Das könnte Ihnen auch gefallen
- GCSE Maths Revision: Cheeky Revision ShortcutsVon EverandGCSE Maths Revision: Cheeky Revision ShortcutsBewertung: 3.5 von 5 Sternen3.5/5 (2)
- Statistics Project 17Dokument13 SeitenStatistics Project 17api-271978152Noch keine Bewertungen
- Skittles ProjectDokument9 SeitenSkittles Projectapi-252747849Noch keine Bewertungen
- Skittles Term Project 1-6Dokument10 SeitenSkittles Term Project 1-6api-284733808Noch keine Bewertungen
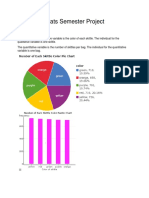
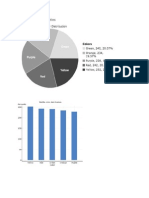
- Stats Semester ProjectDokument11 SeitenStats Semester Projectapi-276989071Noch keine Bewertungen
- Math 1040 Statistics Term Project: Blake FreemanDokument10 SeitenMath 1040 Statistics Term Project: Blake Freemanapi-252919218Noch keine Bewertungen
- Math 1040 Skittles Term ProjectDokument9 SeitenMath 1040 Skittles Term Projectapi-319881085Noch keine Bewertungen
- Kassem Hajj: Math 1040 Skittles Term ProjectDokument10 SeitenKassem Hajj: Math 1040 Skittles Term Projectapi-240347922Noch keine Bewertungen
- Emily Gregorio Skittles Project FinalDokument3 SeitenEmily Gregorio Skittles Project Finalapi-288933258Noch keine Bewertungen
- SkittlesdataclassprojectDokument8 SeitenSkittlesdataclassprojectapi-399586872Noch keine Bewertungen
- Skittles Term Project - Kai Galbiso Stat1040Dokument6 SeitenSkittles Term Project - Kai Galbiso Stat1040api-316758771Noch keine Bewertungen
- Group Project #1 - SkittlesDokument9 SeitenGroup Project #1 - Skittlesapi-245266056Noch keine Bewertungen
- Skittles Project Math 1040Dokument8 SeitenSkittles Project Math 1040api-495044194Noch keine Bewertungen
- The Skittles Project FinalDokument8 SeitenThe Skittles Project Finalapi-316760667Noch keine Bewertungen
- Comprehensive Skittles Project Math 1040Dokument7 SeitenComprehensive Skittles Project Math 1040api-316732019Noch keine Bewertungen
- Math 1040 Final ProjectDokument11 SeitenMath 1040 Final Projectapi-300784866Noch keine Bewertungen
- Skittles Term ProjectDokument10 SeitenSkittles Term Projectapi-273060240Noch keine Bewertungen
- Skittles Project Stats 1040Dokument8 SeitenSkittles Project Stats 1040api-301336765Noch keine Bewertungen
- Skittles Term Project Final PaperDokument15 SeitenSkittles Term Project Final Paperapi-339884559Noch keine Bewertungen
- Skittles Project Group Final WordDokument6 SeitenSkittles Project Group Final Wordapi-316239273Noch keine Bewertungen
- Final ProjectDokument9 SeitenFinal Projectapi-262329757Noch keine Bewertungen
- Skittles Project With ReflectionDokument7 SeitenSkittles Project With Reflectionapi-234712126100% (1)
- Skittles ProDokument9 SeitenSkittles Proapi-241124972Noch keine Bewertungen
- Skittles Eportfolio TestDokument14 SeitenSkittles Eportfolio Testapi-385819431100% (1)
- Math 1040 Skittles Term ProjectDokument10 SeitenMath 1040 Skittles Term Projectapi-310671451Noch keine Bewertungen
- Skittles ProjectDokument9 SeitenSkittles Projectapi-242873849Noch keine Bewertungen
- Skittles Proyect Part 5Dokument7 SeitenSkittles Proyect Part 5api-509398997Noch keine Bewertungen
- Skittles ProjectDokument5 SeitenSkittles Projectapi-271444168Noch keine Bewertungen
- Skittles Project 5-02Dokument8 SeitenSkittles Project 5-02api-354040698Noch keine Bewertungen
- The Rainbow ReportDokument11 SeitenThe Rainbow Reportapi-316991888Noch keine Bewertungen
- Skittles Project 1Dokument7 SeitenSkittles Project 1api-299868669100% (2)
- Math 1040 Skittles Term Project EportfolioDokument7 SeitenMath 1040 Skittles Term Project Eportfolioapi-260817278Noch keine Bewertungen
- Math 1040Dokument3 SeitenMath 1040api-342333328Noch keine Bewertungen
- Final Math ProjectDokument7 SeitenFinal Math Projectapi-316775963Noch keine Bewertungen
- Final ProjectDokument6 SeitenFinal Projectapi-283261340Noch keine Bewertungen
- Skittles ProjectDokument6 SeitenSkittles Projectapi-495018964Noch keine Bewertungen
- Skittles ProjectDokument6 SeitenSkittles Projectapi-319345408Noch keine Bewertungen
- Skittles Project 2Dokument10 SeitenSkittles Project 2api-316655135Noch keine Bewertungen
- Term Project - EportfolioDokument7 SeitenTerm Project - Eportfolioapi-251981709Noch keine Bewertungen
- Statistics Term Project E-Portfolio ReflectionDokument8 SeitenStatistics Term Project E-Portfolio Reflectionapi-258147701Noch keine Bewertungen
- Skittles ProjectDokument4 SeitenSkittles Projectapi-287735026Noch keine Bewertungen
- Math 1040 Skittles Term ProjectDokument8 SeitenMath 1040 Skittles Term Projectapi-272870073Noch keine Bewertungen
- Term Project Part 8Dokument9 SeitenTerm Project Part 8api-242224172Noch keine Bewertungen
- Full Skittles ProjectDokument13 SeitenFull Skittles Projectapi-537189505Noch keine Bewertungen
- Sanela Sakic 4/18/19: Total: 2,584 Candies (Sample Size)Dokument7 SeitenSanela Sakic 4/18/19: Total: 2,584 Candies (Sample Size)api-340495387Noch keine Bewertungen
- Statistics Final Project Summer Semester 2016Dokument17 SeitenStatistics Final Project Summer Semester 2016api-295161880Noch keine Bewertungen
- Math 1040Dokument5 SeitenMath 1040api-534403229Noch keine Bewertungen
- Term Project ReportDokument9 SeitenTerm Project Reportapi-238585685Noch keine Bewertungen
- Skittles ReportDokument15 SeitenSkittles Reportapi-271901299Noch keine Bewertungen
- TP 2 StatsDokument5 SeitenTP 2 Statsapi-240850453Noch keine Bewertungen
- Term Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1Dokument8 SeitenTerm Project Part 5 Compile Term Project Reflection and Eportfolio Posting 1api-303044832Noch keine Bewertungen
- Math ProfileDokument9 SeitenMath Profileapi-454376679Noch keine Bewertungen
- Skittles Project Math 1030Dokument9 SeitenSkittles Project Math 1030api-305867098Noch keine Bewertungen
- 7.1 HworkDokument7 Seiten7.1 Hworkkingbball249Noch keine Bewertungen
- Skittle Project FinalDokument6 SeitenSkittle Project Finalapi-252859182Noch keine Bewertungen
- Skittles Project FinalDokument5 SeitenSkittles Project Finalapi-271348941Noch keine Bewertungen
- Skittles ProjectDokument5 SeitenSkittles Projectapi-441660843Noch keine Bewertungen
- Math 1040 Skittles Term Project AynoaDokument15 SeitenMath 1040 Skittles Term Project Aynoaapi-301347675Noch keine Bewertungen
- Skittles 2 FinalDokument12 SeitenSkittles 2 Finalapi-242194552Noch keine Bewertungen
- Registration ListDokument5 SeitenRegistration ListGnanesh Shetty BharathipuraNoch keine Bewertungen
- (Sat) - 072023Dokument7 Seiten(Sat) - 072023DhananjayPatelNoch keine Bewertungen
- SEILDokument4 SeitenSEILGopal RamalingamNoch keine Bewertungen
- Sundar Pichai PDFDokument6 SeitenSundar Pichai PDFHimanshi Patle100% (1)
- Teaching Trigonometry Using Empirical Modelling: 2.1 Visual Over Verbal LearningDokument5 SeitenTeaching Trigonometry Using Empirical Modelling: 2.1 Visual Over Verbal LearningJeffrey Cariaga Reclamado IINoch keine Bewertungen
- Debate ReportDokument15 SeitenDebate Reportapi-435309716Noch keine Bewertungen
- Lab 3 Arduino Led Candle Light: CS 11/group - 4 - Borromeo, Galanida, Pabilan, Paypa, TejeroDokument3 SeitenLab 3 Arduino Led Candle Light: CS 11/group - 4 - Borromeo, Galanida, Pabilan, Paypa, TejeroGladys Ruth PaypaNoch keine Bewertungen
- The New Order of BarbariansDokument39 SeitenThe New Order of Barbariansbadguy100% (1)
- Song Book Inner PagesDokument140 SeitenSong Book Inner PagesEliazer PetsonNoch keine Bewertungen
- Johnson & Johnson Equity Research ReportDokument13 SeitenJohnson & Johnson Equity Research ReportPraveen R V100% (3)
- NAV SOLVING PROBLEM 3 (1-20) .PpsDokument37 SeitenNAV SOLVING PROBLEM 3 (1-20) .Ppsmsk5in100% (1)
- 8 A - 1615864446 - 1605148379 - 1579835163 - Topic - 8.A.EffectiveSchoolsDokument9 Seiten8 A - 1615864446 - 1605148379 - 1579835163 - Topic - 8.A.EffectiveSchoolsYasodhara ArawwawelaNoch keine Bewertungen
- Maths Formulas For IGCSEDokument2 SeitenMaths Formulas For IGCSEHikma100% (1)
- Iguard® LM SeriesDokument82 SeitenIguard® LM SeriesImran ShahidNoch keine Bewertungen
- 10 1108 - TQM 03 2020 0066 PDFDokument23 Seiten10 1108 - TQM 03 2020 0066 PDFLejandra MNoch keine Bewertungen
- 11.3.1 Some Special CasesDokument10 Seiten11.3.1 Some Special CasesSiddharth KishanNoch keine Bewertungen
- Leadership and Management in Different Arts FieldsDokument10 SeitenLeadership and Management in Different Arts Fieldsjay jayNoch keine Bewertungen
- Ch-10 Human Eye Notes FinalDokument27 SeitenCh-10 Human Eye Notes Finalkilemas494Noch keine Bewertungen
- Optimized Maximum Power Point Tracker For Fast Changing Environmental ConditionsDokument7 SeitenOptimized Maximum Power Point Tracker For Fast Changing Environmental ConditionsSheri ShahiNoch keine Bewertungen
- The Ovation E-Amp: A 180 W High-Fidelity Audio Power AmplifierDokument61 SeitenThe Ovation E-Amp: A 180 W High-Fidelity Audio Power AmplifierNini Farribas100% (1)
- Design of Reinforced Cement Concrete ElementsDokument14 SeitenDesign of Reinforced Cement Concrete ElementsSudeesh M SNoch keine Bewertungen
- Central University of Karnataka: Entrance Examinations Results 2016Dokument4 SeitenCentral University of Karnataka: Entrance Examinations Results 2016Saurabh ShubhamNoch keine Bewertungen
- Smartfind E5 g5 User ManualDokument49 SeitenSmartfind E5 g5 User ManualdrewlioNoch keine Bewertungen
- Derma Notes 22pages. DR - Vishwa Medical CoachingDokument23 SeitenDerma Notes 22pages. DR - Vishwa Medical CoachingΝίκος ΣυρίγοςNoch keine Bewertungen
- Zomato Restaurant Clustering & Sentiment Analysis - Ipynb - ColaboratoryDokument27 SeitenZomato Restaurant Clustering & Sentiment Analysis - Ipynb - Colaboratorybilal nagoriNoch keine Bewertungen
- A P P E N D I X Powers of Ten and Scientific NotationDokument5 SeitenA P P E N D I X Powers of Ten and Scientific NotationAnthony BensonNoch keine Bewertungen
- D25KS Sanvick PDFDokument4 SeitenD25KS Sanvick PDFJiménez Manuel100% (1)
- Jul - Dec 09Dokument8 SeitenJul - Dec 09dmaizulNoch keine Bewertungen
- 2500 Valve BrochureDokument12 Seiten2500 Valve BrochureJurie_sk3608Noch keine Bewertungen
- Grade 8 Science - Second GradingDokument5 SeitenGrade 8 Science - Second GradingMykelCañete0% (1)