnership: 1966-2016Dokument156 SeitenSri Lanka-ADB Partnership: 1966-2016Asian Development Bank100% (2)
- BearingsDokument63 SeitenBearingsYeabsraNoch keine Bewertungen
- Meet and Greet Officer PDFDokument85 SeitenMeet and Greet Officer PDFJoby JoseNoch keine Bewertungen
- Unit 3Dokument9 SeitenUnit 3Estefani ZambranoNoch keine Bewertungen
- Cleanliness LevelDokument4 SeitenCleanliness LevelArunkumar ChandaranNoch keine Bewertungen
- Fall 2011 COP 3223 (C Programming) Syllabus: Will Provide The Specifics To His SectionDokument5 SeitenFall 2011 COP 3223 (C Programming) Syllabus: Will Provide The Specifics To His SectionSarah WilliamsNoch keine Bewertungen
- A Wish Poetry Analysis Long Bond Paper PrintDokument2 SeitenA Wish Poetry Analysis Long Bond Paper PrintJosephine OngNoch keine Bewertungen
- HSG11 V3+AnswersDokument10 SeitenHSG11 V3+AnswershaNoch keine Bewertungen
- Nursing 405 EfolioDokument5 SeitenNursing 405 Efolioapi-403368398100% (1)
- IFEM Ch07 PDFDokument19 SeitenIFEM Ch07 PDFNitzOONoch keine Bewertungen
- BS 8901 SEG Press ReleaseDokument3 SeitenBS 8901 SEG Press Releasetjsunder449Noch keine Bewertungen
- Informal and Formal Letter Writing X E Sem II 2018 - 2019Dokument15 SeitenInformal and Formal Letter Writing X E Sem II 2018 - 2019Oana Nedelcu0% (1)
- Modicon M580 Quick Start - v1.0 - Training ManualDokument169 SeitenModicon M580 Quick Start - v1.0 - Training Manualaryan_iust0% (1)
- Windows Steady State HandbookDokument81 SeitenWindows Steady State HandbookcapellaNoch keine Bewertungen
- Paranthropology Vol 3 No 3Dokument70 SeitenParanthropology Vol 3 No 3George ZafeiriouNoch keine Bewertungen
- 432 HZ - Unearthing The Truth Behind Nature's FrequencyDokument6 Seiten432 HZ - Unearthing The Truth Behind Nature's FrequencyShiv KeskarNoch keine Bewertungen
- Criminal Behavior and Learning TheoryDokument8 SeitenCriminal Behavior and Learning TheoryRobert BataraNoch keine Bewertungen
- Detailed Lesson Plan - Hand Movements and Gestures in Folk DanceDokument2 SeitenDetailed Lesson Plan - Hand Movements and Gestures in Folk DanceJaime MenceroNoch keine Bewertungen
- Associate Cloud Engineer - Study NotesDokument14 SeitenAssociate Cloud Engineer - Study Notesabhi16101Noch keine Bewertungen
- Lab ManualDokument69 SeitenLab ManualPradeepNoch keine Bewertungen
- Curriculum VitaeDokument4 SeitenCurriculum Vitaeapi-200104647Noch keine Bewertungen
- 5300 Operation Manual (v1.5)Dokument486 Seiten5300 Operation Manual (v1.5)Phan Quan100% (1)
- A Brief About Chandrayaan 1Dokument3 SeitenA Brief About Chandrayaan 1DebasisBarikNoch keine Bewertungen
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindVon EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNoch keine Bewertungen
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessVon EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNoch keine Bewertungen
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldVon EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldBewertung: 4.5 von 5 Sternen4.5/5 (107)
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveVon EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNoch keine Bewertungen
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldVon EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldBewertung: 4.5 von 5 Sternen4.5/5 (55)
- Generative AI: The Insights You Need from Harvard Business ReviewVon EverandGenerative AI: The Insights You Need from Harvard Business ReviewBewertung: 4.5 von 5 Sternen4.5/5 (2)
- Power and Prediction: The Disruptive Economics of Artificial IntelligenceVon EverandPower and Prediction: The Disruptive Economics of Artificial IntelligenceBewertung: 4.5 von 5 Sternen4.5/5 (38)
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesVon EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesBewertung: 4.5 von 5 Sternen4.5/5 (13)
- Demystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)Von EverandDemystifying Prompt Engineering: AI Prompts at Your Fingertips (A Step-By-Step Guide)Bewertung: 4 von 5 Sternen4/5 (1)
- HBR's 10 Must Reads on AI, Analytics, and the New Machine AgeVon EverandHBR's 10 Must Reads on AI, Analytics, and the New Machine AgeBewertung: 4.5 von 5 Sternen4.5/5 (69)
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewVon EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewBewertung: 4.5 von 5 Sternen4.5/5 (104)
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkVon EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkBewertung: 4 von 5 Sternen4/5 (7)
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)Von EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)Noch keine Bewertungen
- 100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziVon Everand100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziNoch keine Bewertungen
- Machine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepVon EverandMachine Learning: The Ultimate Beginner's Guide to Learn Machine Learning, Artificial Intelligence & Neural Networks Step by StepBewertung: 4.5 von 5 Sternen4.5/5 (19)
- AI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceVon EverandAI and Machine Learning for Coders: A Programmer's Guide to Artificial IntelligenceBewertung: 4 von 5 Sternen4/5 (2)
- Artificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Von EverandArtificial Intelligence: The Complete Beginner’s Guide to the Future of A.I.Bewertung: 4 von 5 Sternen4/5 (15)
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsVon EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsNoch keine Bewertungen
- Four Battlegrounds: Power in the Age of Artificial IntelligenceVon EverandFour Battlegrounds: Power in the Age of Artificial IntelligenceBewertung: 5 von 5 Sternen5/5 (5)
- Artificial Intelligence: A Guide for Thinking HumansVon EverandArtificial Intelligence: A Guide for Thinking HumansBewertung: 4.5 von 5 Sternen4.5/5 (30)
- The Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsVon EverandThe Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsNoch keine Bewertungen
- Fusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureVon EverandFusion Strategy: How Real-Time Data and AI Will Power the Industrial FutureNoch keine Bewertungen
- Quantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsVon EverandQuantum Physics: A Beginners Guide to How Quantum Physics Affects Everything around UsBewertung: 4.5 von 5 Sternen4.5/5 (3)