Das könnte Ihnen auch gefallen
- Computer Organization and Design Chapter 2 SolutionsDokument5 SeitenComputer Organization and Design Chapter 2 SolutionsDanayFerMar0% (5)
- Instruction Set Architecture-Nguyễn Hoàng Long - BI11-157Dokument11 SeitenInstruction Set Architecture-Nguyễn Hoàng Long - BI11-157Long NguyễnNoch keine Bewertungen
- CSE 3666 Homework 2Dokument7 SeitenCSE 3666 Homework 2Patricia AlfonsoNoch keine Bewertungen
- Managing operations service problemsDokument2 SeitenManaging operations service problemsJoel Christian Mascariña0% (1)
- 10 Consulting Frameworks To Learn For Case Interview - MConsultingPrepDokument25 Seiten10 Consulting Frameworks To Learn For Case Interview - MConsultingPrepTushar KumarNoch keine Bewertungen
- CH02 Solution-1 PDFDokument10 SeitenCH02 Solution-1 PDFAli AhmedNoch keine Bewertungen
- Mẫu bài tập về vòng lặp và mảng trong ngôn ngữ lập trình MIPS AssemblyDokument3 SeitenMẫu bài tập về vòng lặp và mảng trong ngôn ngữ lập trình MIPS AssemblyTài Huỳnh VănNoch keine Bewertungen
- MIPS Assembly Code for Midterm and Final Exam ProblemsDokument3 SeitenMIPS Assembly Code for Midterm and Final Exam ProblemsKien AnNoch keine Bewertungen
- Last Part of The LastDokument3 SeitenLast Part of The Lastd2m001Noch keine Bewertungen
- bai1Dokument3 Seitenbai122521194Noch keine Bewertungen
- SequentialSort SDokument1 SeiteSequentialSort SMiguel HortaNoch keine Bewertungen
- Computer Organization Homework 2: Our Answer atDokument5 SeitenComputer Organization Homework 2: Our Answer atLe ngo thiNoch keine Bewertungen
- MIPS Practice Questions - ANSWERSDokument5 SeitenMIPS Practice Questions - ANSWERSRajeen VenuraNoch keine Bewertungen
- Loading value from memory address into registerDokument2 SeitenLoading value from memory address into registerSangNoch keine Bewertungen
- LW $t0, Big ($s2)Dokument2 SeitenLW $t0, Big ($s2)SangNoch keine Bewertungen
- Week10.1 - 20200349 - NguyenThiLinh 1Dokument10 SeitenWeek10.1 - 20200349 - NguyenThiLinh 1Quân Nguyễn HoàngNoch keine Bewertungen
- LW $t0, Big ($s2)Dokument2 SeitenLW $t0, Big ($s2)Nguyễn Tiến LựcNoch keine Bewertungen
- Instruction Set Architecture: Mips Section 2.6-2.7,2.8,2.9Dokument26 SeitenInstruction Set Architecture: Mips Section 2.6-2.7,2.8,2.9api-26072581Noch keine Bewertungen
- MIPSReferenceDokument2 SeitenMIPSReferencessy5Noch keine Bewertungen
- Homework 4 (Christophe El Haddad)Dokument4 SeitenHomework 4 (Christophe El Haddad)Christophe HaddadNoch keine Bewertungen
- C to MIPS Translation and Bit ManipulationDokument58 SeitenC to MIPS Translation and Bit ManipulationSomaticQiNoch keine Bewertungen
- CSCI-365 Computer OrganizationDokument18 SeitenCSCI-365 Computer OrganizationSebastianAlbertoRodriguezNoch keine Bewertungen
- Exercise 2.33Dokument3 SeitenExercise 2.33William WesterveltNoch keine Bewertungen
- FP Calc MPDokument27 SeitenFP Calc MPApricot BlueberryNoch keine Bewertungen
- Chapter 2 Solutions: For More PracticeDokument8 SeitenChapter 2 Solutions: For More Practicekamalpreet_gNoch keine Bewertungen
- Mips Programming (2) : Assembly LanguageDokument28 SeitenMips Programming (2) : Assembly LanguageJavier ParragaNoch keine Bewertungen
- Computer Architecture and Organization Worksheet-1: Taye G. (Asst. Professor)Dokument10 SeitenComputer Architecture and Organization Worksheet-1: Taye G. (Asst. Professor)Kalkidan AshenafiNoch keine Bewertungen
- Homework 2 (Christophe El Haddad)Dokument3 SeitenHomework 2 (Christophe El Haddad)Christophe HaddadNoch keine Bewertungen
- CA ch2 PDFDokument14 SeitenCA ch2 PDFdeepak kumarNoch keine Bewertungen
- Review - Midterm 2Dokument10 SeitenReview - Midterm 2kNoch keine Bewertungen
- R2000 Binary Instructions TranslationDokument3 SeitenR2000 Binary Instructions TranslationfulipommixNoch keine Bewertungen
- Compiling A Switch StatementDokument9 SeitenCompiling A Switch StatementAli Sa'eidNoch keine Bewertungen
- Midterm Solutions (1 of 3) Assembly Language EEE 230Dokument3 SeitenMidterm Solutions (1 of 3) Assembly Language EEE 230Bryon MitchellNoch keine Bewertungen
- Lecture 10 - CH 02Dokument17 SeitenLecture 10 - CH 02Osama RousanNoch keine Bewertungen
- Coal Ab Questions SolutionsDokument20 SeitenCoal Ab Questions SolutionsAnonymous XsATnbPwNoch keine Bewertungen
- Sheet 1 solution for Computer Architecture course at Alexandria UniversityDokument7 SeitenSheet 1 solution for Computer Architecture course at Alexandria UniversityOmar EssamNoch keine Bewertungen
- Dương-Thái-Anh Bai4Dokument12 SeitenDương-Thái-Anh Bai4Thái Anh DươngNoch keine Bewertungen
- מצגת תרגול 2Dokument13 Seitenמצגת תרגול 2Matan Bar LevNoch keine Bewertungen
- MIPS Assembly Reference SheetDokument2 SeitenMIPS Assembly Reference SheetDerrick liNoch keine Bewertungen
- TK3163 Sem2 2021 10MyCh4.6 SLRDokument17 SeitenTK3163 Sem2 2021 10MyCh4.6 SLRhegong wangNoch keine Bewertungen
- 9 12 13 PDFDokument6 Seiten9 12 13 PDFdoomachaleyNoch keine Bewertungen
- Arrays of integers in MIPS assemblyDokument13 SeitenArrays of integers in MIPS assemblySaif Ali KhanNoch keine Bewertungen
- MIPS CheatsheetDokument2 SeitenMIPS CheatsheetMohamed SaidNoch keine Bewertungen
- MIPS R2000 Samples: Lu Is Lopes 15 de Marc o de 2013Dokument10 SeitenMIPS R2000 Samples: Lu Is Lopes 15 de Marc o de 2013V4ndaNoch keine Bewertungen
- Exercises 06 - MIPS - 2020Dokument16 SeitenExercises 06 - MIPS - 2020EraNoch keine Bewertungen
- LP Week6 LRparsingonlyDokument15 SeitenLP Week6 LRparsingonlyAbeera KhalidNoch keine Bewertungen
- Assingment 2 CSCI 236Dokument10 SeitenAssingment 2 CSCI 236SebastianAlbertoRodriguezNoch keine Bewertungen
- Assignment 2 SolutionsDokument4 SeitenAssignment 2 SolutionsskdejhloiewNoch keine Bewertungen
- CS61C Homework 3 - C to MIPS Practice ProblemsDokument8 SeitenCS61C Homework 3 - C to MIPS Practice ProblemsElisa TsanNoch keine Bewertungen
- Introduction To Calculus Section Velocity and Distance (PageDokument32 SeitenIntroduction To Calculus Section Velocity and Distance (PageIhab AbdullahNoch keine Bewertungen
- Transformada 4-220201007 - 09452223Dokument4 SeitenTransformada 4-220201007 - 09452223ZaiLoC HearTNoch keine Bewertungen
- Quiz 1Dokument1 SeiteQuiz 1陳冠言 CHEN,KUAN-YEN H54084010Noch keine Bewertungen
- Lab Exercise 5 AnswerDokument2 SeitenLab Exercise 5 AnswerSandra ChenNoch keine Bewertungen
- COE301 Lab 3 IntegerArithmeticDokument7 SeitenCOE301 Lab 3 IntegerArithmeticItz Sami UddinNoch keine Bewertungen
- Homework Computer ArchitectureDokument13 SeitenHomework Computer ArchitectureMumtahina ParvinNoch keine Bewertungen
- MIPS Instruction RefDokument9 SeitenMIPS Instruction RefSergio AntibioticeNoch keine Bewertungen
- Using Awt Main FunctionDokument15 SeitenUsing Awt Main FunctionJoel JosephNoch keine Bewertungen
- LRParsersDokument46 SeitenLRParsersPriyaNoch keine Bewertungen
- Laplace Transform Lab ExperimentsDokument4 SeitenLaplace Transform Lab ExperimentsUsama TufailNoch keine Bewertungen
- Ten-Decimal Tables of the Logarithms of Complex Numbers and for the Transformation from Cartesian to Polar Coordinates: Volume 33 in Mathematical Tables SeriesVon EverandTen-Decimal Tables of the Logarithms of Complex Numbers and for the Transformation from Cartesian to Polar Coordinates: Volume 33 in Mathematical Tables SeriesNoch keine Bewertungen
- Catalog FK Thai 2016-2017Dokument64 SeitenCatalog FK Thai 2016-2017Chanon TonmaiNoch keine Bewertungen
- Lab 1Dokument2 SeitenLab 1Gizmico CarroNoch keine Bewertungen
- C3 1 5 10 Solution PDFDokument5 SeitenC3 1 5 10 Solution PDFChanon TonmaiNoch keine Bewertungen
- 1 Steady StateDokument81 Seiten1 Steady StateEdward RinconNoch keine Bewertungen
- Binaryconnect: Training Deep Neural Networks With Binary Weights During PropagationsDokument9 SeitenBinaryconnect: Training Deep Neural Networks With Binary Weights During PropagationsChanon TonmaiNoch keine Bewertungen
- Matlab - Lecture 4Dokument22 SeitenMatlab - Lecture 4Chanon TonmaiNoch keine Bewertungen
- hw2 61Dokument1 Seitehw2 61Chanon TonmaiNoch keine Bewertungen
- Discrete Time ConvolutionDokument21 SeitenDiscrete Time ConvolutionATHAR IQBALNoch keine Bewertungen
- Should We Encode Rain Streaks in Video As Deterministic or Stochastic?Dokument10 SeitenShould We Encode Rain Streaks in Video As Deterministic or Stochastic?Chanon TonmaiNoch keine Bewertungen
- Physica: The Dynamics of Sandpiles: The Competing Roles of Grains and ClustersDokument20 SeitenPhysica: The Dynamics of Sandpiles: The Competing Roles of Grains and ClustersChanon TonmaiNoch keine Bewertungen
- With The DevelopmentDokument3 SeitenWith The DevelopmentChanon TonmaiNoch keine Bewertungen
- 123Dokument1 Seite123Chanon TonmaiNoch keine Bewertungen
- Many PeopleDokument1 SeiteMany PeopleChanon TonmaiNoch keine Bewertungen
- Task 2Dokument3 SeitenTask 2Chanon TonmaiNoch keine Bewertungen
- 1P5 0188Dokument5 Seiten1P5 0188Chanon TonmaiNoch keine Bewertungen
- Chapter 1-Introduction To MaterialsDokument20 SeitenChapter 1-Introduction To MaterialsChanon TonmaiNoch keine Bewertungen
- TouristsDokument1 SeiteTouristsChanon TonmaiNoch keine Bewertungen
- Eng Mar 46Dokument23 SeitenEng Mar 46Chanon TonmaiNoch keine Bewertungen
- Eng Oct 43Dokument26 SeitenEng Oct 43Chanon TonmaiNoch keine Bewertungen
- Eng Mar 44Dokument28 SeitenEng Mar 44Chanon TonmaiNoch keine Bewertungen
- CarlendarDokument2 SeitenCarlendarChanon TonmaiNoch keine Bewertungen
- ChrysanthemumFlowerBed JayChouDokument3 SeitenChrysanthemumFlowerBed JayChouByron Lu MorrellNoch keine Bewertungen
- Youtube AlgorithmDokument27 SeitenYoutube AlgorithmShubham FarakateNoch keine Bewertungen
- CELF Final ProspectusDokument265 SeitenCELF Final ProspectusDealBookNoch keine Bewertungen
- 1 N 2Dokument327 Seiten1 N 2Muhammad MunifNoch keine Bewertungen
- Unit 13 AminesDokument3 SeitenUnit 13 AminesArinath DeepaNoch keine Bewertungen
- Sampling Fundamentals ModifiedDokument45 SeitenSampling Fundamentals ModifiedArjun KhoslaNoch keine Bewertungen
- Libros de ConcretoDokument11 SeitenLibros de ConcretoOSCAR GABRIEL MOSCOL JIBAJANoch keine Bewertungen
- Laporan Mutasi Inventory GlobalDokument61 SeitenLaporan Mutasi Inventory GlobalEustas D PickNoch keine Bewertungen
- Cycles in Nature: Understanding Biogeochemical CyclesDokument17 SeitenCycles in Nature: Understanding Biogeochemical CyclesRatay EvelynNoch keine Bewertungen
- Critical Values For The Dickey-Fuller Unit Root T-Test StatisticsDokument1 SeiteCritical Values For The Dickey-Fuller Unit Root T-Test Statisticswjimenez1938Noch keine Bewertungen
- Structures Module 3 Notes FullDokument273 SeitenStructures Module 3 Notes Fulljohnmunjuga50Noch keine Bewertungen
- Using The Marketing Mix Reading Comprenhension TaskDokument17 SeitenUsing The Marketing Mix Reading Comprenhension TaskMonica GalvisNoch keine Bewertungen
- Siyaram S AR 18-19 With Notice CompressedDokument128 SeitenSiyaram S AR 18-19 With Notice Compressedkhushboo rajputNoch keine Bewertungen
- BC Specialty Foods DirectoryDokument249 SeitenBC Specialty Foods Directoryjcl_da_costa6894Noch keine Bewertungen
- Amos Code SystemDokument17 SeitenAmos Code SystemViktor KarlashevychNoch keine Bewertungen
- DX133 DX Zero Hair HRL Regular 200 ML SDS 16.04.2018 2023Dokument6 SeitenDX133 DX Zero Hair HRL Regular 200 ML SDS 16.04.2018 2023Welissa ChicanequissoNoch keine Bewertungen
- 11 Dole Philippines vs. Maritime Co., G.R. No. L-61352 PDFDokument8 Seiten11 Dole Philippines vs. Maritime Co., G.R. No. L-61352 PDFpa0l0sNoch keine Bewertungen
- Literature Review 5Dokument4 SeitenLiterature Review 5api-463653994Noch keine Bewertungen
- HetNet Solution Helps Telcos Improve User Experience & RevenueDokument60 SeitenHetNet Solution Helps Telcos Improve User Experience & RevenuefarrukhmohammedNoch keine Bewertungen
- TransformerDokument50 SeitenTransformerبنیاد پرست100% (8)
- IBM TS3500 Command Line Interface (CLI) ExamplesDokument6 SeitenIBM TS3500 Command Line Interface (CLI) ExamplesMustafa BenmaghaNoch keine Bewertungen
- ETP Research Proposal Group7 NewDokument12 SeitenETP Research Proposal Group7 NewlohNoch keine Bewertungen
- Human Resource Management: Chapter One-An Overview of Advanced HRMDokument45 SeitenHuman Resource Management: Chapter One-An Overview of Advanced HRMbaba lakeNoch keine Bewertungen
- Nmea Components: NMEA 2000® Signal Supply Cable NMEA 2000® Gauges, Gauge Kits, HarnessesDokument2 SeitenNmea Components: NMEA 2000® Signal Supply Cable NMEA 2000® Gauges, Gauge Kits, HarnessesNuty IonutNoch keine Bewertungen
- C J L F S: Vinod TiwariDokument21 SeitenC J L F S: Vinod TiwariVinod TiwariNoch keine Bewertungen
- Java MCQ questions and answersDokument65 SeitenJava MCQ questions and answersShermin FatmaNoch keine Bewertungen
- Ultrasonic Examination of Heavy Steel Forgings: Standard Practice ForDokument7 SeitenUltrasonic Examination of Heavy Steel Forgings: Standard Practice ForbatataNoch keine Bewertungen
- Cagayan Electric Company v. CIRDokument2 SeitenCagayan Electric Company v. CIRCocoyPangilinanNoch keine Bewertungen
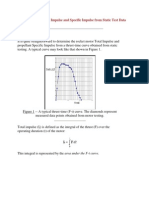
- Determining Total Impulse and Specific Impulse From Static Test DataDokument4 SeitenDetermining Total Impulse and Specific Impulse From Static Test Datajai_selvaNoch keine Bewertungen