Das könnte Ihnen auch gefallen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Finxter WorldsMostDensePythonCheatSheetDokument1 SeiteFinxter WorldsMostDensePythonCheatSheetmachnik1486624Noch keine Bewertungen
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (73)
- Inventory Theory (Quantitative Techniques)Dokument41 SeitenInventory Theory (Quantitative Techniques)Lexter Smith Albay100% (2)
- Construction of Perpendicular Bisector - WorksheetDokument8 SeitenConstruction of Perpendicular Bisector - Worksheetbshashi9Noch keine Bewertungen
- Lie DerivativeDokument5 SeitenLie DerivativeHrachyaKhachatryanNoch keine Bewertungen
- Mathematics Resource Package: Quarter I Subject: MATH Date: - Day: 4 Content StandardDokument7 SeitenMathematics Resource Package: Quarter I Subject: MATH Date: - Day: 4 Content Standardkris kaye morenoNoch keine Bewertungen
- 2016 - Tree Species Classification Using Hyperspectral Imagery A Comparison of Two ClassifiersDokument18 Seiten2016 - Tree Species Classification Using Hyperspectral Imagery A Comparison of Two ClassifiersMaria DimouNoch keine Bewertungen
- EnMAP-Box at ClassificationDokument10 SeitenEnMAP-Box at ClassificationMaria DimouNoch keine Bewertungen
- 2012 - Comparison of Support Vector Machine, Neural Network, and CART Algorithms For The Land-Cover Classification Using Limited Training Data PointsDokument10 Seiten2012 - Comparison of Support Vector Machine, Neural Network, and CART Algorithms For The Land-Cover Classification Using Limited Training Data PointsMaria DimouNoch keine Bewertungen
- 2 Cho2 - 2013Dokument14 Seiten2 Cho2 - 2013Maria DimouNoch keine Bewertungen
- The Stone-Cech Compactification and The Space of UltrafiltersDokument10 SeitenThe Stone-Cech Compactification and The Space of UltrafiltersJulian CanoNoch keine Bewertungen
- Combinational Logic Circuits: Reference: M. Mano, C. Kime, Dr. Costas Kyriacou and Dr. Konstantinos TatasDokument23 SeitenCombinational Logic Circuits: Reference: M. Mano, C. Kime, Dr. Costas Kyriacou and Dr. Konstantinos TatasKumar Amit VermaNoch keine Bewertungen
- Explaining Uncertainty in Nonlinear Regression ModelsDokument14 SeitenExplaining Uncertainty in Nonlinear Regression Modelsjhawner raul cruz nietoNoch keine Bewertungen
- Top 100 CodesDokument94 SeitenTop 100 CodesSURJIT VERMA100% (1)
- Class 10 Pre Mid TermDokument8 SeitenClass 10 Pre Mid TermGyan BardeNoch keine Bewertungen
- BIL113E - Introduction To Scientific and Engineering Computing (MATLAB)Dokument15 SeitenBIL113E - Introduction To Scientific and Engineering Computing (MATLAB)CodingtheWorldNoch keine Bewertungen
- Coding Theory Fundamentals ExplainedDokument49 SeitenCoding Theory Fundamentals ExplainedErica S EricaNoch keine Bewertungen
- MODULE 6 ApportionmentDokument13 SeitenMODULE 6 Apportionment3 dots . . .Noch keine Bewertungen
- GCSE Algebraic Fractions Sample QuestionsDokument5 SeitenGCSE Algebraic Fractions Sample QuestionsKryptosNoch keine Bewertungen
- Wegner F., Classical Electrodynamics (Lecture Notes, Heidelberg SDokument137 SeitenWegner F., Classical Electrodynamics (Lecture Notes, Heidelberg SAyman ElAshmawyNoch keine Bewertungen
- How We Say Numbers and Symbols in EnglishDokument7 SeitenHow We Say Numbers and Symbols in EnglishTim CooperNoch keine Bewertungen
- General Mathematics Grade11 Syllabus - PDF - Free Download PDFDokument24 SeitenGeneral Mathematics Grade11 Syllabus - PDF - Free Download PDFRenalgene G-JasmaNoch keine Bewertungen
- CH 6 CBQDokument19 SeitenCH 6 CBQPorselvi ArivazhaganNoch keine Bewertungen
- Problem Set 2 SolDokument7 SeitenProblem Set 2 SolsristisagarNoch keine Bewertungen
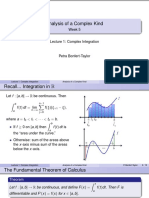
- Complex Integration PDFDokument12 SeitenComplex Integration PDFjayroldparcede100% (2)
- Studi Empiris Pada Perusahaan Pertambangan Yang Terdaftar Di BEI Periode 2014-2016Dokument15 SeitenStudi Empiris Pada Perusahaan Pertambangan Yang Terdaftar Di BEI Periode 2014-2016Yunika WindaaNoch keine Bewertungen
- Probability Homework HelpDokument22 SeitenProbability Homework HelpStatistics Homework SolverNoch keine Bewertungen
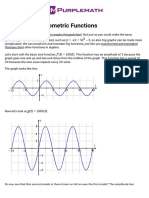
- Graphing Trigonometric Functions - Purplemath PDFDokument7 SeitenGraphing Trigonometric Functions - Purplemath PDFmatthewNoch keine Bewertungen
- Simplify/Expand/Factorise: Question Paper 3Dokument9 SeitenSimplify/Expand/Factorise: Question Paper 3Robin WongNoch keine Bewertungen
- Lecture 1 - Equations SI Units & Engineering NotationDokument40 SeitenLecture 1 - Equations SI Units & Engineering NotationhemnryNoch keine Bewertungen
- Syllabus Class III 2019 20Dokument15 SeitenSyllabus Class III 2019 20rumaroyc6007Noch keine Bewertungen
- Quantum Electrodynamics: 12.1 Gauge Invariant Interacting TheoryDokument99 SeitenQuantum Electrodynamics: 12.1 Gauge Invariant Interacting TheoryPedro SimoesNoch keine Bewertungen
- Matlab Review: Becoming Familiar With MATLABDokument13 SeitenMatlab Review: Becoming Familiar With MATLABsolteanNoch keine Bewertungen
- CMATDokument20 SeitenCMATsrk2success100% (1)
- Additional Mathematics (OCR) Specification (2011)Dokument18 SeitenAdditional Mathematics (OCR) Specification (2011)SBurnage1Noch keine Bewertungen