Das könnte Ihnen auch gefallen
- Automata, Grammars and Languages: Example: We describe a finite state machine with two input symbols (σ, σ) ,Dokument4 SeitenAutomata, Grammars and Languages: Example: We describe a finite state machine with two input symbols (σ, σ) ,Joanna Mary LopezNoch keine Bewertungen
- Finite State Machines With Output (Mealy and Moore Machines)Dokument17 SeitenFinite State Machines With Output (Mealy and Moore Machines)Satish AripakaNoch keine Bewertungen
- Iq AsmDokument5 SeitenIq AsmalbertNoch keine Bewertungen
- Algorithmic State Machine (ASM) : UnitDokument10 SeitenAlgorithmic State Machine (ASM) : Unitateeq mughalNoch keine Bewertungen
- Mathematical Foundations of Finite Automata (FADokument9 SeitenMathematical Foundations of Finite Automata (FAadeelmurtaza5730Noch keine Bewertungen
- Lecture 4Dokument44 SeitenLecture 4suitunivNoch keine Bewertungen
- Asm 1Dokument5 SeitenAsm 1Jagan RajendiranNoch keine Bewertungen
- Unit - 1 DSDDokument56 SeitenUnit - 1 DSDultimatekp144Noch keine Bewertungen
- Detecting a Simple Sequence FSMDokument3 SeitenDetecting a Simple Sequence FSMAb AbNoch keine Bewertungen
- Week 12 - Module 10 Finite State Machines 1Dokument7 SeitenWeek 12 - Module 10 Finite State Machines 1Ben GwenNoch keine Bewertungen
- Finite State MachinesDokument16 SeitenFinite State MachinesAKASH PALNoch keine Bewertungen
- 14 Finite StateDokument35 Seiten14 Finite Statenani10Noch keine Bewertungen
- FSM Worksheet PDFDokument8 SeitenFSM Worksheet PDFabuzar raoNoch keine Bewertungen
- Sequential Mealy Machines VHDLSession8 EnotesDokument16 SeitenSequential Mealy Machines VHDLSession8 EnotessaravananpaulchamyNoch keine Bewertungen
- Finite state machines simplified with state reductionDokument21 SeitenFinite state machines simplified with state reductionHayan FadhilNoch keine Bewertungen
- FSM SlidesDokument37 SeitenFSM SlidesSahil Sharma0% (1)
- Switching and Finite Automata Theory, 3rd Ed by Kohavi, K. Jha Sample From Ch10Dokument3 SeitenSwitching and Finite Automata Theory, 3rd Ed by Kohavi, K. Jha Sample From Ch10alberteinstein407Noch keine Bewertungen
- Asgnmt6 (522) Tawab SirDokument11 SeitenAsgnmt6 (522) Tawab SirDil NawazNoch keine Bewertungen
- The Synthesis of Finite State Machines by Using A Combined Meely and Moore ModelDokument6 SeitenThe Synthesis of Finite State Machines by Using A Combined Meely and Moore ModelValery SalauyouNoch keine Bewertungen
- Automata Moore MealyMachineDokument6 SeitenAutomata Moore MealyMachineratna.patilNoch keine Bewertungen
- Algorithmic State Machine Design and ConversionDokument16 SeitenAlgorithmic State Machine Design and ConversionkaosadNoch keine Bewertungen
- Computer - New - Automata Theory Lecture 6 Equivalence and Reduction of Finite State MachinesDokument35 SeitenComputer - New - Automata Theory Lecture 6 Equivalence and Reduction of Finite State MachinesBolarinwa OwuogbaNoch keine Bewertungen
- VHDL FSM UNIT 5 ET&T 7th SemDokument22 SeitenVHDL FSM UNIT 5 ET&T 7th SemDEEPA KUNWARNoch keine Bewertungen
- SEO-Optimized Title for Document on Context Sensitivity of C++ and Finite State MachinesDokument4 SeitenSEO-Optimized Title for Document on Context Sensitivity of C++ and Finite State MachinesAbhaydeep singhNoch keine Bewertungen
- Sample Q. PaperDokument3 SeitenSample Q. PaperApoorv SinghNoch keine Bewertungen
- MIT6004 S 09 Tutor 07 SolDokument15 SeitenMIT6004 S 09 Tutor 07 SolAbhijith RanguduNoch keine Bewertungen
- HOMEWORK 5 Solution: ICS 151 - Digital Logic DesignDokument10 SeitenHOMEWORK 5 Solution: ICS 151 - Digital Logic DesignWindy Ford100% (1)
- 10 1 1 37 307Dokument50 Seiten10 1 1 37 307Oluponmile AdeolaNoch keine Bewertungen
- Unit 6 - FinalDokument24 SeitenUnit 6 - Finalsuniljain007Noch keine Bewertungen
- LECTURE B 1 FSM Minimization IntroDokument18 SeitenLECTURE B 1 FSM Minimization IntroSathish KumarNoch keine Bewertungen
- Automata & Complexity Theory Cosc3025: Chapter OneDokument27 SeitenAutomata & Complexity Theory Cosc3025: Chapter Oneabebaw ataleleNoch keine Bewertungen
- Quiz 6 SolutionsDokument9 SeitenQuiz 6 SolutionsAmreshAmanNoch keine Bewertungen
- DD Slides6Dokument57 SeitenDD Slides6tanay.s1Noch keine Bewertungen
- Finite State Machines (FSMS)Dokument16 SeitenFinite State Machines (FSMS)Nithin KumarNoch keine Bewertungen
- 101 2 Digitalsystems Chap 05 2Dokument34 Seiten101 2 Digitalsystems Chap 05 2thivyadharshiniNoch keine Bewertungen
- Moore Mealy Machine Lecture-1Dokument15 SeitenMoore Mealy Machine Lecture-1ali yousafNoch keine Bewertungen
- Moore Mealy Machine Lecture-1Dokument15 SeitenMoore Mealy Machine Lecture-1ali yousafNoch keine Bewertungen
- LECTURE B 1 FSM Minimization IntroDokument18 SeitenLECTURE B 1 FSM Minimization IntroBharadwaja PisupatiNoch keine Bewertungen
- Info 2950 FSM Part1Dokument29 SeitenInfo 2950 FSM Part1John SmithNoch keine Bewertungen
- Slides-L6 4up PsDokument2 SeitenSlides-L6 4up PsHussain52532012Noch keine Bewertungen
- Maths Turing MachinesDokument5 SeitenMaths Turing MachinesBhasinee ManageNoch keine Bewertungen
- Finite State MachinesDokument8 SeitenFinite State MachinesHnd FinalNoch keine Bewertungen
- Implementing FSM VerilogDokument8 SeitenImplementing FSM VerilogAdil AhmedNoch keine Bewertungen
- Auto Mata Chapter6Dokument24 SeitenAuto Mata Chapter6MypdfsiteNoch keine Bewertungen
- FSM LinhbunddddDokument13 SeitenFSM LinhbunddddlinhddddNoch keine Bewertungen
- Use of Genetic Algorithm To Resolve The Problem of Finite State Machine ConstructionDokument18 SeitenUse of Genetic Algorithm To Resolve The Problem of Finite State Machine ConstructionDevendra SharmaNoch keine Bewertungen
- Chapter Two Regular ExpressionDokument41 SeitenChapter Two Regular Expressionhachalu50Noch keine Bewertungen
- LC11Dokument5 SeitenLC11waheed azizNoch keine Bewertungen
- c4.1 Nfa+BuchiDokument39 Seitenc4.1 Nfa+BuchiGANAPATHY.SNoch keine Bewertungen
- Digital Circuits - Finite State MachinesDokument3 SeitenDigital Circuits - Finite State Machinesyasar saleemNoch keine Bewertungen
- Moore and Mearly MachineDokument65 SeitenMoore and Mearly MachineJibran ElahiNoch keine Bewertungen
- Finite Automata With Output: Lecture ObjectiveDokument6 SeitenFinite Automata With Output: Lecture ObjectiveAyazNoch keine Bewertungen
- Recap Lecture 20: Recap Theorem, Example, Finite Automaton With Output, Moore Machine, ExamplesDokument22 SeitenRecap Lecture 20: Recap Theorem, Example, Finite Automaton With Output, Moore Machine, ExamplesMuhammad SaifalNoch keine Bewertungen
- FSM DesignDokument24 SeitenFSM DesignNazim Ali100% (1)
- CS2001 Week 3 Tutorial: Finite State SystemsDokument1 SeiteCS2001 Week 3 Tutorial: Finite State SystemsAbhishek GambhirNoch keine Bewertungen
- Specification Journal 014: 3.4.2 Finite State MachinesDokument4 SeitenSpecification Journal 014: 3.4.2 Finite State MachinesSyamkumar Manikonda.v.jNoch keine Bewertungen
- Lab Session # 9 Finite State Machines (FSMS) : W), and Produces A Set of Outputs (Z)Dokument7 SeitenLab Session # 9 Finite State Machines (FSMS) : W), and Produces A Set of Outputs (Z)Ahmad M. HammadNoch keine Bewertungen
- 04-Displays-KeyPad Interfacing PDFDokument35 Seiten04-Displays-KeyPad Interfacing PDFRagini GuptaNoch keine Bewertungen
- FinalWebSockets Final RPiDokument29 SeitenFinalWebSockets Final RPiRagini GuptaNoch keine Bewertungen
- Camera PresentationDokument11 SeitenCamera PresentationRagini GuptaNoch keine Bewertungen
- 11 Publish Subscribe - FinalDokument16 Seiten11 Publish Subscribe - FinalRagini GuptaNoch keine Bewertungen
- IFTTT and Socket ProgrammingDokument4 SeitenIFTTT and Socket ProgrammingRagini GuptaNoch keine Bewertungen
- 08 Photon IOs Slides PDFDokument27 Seiten08 Photon IOs Slides PDFRagini GuptaNoch keine Bewertungen
- IoT-Based Smart HVAC Energy ManagementDokument9 SeitenIoT-Based Smart HVAC Energy ManagementRagini GuptaNoch keine Bewertungen
- 11 Output SCC Drivers PDFDokument15 Seiten11 Output SCC Drivers PDFRagini GuptaNoch keine Bewertungen
- CODE-BASED TESTING OF EXTENDED FINITE STATE MACHINE MODELSDokument36 SeitenCODE-BASED TESTING OF EXTENDED FINITE STATE MACHINE MODELSRagini GuptaNoch keine Bewertungen
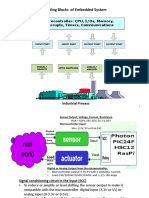
- Basic Building Blocks of Embedded System: Microcontroller: CPU, I/Os, Memory, Interrupts, Timers, CommunicationsDokument23 SeitenBasic Building Blocks of Embedded System: Microcontroller: CPU, I/Os, Memory, Interrupts, Timers, CommunicationsRagini GuptaNoch keine Bewertungen
- 241F2016 Mid2 Keys PDFDokument6 Seiten241F2016 Mid2 Keys PDFRagini GuptaNoch keine Bewertungen
- 08 Photon IOs Slides PDFDokument27 Seiten08 Photon IOs Slides PDFRagini GuptaNoch keine Bewertungen
- 241F2016 Mid2 Keys PDFDokument6 Seiten241F2016 Mid2 Keys PDFRagini GuptaNoch keine Bewertungen
- 7-Raspberry Pi Camera Interface-Final PDFDokument27 Seiten7-Raspberry Pi Camera Interface-Final PDFRagini Gupta100% (1)
- 09-Photon-Access Via Cloud PDFDokument20 Seiten09-Photon-Access Via Cloud PDFRagini GuptaNoch keine Bewertungen
- 04-Displays-KeyPad Interfacing PDFDokument35 Seiten04-Displays-KeyPad Interfacing PDFRagini GuptaNoch keine Bewertungen
- 09-Photon-Access Via Cloud PDFDokument20 Seiten09-Photon-Access Via Cloud PDFRagini GuptaNoch keine Bewertungen
- 03 Timers Slides PDFDokument69 Seiten03 Timers Slides PDFRagini GuptaNoch keine Bewertungen
- 02 PIC ADC Final PDFDokument68 Seiten02 PIC ADC Final PDFRagini GuptaNoch keine Bewertungen
- COE491 Final ReportDokument89 SeitenCOE491 Final ReportRagini GuptaNoch keine Bewertungen
- 03 Interrupts PDFDokument13 Seiten03 Interrupts PDFRagini GuptaNoch keine Bewertungen
- COE341 - Major1 - f08Dokument3 SeitenCOE341 - Major1 - f08Ragini GuptaNoch keine Bewertungen
- COE 490 Report22222Dokument64 SeitenCOE 490 Report22222Ragini GuptaNoch keine Bewertungen
- COE341 - Major2 Key - Sp09Dokument3 SeitenCOE341 - Major2 Key - Sp09Ragini GuptaNoch keine Bewertungen
- Camera PresentationDokument11 SeitenCamera PresentationRagini GuptaNoch keine Bewertungen
- COE341 - Major1 Key - Sp09Dokument4 SeitenCOE341 - Major1 Key - Sp09Ragini GuptaNoch keine Bewertungen
- COE341 - Major2 Key - f08Dokument3 SeitenCOE341 - Major2 Key - f08Ragini GuptaNoch keine Bewertungen
- Chapter 4Dokument123 SeitenChapter 4Ragini GuptaNoch keine Bewertungen
- 02-Ras Pi Intro and GPIO Interfng-ProgngDokument63 Seiten02-Ras Pi Intro and GPIO Interfng-ProgngRagini GuptaNoch keine Bewertungen
- Fuzzy Logic: Professor Electrical Engineering Department NIT DurgapurDokument57 SeitenFuzzy Logic: Professor Electrical Engineering Department NIT Durgapurravi kumarNoch keine Bewertungen
- Automata QuestionsDokument5 SeitenAutomata QuestionsYawar Sohail83% (6)
- Lexical AnalysisDokument10 SeitenLexical AnalysisFazle HannanNoch keine Bewertungen
- GenMath (Edited) - Q2 - Mod8 - Truth Values and Forms of Conditional PropositionDokument32 SeitenGenMath (Edited) - Q2 - Mod8 - Truth Values and Forms of Conditional Propositionwen maglonzoNoch keine Bewertungen
- Lex and YaccDokument70 SeitenLex and Yaccsakshi sNoch keine Bewertungen
- VAL3 V6 Quick ReferenceDokument2 SeitenVAL3 V6 Quick ReferenceFrancisco Javier Martín Gil100% (1)
- Theory of Automata Lecture 1Dokument3 SeitenTheory of Automata Lecture 1Maisa ArhamNoch keine Bewertungen
- Toc Recursive Function TheoryDokument83 SeitenToc Recursive Function TheoryTaqi ShahNoch keine Bewertungen
- Find Out The Output For The Following ProgramsDokument17 SeitenFind Out The Output For The Following ProgramsMehul PatelNoch keine Bewertungen
- Direct ProofDokument8 SeitenDirect ProofPatrick MolaerNoch keine Bewertungen
- AP Computer Science - Types and VariablesDokument3 SeitenAP Computer Science - Types and Variablesjeongcho96Noch keine Bewertungen
- Chapter 2 Logical Chain ProjectDokument1 SeiteChapter 2 Logical Chain ProjectMathBrownieNoch keine Bewertungen
- Maths Paper 2 QuestionsDokument6 SeitenMaths Paper 2 QuestionspakkuadnanNoch keine Bewertungen
- Compiler Exam Sample QuestionsDokument17 SeitenCompiler Exam Sample QuestionsABELEXNoch keine Bewertungen
- Cs 010406 Theory of ComputationDokument2 SeitenCs 010406 Theory of ComputationTaran Aulakh0% (1)
- NPTEL Compiler Design Assignment MCQDokument3 SeitenNPTEL Compiler Design Assignment MCQdheena thayalanNoch keine Bewertungen
- Lexical and Syntax Analysis: CSE 325/CSE 425: Concepts of Programming LanguageDokument41 SeitenLexical and Syntax Analysis: CSE 325/CSE 425: Concepts of Programming LanguageMd. Amdadul BariNoch keine Bewertungen
- EspressoDokument9 SeitenEspressokbkkrNoch keine Bewertungen
- Chapter 2 RegularExpressionsDokument95 SeitenChapter 2 RegularExpressionsአርቲስቶቹ Artistochu animation sitcom by habeshan memeNoch keine Bewertungen
- Expression EvaluationDokument5 SeitenExpression Evaluationtank prakashNoch keine Bewertungen
- Introduction To PEG (Parsing Expression Grammar) in PythonDokument71 SeitenIntroduction To PEG (Parsing Expression Grammar) in Pythonrwanda0% (1)
- SSCD (1) PDFDokument5 SeitenSSCD (1) PDFGaganaNoch keine Bewertungen
- Appendix F. CYK AlgorithmDokument7 SeitenAppendix F. CYK Algorithmkims3515354178Noch keine Bewertungen
- Compiler Lab ReportDokument17 SeitenCompiler Lab ReportProsenjit DasNoch keine Bewertungen
- Linz - Chapter 2 & 3 - Exer PDFDokument25 SeitenLinz - Chapter 2 & 3 - Exer PDFنغم حمدونةNoch keine Bewertungen
- Solution Aid-Chapter 01Dokument21 SeitenSolution Aid-Chapter 01Vishal ChintapalliNoch keine Bewertungen
- PropLogDiscMathDokument14 SeitenPropLogDiscMathArun kumar.NNoch keine Bewertungen
- K MapDokument32 SeitenK MapHarshit SuriNoch keine Bewertungen
- Midterm Study Sheet For CS3719 Regular Languages and Finite AutomataDokument4 SeitenMidterm Study Sheet For CS3719 Regular Languages and Finite AutomataAmitesh AroraNoch keine Bewertungen