Das könnte Ihnen auch gefallen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- American Computer Science League (ACSL) Rules and HandbookDokument47 SeitenAmerican Computer Science League (ACSL) Rules and Handbookbellataco0% (1)
- University Institute of Engg & TechDokument1 SeiteUniversity Institute of Engg & TechshamagondalNoch keine Bewertungen
- College of Information and Computing Studies: Colegio de Dagupan Dagupan CityDokument9 SeitenCollege of Information and Computing Studies: Colegio de Dagupan Dagupan CityshamagondalNoch keine Bewertungen
- Windows Kernel Internals: David B. Probert, Ph.D. Windows Kernel Development Microsoft CorporationDokument20 SeitenWindows Kernel Internals: David B. Probert, Ph.D. Windows Kernel Development Microsoft CorporationshamagondalNoch keine Bewertungen
- How To Set Up A New Printer: Power Cable and Make Sure It's Turned OnDokument7 SeitenHow To Set Up A New Printer: Power Cable and Make Sure It's Turned OnshamagondalNoch keine Bewertungen
- Project Report Core Java: Under The Guidance: Mr. Arvind KalyanDokument61 SeitenProject Report Core Java: Under The Guidance: Mr. Arvind KalyanshamagondalNoch keine Bewertungen
- To The World OF EngineersDokument14 SeitenTo The World OF EngineersshamagondalNoch keine Bewertungen
- TypingDokument1 SeiteTypingshamagondalNoch keine Bewertungen
- Participant Skills Pre / Post - Test:: Introduction To ComputersDokument4 SeitenParticipant Skills Pre / Post - Test:: Introduction To ComputersshamagondalNoch keine Bewertungen
- Steps in The Accounting Process: Ans:1 Definition of Accounting. 1: The System of Recording and SummarizingDokument9 SeitenSteps in The Accounting Process: Ans:1 Definition of Accounting. 1: The System of Recording and SummarizingshamagondalNoch keine Bewertungen
- New Resume KarvinderDokument2 SeitenNew Resume KarvindershamagondalNoch keine Bewertungen
- 1 Terms & ConditionsDokument2 Seiten1 Terms & ConditionsshamagondalNoch keine Bewertungen
- Hypervisor Overview PDFDokument2 SeitenHypervisor Overview PDFshamagondalNoch keine Bewertungen
- Tips and Notes: HTML 5Dokument3 SeitenTips and Notes: HTML 5shamagondalNoch keine Bewertungen
- Javascript Get Date Methods: Method DescriptionDokument4 SeitenJavascript Get Date Methods: Method DescriptionshamagondalNoch keine Bewertungen
- PHP Manipulating Files PHP Readfile Function: ExampleDokument2 SeitenPHP Manipulating Files PHP Readfile Function: ExampleshamagondalNoch keine Bewertungen
- Network AdmistrationDokument1 SeiteNetwork AdmistrationshamagondalNoch keine Bewertungen
- Browsing HistoryDokument207 SeitenBrowsing HistoryshamagondalNoch keine Bewertungen
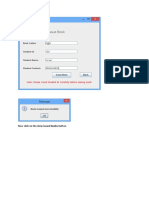
- Now Click On The View Issued Books ButtonDokument7 SeitenNow Click On The View Issued Books ButtonshamagondalNoch keine Bewertungen
- Java I/O Tutorial: StreamDokument4 SeitenJava I/O Tutorial: StreamshamagondalNoch keine Bewertungen
- Java JDBC TutorialDokument3 SeitenJava JDBC TutorialshamagondalNoch keine Bewertungen
- Java Swing Tutorial: Difference Between AWT and SwingDokument3 SeitenJava Swing Tutorial: Difference Between AWT and SwingshamagondalNoch keine Bewertungen
- Interview Preparation Best 100 Ashay RautDokument18 SeitenInterview Preparation Best 100 Ashay RautSatyendra MauryaNoch keine Bewertungen
- Stack PDFDokument752 SeitenStack PDFPrateek PatidarNoch keine Bewertungen
- 15CS252J lp2017Dokument2 Seiten15CS252J lp2017Rakesh KanneeswaranNoch keine Bewertungen
- Data Structures: Chapter 5: TreesDokument57 SeitenData Structures: Chapter 5: TreesIndark HackermenNoch keine Bewertungen
- Data Structures-TreesDokument40 SeitenData Structures-TreesMohammad Gulam Ahamad100% (2)
- Data Structure Feb18Dokument23 SeitenData Structure Feb18nisha sharmaNoch keine Bewertungen
- DSA Question BankDokument6 SeitenDSA Question BankanurekharNoch keine Bewertungen
- Sybscit 202324Dokument57 SeitenSybscit 202324Krishna KaharNoch keine Bewertungen
- DSA TreesDokument122 SeitenDSA TreesAryan JainNoch keine Bewertungen
- Crack Maang Companies - DSA Questions (C++) - 1Dokument257 SeitenCrack Maang Companies - DSA Questions (C++) - 1P MNoch keine Bewertungen
- 19ecs234 - Design and Analysis of AlgorithmsDokument4 Seiten19ecs234 - Design and Analysis of AlgorithmsNishanth NuthiNoch keine Bewertungen
- What Is A Tree: Computers"R"UsDokument5 SeitenWhat Is A Tree: Computers"R"UsshillusinghNoch keine Bewertungen
- Adsa Unit 3 &4Dokument44 SeitenAdsa Unit 3 &4Sourabh SoniNoch keine Bewertungen
- Graph Theory 0.6Dokument248 SeitenGraph Theory 0.6prasanna241186100% (1)
- 3 Binary TreesDokument115 Seiten3 Binary TreesMahesh G NayakNoch keine Bewertungen
- 300+ Algorithms MCQ PDFDokument96 Seiten300+ Algorithms MCQ PDFGulshan SinghNoch keine Bewertungen
- Binary Tree TraversalDokument10 SeitenBinary Tree TraversalShravaniSangaonkarNoch keine Bewertungen
- Leetcode 75 Questions (NeetCode On Yt)Dokument8 SeitenLeetcode 75 Questions (NeetCode On Yt)vikrram2002Noch keine Bewertungen
- CSE205 End Term Practice SetDokument7 SeitenCSE205 End Term Practice SetD StudiosNoch keine Bewertungen
- IssyllDokument138 SeitenIssyllanser pashaNoch keine Bewertungen
- M.C.a. (Sem - II) Paper - I - Data StructuresDokument132 SeitenM.C.a. (Sem - II) Paper - I - Data Structuresbaluchandrashekar2008Noch keine Bewertungen
- Sem 3Dokument84 SeitenSem 3Brijen RakholiyaNoch keine Bewertungen
- Unit 3 MCQDokument20 SeitenUnit 3 MCQ30. Suraj IngaleNoch keine Bewertungen
- DAA Unit 4Dokument24 SeitenDAA Unit 4hari karanNoch keine Bewertungen
- Adsa Au2Dokument1 SeiteAdsa Au2sridharNoch keine Bewertungen
- C Programs - C Program To Find / Print / Show / CheckDokument19 SeitenC Programs - C Program To Find / Print / Show / Checkganesh_krishna_9635Noch keine Bewertungen
- Question Bank Iii Semester BtechDokument18 SeitenQuestion Bank Iii Semester BtechHarold WilsonNoch keine Bewertungen
- Data Structure Lecture 7 TreeDokument49 SeitenData Structure Lecture 7 TreeSweetMainaNoch keine Bewertungen