Das könnte Ihnen auch gefallen
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Sap Bo Dashboards (Xcelsius) VS. Sap Design StudioDokument10 SeitenSap Bo Dashboards (Xcelsius) VS. Sap Design StudioisskumarNoch keine Bewertungen
- Reading Multiple Sheets of A Xls File in BodsDokument5 SeitenReading Multiple Sheets of A Xls File in Bodsisskumar0% (1)
- Whatif AnalysisDokument2 SeitenWhatif AnalysisisskumarNoch keine Bewertungen
- Difference Between Multiprovider and InfosetDokument3 SeitenDifference Between Multiprovider and InfosetisskumarNoch keine Bewertungen
- Performance Optimization in BODSDokument67 SeitenPerformance Optimization in BODSisskumar67% (3)
- Central Managemetn ConsoleDokument74 SeitenCentral Managemetn ConsoleisskumarNoch keine Bewertungen
- DSR Billing ReportDokument13 SeitenDSR Billing ReportisskumarNoch keine Bewertungen
- BODS Match TrasnformDokument1 SeiteBODS Match Trasnformisskumar0% (1)
- Complex Objects in Business ObjectsDokument10 SeitenComplex Objects in Business ObjectsisskumarNoch keine Bewertungen
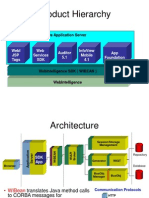
- Product Hierarchy: Java Application ServerDokument2 SeitenProduct Hierarchy: Java Application ServerisskumarNoch keine Bewertungen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5795)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1091)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Enterprise Data Catalog Data Sheet 3238enDokument7 SeitenEnterprise Data Catalog Data Sheet 3238enDuncan ReidNoch keine Bewertungen
- Exam Schedule - February Semester 2023Dokument2 SeitenExam Schedule - February Semester 2023chong wongNoch keine Bewertungen
- Presentation - Exadata Backup PracticesDokument16 SeitenPresentation - Exadata Backup Practiceskinan_kazuki104Noch keine Bewertungen
- 8 Tips For BADokument16 Seiten8 Tips For BAArjun ReddyNoch keine Bewertungen
- Difference Between Web Browser and Search EngineDokument2 SeitenDifference Between Web Browser and Search EngineSatnam AzrotNoch keine Bewertungen
- OMGT2085 (Intro To Logistics & Supply Chain MGT) - T1 - Keeping It Simple - The PUMA Supply Chain-1Dokument2 SeitenOMGT2085 (Intro To Logistics & Supply Chain MGT) - T1 - Keeping It Simple - The PUMA Supply Chain-1Châu LêNoch keine Bewertungen
- C100dev 3Dokument14 SeitenC100dev 3Mai PhuongNoch keine Bewertungen
- Data Security in Cloud ComputingDokument324 SeitenData Security in Cloud Computingprince2venkatNoch keine Bewertungen
- Hyperion Financial Management 9.3.1: Create and Manage ApplicationsDokument16 SeitenHyperion Financial Management 9.3.1: Create and Manage Applicationsmohan krishnaNoch keine Bewertungen
- Oracle Solaris 10 Operating System Essentials: DurationDokument3 SeitenOracle Solaris 10 Operating System Essentials: Durationmatos07Noch keine Bewertungen
- Question 2Dokument58 SeitenQuestion 2api-3850055Noch keine Bewertungen
- MFCODEDokument103 SeitenMFCODERuben PanjaitanNoch keine Bewertungen
- Azure Migration and Modernization Program: Help Your Customers Save Money, Stay Secure, and Scale On-DemandDokument2 SeitenAzure Migration and Modernization Program: Help Your Customers Save Money, Stay Secure, and Scale On-DemandAdil SadikiNoch keine Bewertungen
- Real Application Testing On 10gDokument74 SeitenReal Application Testing On 10gjjivkovNoch keine Bewertungen
- Linux Red HatDokument35 SeitenLinux Red HatAkhilmpecNoch keine Bewertungen
- ServiceNow + Microsoft Azure DevOps - Battle Card-FinalDokument2 SeitenServiceNow + Microsoft Azure DevOps - Battle Card-FinalBayCreativeNoch keine Bewertungen
- Creating A Sequence DiagramDokument2 SeitenCreating A Sequence Diagramernest marcelinoNoch keine Bewertungen
- New Features in R12 Oracle Cash ManagementDokument50 SeitenNew Features in R12 Oracle Cash Managementerpswan100% (1)
- Lab Manual: School of Computing Science & EngineeringDokument36 SeitenLab Manual: School of Computing Science & EngineeringMunyaradzi ZhouNoch keine Bewertungen
- Fisica Basica 3er Ano Santillana PDFDokument66 SeitenFisica Basica 3er Ano Santillana PDFDRIVEXX :DNoch keine Bewertungen
- AWSCertified MLSlidesDokument450 SeitenAWSCertified MLSlidesNoèlia HerreroNoch keine Bewertungen
- Airpush SDKDokument12 SeitenAirpush SDKSfrj CaffeNoch keine Bewertungen
- SQL-BackTrack™ Module For IBM Tivoli Storage Manager Installation and User Guide Version 3.1.00Dokument172 SeitenSQL-BackTrack™ Module For IBM Tivoli Storage Manager Installation and User Guide Version 3.1.00dillonr01Noch keine Bewertungen
- Platform Analytics GuideDokument469 SeitenPlatform Analytics GuideSai Kiran GsixNoch keine Bewertungen
- Datacenter Black Belt Hyperflex Recommended TrainingsDokument2 SeitenDatacenter Black Belt Hyperflex Recommended TrainingsJR CortezNoch keine Bewertungen
- AWS Important Questions For CCPDokument480 SeitenAWS Important Questions For CCPPruthviraj PatilNoch keine Bewertungen
- Assignment 2Dokument3 SeitenAssignment 2armaan04062004Noch keine Bewertungen
- HackTheBox - Bucket WalkthroughDokument11 SeitenHackTheBox - Bucket WalkthroughGinaAlexandraNoch keine Bewertungen
- Pervasive PSQLDokument6 SeitenPervasive PSQLAditya Sudhesh Raghu VamsiNoch keine Bewertungen
- SAP PM Resume - PrakashDokument4 SeitenSAP PM Resume - Prakashnagasuresh nNoch keine Bewertungen