Das könnte Ihnen auch gefallen
- WestbyDokument3 SeitenWestbyEllyn Grace100% (1)
- Environmental and Ecological Statistics With R - Qian PDFDokument433 SeitenEnvironmental and Ecological Statistics With R - Qian PDFAni VulloNoch keine Bewertungen
- OOSE Course OutlineDokument2 SeitenOOSE Course OutlinemadhunathNoch keine Bewertungen
- Understanding Service Convenience.Dokument18 SeitenUnderstanding Service Convenience.Jose Antonio Alvizo FloresNoch keine Bewertungen
- The Relationship of Intellectual Capital, Knowledge Sharing and Innovation On Organizational Performance of Malaysia's Small and Medium EnterprisesDokument377 SeitenThe Relationship of Intellectual Capital, Knowledge Sharing and Innovation On Organizational Performance of Malaysia's Small and Medium EnterprisesDrRohana100% (1)
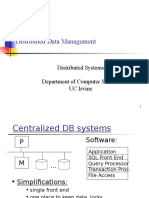
- Distributed DBDokument146 SeitenDistributed DBAnonymous jLw94L1SNoch keine Bewertungen
- Ddbms 1Dokument19 SeitenDdbms 1Kuldeep SharmaNoch keine Bewertungen
- FinalDokument46 SeitenFinalVinod KumarNoch keine Bewertungen
- Distributed Database ConceptsDokument52 SeitenDistributed Database ConceptsJoel wakhunguNoch keine Bewertungen
- Top Down DesignDokument4 SeitenTop Down DesignSaim JamilNoch keine Bewertungen
- Unit 1 DISTRIBUTED DATABASEDokument6 SeitenUnit 1 DISTRIBUTED DATABASEvikas babu gondNoch keine Bewertungen
- DDS5 DesignDokument89 SeitenDDS5 DesignTahseen HassanNoch keine Bewertungen
- Distributed DBMS Architecture 5. Distributed Database Design 7.5 Layers of Query ProcessingDokument19 SeitenDistributed DBMS Architecture 5. Distributed Database Design 7.5 Layers of Query ProcessingRahul SureshNoch keine Bewertungen
- Reviewer - FDBSDokument6 SeitenReviewer - FDBSlimariokun02Noch keine Bewertungen
- Distributed Database Design 3rd AssignmentDokument22 SeitenDistributed Database Design 3rd AssignmentAmit Vashisht100% (2)
- Lecture 4dbDokument14 SeitenLecture 4dbmohsin dishNoch keine Bewertungen
- Mapping The Data Warehouse Architecture To Multiprocessor ArchitectureDokument15 SeitenMapping The Data Warehouse Architecture To Multiprocessor ArchitectureS.Srinidhi sandoshkumarNoch keine Bewertungen
- Distributed DBMS ArchitectureDokument49 SeitenDistributed DBMS ArchitectureMahboobNoch keine Bewertungen
- Top Down Database DesignDokument4 SeitenTop Down Database Designukesh123Noch keine Bewertungen
- Database Management System (DBMS)Dokument22 SeitenDatabase Management System (DBMS)salma zonnonNoch keine Bewertungen
- Unit-V Distributed and Client Server Databases: A Lalitha Associate Professor Avinash Degree CollegeDokument24 SeitenUnit-V Distributed and Client Server Databases: A Lalitha Associate Professor Avinash Degree CollegelalithaNoch keine Bewertungen
- On The Exam We Can Have 1 Cheat Sheet: Blg/Edit?Usp SharingDokument40 SeitenOn The Exam We Can Have 1 Cheat Sheet: Blg/Edit?Usp SharingĐorđe KlisuraNoch keine Bewertungen
- 8-Distributed DatabaseDokument22 Seiten8-Distributed DatabaseSabuj DhaliNoch keine Bewertungen
- Veritabanı Yönetim Sistemleri YZM508: Dr. Osman GÖKALPDokument49 SeitenVeritabanı Yönetim Sistemleri YZM508: Dr. Osman GÖKALPolcayto krocanNoch keine Bewertungen
- Distributed Databases: Rohini College of Engineering & TechnologyDokument5 SeitenDistributed Databases: Rohini College of Engineering & TechnologymentalinsideNoch keine Bewertungen
- Lec 3Dokument22 SeitenLec 3Rifky AhmedNoch keine Bewertungen
- Basis For Distributed Database TechnologyDokument35 SeitenBasis For Distributed Database TechnologyRavali SrirangamNoch keine Bewertungen
- CS8492-Database Management Systems-UNIT 5Dokument20 SeitenCS8492-Database Management Systems-UNIT 5Mary James100% (1)
- U19EE007 PeemdDokument14 SeitenU19EE007 PeemdRITIK NILESH DESAI SVNITNoch keine Bewertungen
- M.C.a. (Sem - IV) Paper - IV - Adavanced Database TechniquesDokument114 SeitenM.C.a. (Sem - IV) Paper - IV - Adavanced Database TechniquesSandeep BindNoch keine Bewertungen
- Architecture of Distributed Data Base SystemsDokument19 SeitenArchitecture of Distributed Data Base SystemsRedha22Noch keine Bewertungen
- Lecture 3 - BCSE302L - DBMS ArchitectureDokument17 SeitenLecture 3 - BCSE302L - DBMS Architecturebojon27556Noch keine Bewertungen
- Introduction To Database Management System: Poonam MehtaDokument21 SeitenIntroduction To Database Management System: Poonam Mehtacyka blyatNoch keine Bewertungen
- Q # 1: What Are The Components of Distributed Database System? Explain With The Help of A Diagram. AnswerDokument12 SeitenQ # 1: What Are The Components of Distributed Database System? Explain With The Help of A Diagram. AnswerAqab ButtNoch keine Bewertungen
- Database System Environment: D Mukherjee Assistant Professor - IT AreaDokument22 SeitenDatabase System Environment: D Mukherjee Assistant Professor - IT AreaRishi SinghNoch keine Bewertungen
- Assignment # 2: Submitted by Submitted To Class Semester Roll NoDokument9 SeitenAssignment # 2: Submitted by Submitted To Class Semester Roll NoNABEEL BHATTINoch keine Bewertungen
- Lecture 2 DbmsDokument26 SeitenLecture 2 DbmsMohd AhadNoch keine Bewertungen
- Unit 2Dokument73 SeitenUnit 2rajapstNoch keine Bewertungen
- Unit IDokument51 SeitenUnit ISoham MahajanNoch keine Bewertungen
- BSE1123/CS253 - Database/Databases: Chapter 2 - Database Architecture & Conceptual Data ModelsDokument30 SeitenBSE1123/CS253 - Database/Databases: Chapter 2 - Database Architecture & Conceptual Data ModelsYashiniNoch keine Bewertungen
- Database System Concepts and ArchitectureDokument24 SeitenDatabase System Concepts and ArchitecturesudishettNoch keine Bewertungen
- Unit - 1 Part 2Dokument14 SeitenUnit - 1 Part 2krushitghevariya41Noch keine Bewertungen
- Database System Concepts and Architecture: Chapter - 2Dokument45 SeitenDatabase System Concepts and Architecture: Chapter - 2VIJAYNoch keine Bewertungen
- Introduction To DBMSDokument29 SeitenIntroduction To DBMSMeera SuryaNoch keine Bewertungen
- DDB SlidesDokument67 SeitenDDB SlidesyNoch keine Bewertungen
- Assignment # 1: Submitted by Submitted To Class Semester Roll NoDokument15 SeitenAssignment # 1: Submitted by Submitted To Class Semester Roll NoNABEEL BHATTINoch keine Bewertungen
- Distributed Database Design ConceptDokument5 SeitenDistributed Database Design ConceptArghya ChowdhuryNoch keine Bewertungen
- Mod 4Dokument45 SeitenMod 4Minu PouloseNoch keine Bewertungen
- New Techniques For Database FragmentationDokument5 SeitenNew Techniques For Database FragmentationKidusNoch keine Bewertungen
- FALLSEM2020-21 ITE1003 ETH VL2020210105050 Reference Material I 15-Jul-2020 Module 1 - Database Systems Concepts ArchitectureDokument31 SeitenFALLSEM2020-21 ITE1003 ETH VL2020210105050 Reference Material I 15-Jul-2020 Module 1 - Database Systems Concepts ArchitectureSaji JosephNoch keine Bewertungen
- 2 - Database Users and ModelsDokument17 Seiten2 - Database Users and ModelsMona Nashaat Ali ElmowafyNoch keine Bewertungen
- Distributed Database Management Systems (DDBMS) : Muhammad Hamiz Mohd Radzi Faiqah Hafidzah HalimDokument62 SeitenDistributed Database Management Systems (DDBMS) : Muhammad Hamiz Mohd Radzi Faiqah Hafidzah HalimAmmr AmnNoch keine Bewertungen
- DBMS Basics: Dr. Rajesh ChauhanDokument56 SeitenDBMS Basics: Dr. Rajesh Chauhanarti sharmaNoch keine Bewertungen
- DDS Lecture 2Dokument38 SeitenDDS Lecture 2SajjadAbdullah0% (1)
- Distributed DatabaseDokument98 SeitenDistributed DatabaselorNoch keine Bewertungen
- CSE Database Management SystemDokument23 SeitenCSE Database Management SystemAKHIL RAJNoch keine Bewertungen
- Distributed Database Management SystemsDokument123 SeitenDistributed Database Management SystemsMaryamNoch keine Bewertungen
- Types of Distributed Databases.: Homogeneous Distributed Databases System Heterogeneous Distributed Database SystemDokument22 SeitenTypes of Distributed Databases.: Homogeneous Distributed Databases System Heterogeneous Distributed Database SystemAdiba khanNoch keine Bewertungen
- Unit-1 Introduction To DDBMSDokument50 SeitenUnit-1 Introduction To DDBMSKeshav SharmaNoch keine Bewertungen
- Databases and Database Management Systems: (Based On Chapters 1-2 in Fundamentals ofDokument35 SeitenDatabases and Database Management Systems: (Based On Chapters 1-2 in Fundamentals ofcyka blyatNoch keine Bewertungen
- 1 Distributed DBDokument67 Seiten1 Distributed DBShreeharsha SNoch keine Bewertungen
- CH 1 232815Dokument44 SeitenCH 1 232815jj kjegrNoch keine Bewertungen
- Csedatabasemanagementsystemppt-170825044344 DSDSDDokument23 SeitenCsedatabasemanagementsystemppt-170825044344 DSDSDRaj KundraNoch keine Bewertungen
- SAS Programming Guidelines Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesVon EverandSAS Programming Guidelines Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNoch keine Bewertungen
- Multicore Software Development Techniques: Applications, Tips, and TricksVon EverandMulticore Software Development Techniques: Applications, Tips, and TricksBewertung: 2.5 von 5 Sternen2.5/5 (2)
- Software Reuse: CSC 532 Term PaperDokument11 SeitenSoftware Reuse: CSC 532 Term PapermadhunathNoch keine Bewertungen
- Version Control:: Else If (I%2 1) Write (" ..Red!") Else If (I%2 2) Write (" Blue!") End AnsDokument3 SeitenVersion Control:: Else If (I%2 1) Write (" ..Red!") Else If (I%2 2) Write (" Blue!") End AnsmadhunathNoch keine Bewertungen
- A-Z Windows CMD Commands ListDokument18 SeitenA-Z Windows CMD Commands ListmadhunathNoch keine Bewertungen
- Netework Architecture of 5G Mobile TechnologyDokument21 SeitenNetework Architecture of 5G Mobile Technologymadhunath0% (1)
- Finite State Machines: Chapter 11 - Sequential CircuitsDokument12 SeitenFinite State Machines: Chapter 11 - Sequential CircuitsmadhunathNoch keine Bewertungen
- Q. Identify The Difference Between FSM and FSA. Describe Their Functional Workings, Characteristics and ApplicationsDokument59 SeitenQ. Identify The Difference Between FSM and FSA. Describe Their Functional Workings, Characteristics and ApplicationsmadhunathNoch keine Bewertungen
- Bézier Surface (In 3D) : Paul BourkeDokument12 SeitenBézier Surface (In 3D) : Paul BourkemadhunathNoch keine Bewertungen
- Modern English Vocabulary: Acquire To Get Ownership, To Gain Through EffortDokument22 SeitenModern English Vocabulary: Acquire To Get Ownership, To Gain Through EffortmadhunathNoch keine Bewertungen
- Modern English Vocabulary: Acquire To Get Ownership, To Gain Through EffortDokument49 SeitenModern English Vocabulary: Acquire To Get Ownership, To Gain Through EffortmadhunathNoch keine Bewertungen
- To Collect SFP Information: StepsDokument2 SeitenTo Collect SFP Information: StepsmadhunathNoch keine Bewertungen
- Ip ConfigDokument2 SeitenIp ConfigmadhunathNoch keine Bewertungen
- Mid-Term Mid-Term: Practicable in Their Own Words. Practicable in Their Own WordsDokument1 SeiteMid-Term Mid-Term: Practicable in Their Own Words. Practicable in Their Own WordsmadhunathNoch keine Bewertungen
- Mid-Term: Practicable in Their Own WordsDokument2 SeitenMid-Term: Practicable in Their Own WordsmadhunathNoch keine Bewertungen
- PM Card-20170731 - New LatestDokument4 SeitenPM Card-20170731 - New LatestmadhunathNoch keine Bewertungen
- Call Flow.Dokument19 SeitenCall Flow.madhunathNoch keine Bewertungen
- Theory of Computation - AllDokument7 SeitenTheory of Computation - AllmadhunathNoch keine Bewertungen
- Question TOCDokument6 SeitenQuestion TOCmadhunathNoch keine Bewertungen
- Production and Operations ManagementDokument284 SeitenProduction and Operations Managementsnehal.deshmukh89% (28)
- Mobile and Wireless Communication - AllDokument12 SeitenMobile and Wireless Communication - AllmadhunathNoch keine Bewertungen
- History of DatabasesDokument9 SeitenHistory of Databaseskira3003Noch keine Bewertungen
- Modflow - Conceptual Model Approach 2: GMS 10.4 TutorialDokument13 SeitenModflow - Conceptual Model Approach 2: GMS 10.4 TutorialYetzabel FloresNoch keine Bewertungen
- Arsrv14 N1 P17 37Dokument20 SeitenArsrv14 N1 P17 37Ikin NoraNoch keine Bewertungen
- 10 Key Skills Architects PDFDokument21 Seiten10 Key Skills Architects PDFAmgad AlsisiNoch keine Bewertungen
- Review of Related Literature of Home Security SystemDokument6 SeitenReview of Related Literature of Home Security SystemafdtfgkbvNoch keine Bewertungen
- Project Guidline ModifiedDokument26 SeitenProject Guidline ModifiedBarnabas UdehNoch keine Bewertungen
- Siemens SW Model Based Systems Engineering To Model Based E - E Architecture WP - tcm27 109079Dokument10 SeitenSiemens SW Model Based Systems Engineering To Model Based E - E Architecture WP - tcm27 109079beto rodriguezNoch keine Bewertungen
- OO Concept Chapt3 Part2 (deeperViewOfUML)Dokument62 SeitenOO Concept Chapt3 Part2 (deeperViewOfUML)scodrashNoch keine Bewertungen
- Chapter ThreeDokument25 SeitenChapter ThreeAdetokun AjomaleNoch keine Bewertungen
- Chapter 1-2Dokument32 SeitenChapter 1-2MohammedNoch keine Bewertungen
- Reflection On Curriculum IntegrationDokument4 SeitenReflection On Curriculum Integrationapi-9904287950% (2)
- Summary of The Journal Paper "A Literature Review On Models On Inventory Management Under Uncertainty"Dokument1 SeiteSummary of The Journal Paper "A Literature Review On Models On Inventory Management Under Uncertainty"wasil0309Noch keine Bewertungen
- Appropriate Budget Contingency Determination For Construction Projects: State-Of-The-ArtDokument16 SeitenAppropriate Budget Contingency Determination For Construction Projects: State-Of-The-ArtTaher AmmarNoch keine Bewertungen
- IBM Industry Data Models - Netezza Whitepaper v1.2Dokument13 SeitenIBM Industry Data Models - Netezza Whitepaper v1.2vasurajeshNoch keine Bewertungen
- Angela Verano MC MATH 15 Module 1Dokument12 SeitenAngela Verano MC MATH 15 Module 1AN GE LANoch keine Bewertungen
- Export MarketingDokument17 SeitenExport MarketingKatarina TešićNoch keine Bewertungen
- ADokument10 SeitenASana GhadiehNoch keine Bewertungen
- Systems Analysis and Modeling of Integrated World SystemsDokument11 SeitenSystems Analysis and Modeling of Integrated World SystemsDejonesNoch keine Bewertungen
- Stakeholder-Viewpoint Matrix (TOGAF 9.2 Sample Using ArchiMate 3.0)Dokument10 SeitenStakeholder-Viewpoint Matrix (TOGAF 9.2 Sample Using ArchiMate 3.0)Rabie' TanashNoch keine Bewertungen
- HND Sector 4 Vol7 Software - 105540Dokument55 SeitenHND Sector 4 Vol7 Software - 105540Ewi BenardNoch keine Bewertungen
- Sap - HR HCM PDFDokument6 SeitenSap - HR HCM PDFŁuisŠantiváñezNoch keine Bewertungen
- Thesis OriginalDokument51 SeitenThesis OriginalJoana Marie PabloNoch keine Bewertungen
- It 05102 AiDokument19 SeitenIt 05102 AiPiu BasuNoch keine Bewertungen
- Object-Oriented Modeling and Design With UML, 2nd EditionDokument501 SeitenObject-Oriented Modeling and Design With UML, 2nd EditionUmar Jawad100% (1)
- Unified Modeling Language (Uml) : AssignmentDokument32 SeitenUnified Modeling Language (Uml) : AssignmentM khawarNoch keine Bewertungen
- Maria Butucea Philosophy of Science and Educational Sciences - Models of ExplanationDokument6 SeitenMaria Butucea Philosophy of Science and Educational Sciences - Models of ExplanationAgung Yuwono AhmNoch keine Bewertungen