Das könnte Ihnen auch gefallen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- Vijay Law Series List of Publications - 2014: SN Subject/Title Publisher Year IsbnDokument3 SeitenVijay Law Series List of Publications - 2014: SN Subject/Title Publisher Year IsbnSabya Sachee Rai0% (2)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Presentation 1Dokument8 SeitenPresentation 1chandrima das100% (1)
- SDLC Review ChecklistDokument4 SeitenSDLC Review Checklistmayank govilNoch keine Bewertungen
- Batuk EfektifDokument11 SeitenBatuk EfektifDadi ArdiansyahNoch keine Bewertungen
- Oxygen Therapy: From Wikipedia, The Free EncyclopediaDokument11 SeitenOxygen Therapy: From Wikipedia, The Free EncyclopediaDadi ArdiansyahNoch keine Bewertungen
- Jadwal Profesi NersDokument2 SeitenJadwal Profesi NersDadi ArdiansyahNoch keine Bewertungen
- Faktor-Faktor Yang Berhubungan Dengan Pemberian Asidalam Satu Jam Pertama Setelah Lahir Di Kabupaten Garut Provinsijawa BaratDokument12 SeitenFaktor-Faktor Yang Berhubungan Dengan Pemberian Asidalam Satu Jam Pertama Setelah Lahir Di Kabupaten Garut Provinsijawa BaratDadi ArdiansyahNoch keine Bewertungen
- The Correlation Between Mothers' Knowledge of Colostrum On The Provision of Colostrum in Early LactationDokument15 SeitenThe Correlation Between Mothers' Knowledge of Colostrum On The Provision of Colostrum in Early LactationDadi ArdiansyahNoch keine Bewertungen
- Little Fighter 2: Cheat ModeDokument18 SeitenLittle Fighter 2: Cheat ModeDadi ArdiansyahNoch keine Bewertungen
- Chris Baeza: ObjectiveDokument2 SeitenChris Baeza: Objectiveapi-283893712Noch keine Bewertungen
- Use of ICT in School AdministartionDokument32 SeitenUse of ICT in School AdministartionSyed Ali Haider100% (1)
- World Bank Case StudyDokument60 SeitenWorld Bank Case StudyYash DhanukaNoch keine Bewertungen
- Percussion Digital TWDokument26 SeitenPercussion Digital TWAlberto GallardoNoch keine Bewertungen
- Developing and Modifying Behavioral Coding Schemes in Pediatric Psychology: A Practical GuideDokument11 SeitenDeveloping and Modifying Behavioral Coding Schemes in Pediatric Psychology: A Practical GuideSergio A. Dávila SantanaNoch keine Bewertungen
- An Equivalent Circuit of Carbon Electrode SupercapacitorsDokument9 SeitenAn Equivalent Circuit of Carbon Electrode SupercapacitorsUsmanSSNoch keine Bewertungen
- Bonus Masters and InspiratorsDokument73 SeitenBonus Masters and InspiratorsGrosseQueue100% (1)
- Gamify Your Classroom - A Field Guide To Game-Based Learning, Revised EditionDokument372 SeitenGamify Your Classroom - A Field Guide To Game-Based Learning, Revised EditionCuong Tran VietNoch keine Bewertungen
- Tuberculosis: Still A Social DiseaseDokument3 SeitenTuberculosis: Still A Social DiseaseTercio Estudiantil FamurpNoch keine Bewertungen
- Deception With GraphsDokument7 SeitenDeception With GraphsTanmay MaityNoch keine Bewertungen
- Learning Competency: Explain The Postulates of The Cell TheoryDokument4 SeitenLearning Competency: Explain The Postulates of The Cell TheoryPamela Isabelle TabiraraNoch keine Bewertungen
- Eco - Module 1 - Unit 3Dokument8 SeitenEco - Module 1 - Unit 3Kartik PuranikNoch keine Bewertungen
- NCLEX 20QUESTIONS 20safety 20and 20infection 20controlDokument8 SeitenNCLEX 20QUESTIONS 20safety 20and 20infection 20controlCassey MillanNoch keine Bewertungen
- Pitch PDFDokument12 SeitenPitch PDFJessa Mae AnonuevoNoch keine Bewertungen
- K 46 Compact Spinning Machine Brochure 2530-V3 75220 Original English 75220Dokument28 SeitenK 46 Compact Spinning Machine Brochure 2530-V3 75220 Original English 75220Pradeep JainNoch keine Bewertungen
- Art 3-6BDokument146 SeitenArt 3-6BCJNoch keine Bewertungen
- Design & Evaluation in The Real World: Communicators & Advisory SystemsDokument13 SeitenDesign & Evaluation in The Real World: Communicators & Advisory Systemsdivya kalyaniNoch keine Bewertungen
- Second ConditionalDokument1 SeiteSecond ConditionalSilvana MiñoNoch keine Bewertungen
- Explicit and Implicit Grammar Teaching: Prepared By: Josephine Gesim & Jennifer MarcosDokument17 SeitenExplicit and Implicit Grammar Teaching: Prepared By: Josephine Gesim & Jennifer MarcosJosephine GesimNoch keine Bewertungen
- Si493b 1Dokument3 SeitenSi493b 1Sunil KhadkaNoch keine Bewertungen
- 2009FallCatalog PDFDokument57 Seiten2009FallCatalog PDFMarta LugarovNoch keine Bewertungen
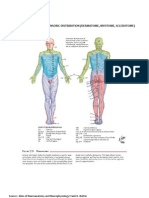
- Dermatome, Myotome, SclerotomeDokument4 SeitenDermatome, Myotome, SclerotomeElka Rifqah100% (3)
- Basic Trigonometric FunctionDokument34 SeitenBasic Trigonometric FunctionLony PatalNoch keine Bewertungen
- Week 4 CasesDokument38 SeitenWeek 4 CasesJANNNoch keine Bewertungen
- Hinog vs. MellicorDokument11 SeitenHinog vs. MellicorGreta VilarNoch keine Bewertungen
- SD OverviewDokument85 SeitenSD OverviewSamatha GantaNoch keine Bewertungen
- Sindhudurg Kokan All Tourism Spot Information WWW - Marathimann.inDokument54 SeitenSindhudurg Kokan All Tourism Spot Information WWW - Marathimann.inMarathi Mann92% (12)