Das könnte Ihnen auch gefallen
- Official Statistics 4.0: Verified Facts for People in the 21st CenturyVon EverandOfficial Statistics 4.0: Verified Facts for People in the 21st CenturyNoch keine Bewertungen
- RegistersDokument13 SeitenRegistersRoman TilahunNoch keine Bewertungen
- Standard-Documentation Meta Information: (Definitions, Comments, Methods, Quality)Dokument4 SeitenStandard-Documentation Meta Information: (Definitions, Comments, Methods, Quality)AmerNoch keine Bewertungen
- Ices2007 000077Dokument6 SeitenIces2007 000077Zulhan Andika AsyrafNoch keine Bewertungen
- The Use of Administrative Data in Official StatistDokument20 SeitenThe Use of Administrative Data in Official StatistTyas KurniaNoch keine Bewertungen
- Civil Service Statistics QMIDokument11 SeitenCivil Service Statistics QMIPrexyNoch keine Bewertungen
- Antigua and Barbuda Population Census 2014Dokument181 SeitenAntigua and Barbuda Population Census 2014J'Moul A. FrancisNoch keine Bewertungen
- About Us: A) Primary SourceDokument48 SeitenAbout Us: A) Primary SourceAttaNoch keine Bewertungen
- Análisis Longitudinal Utilizando El Registro de Empresas BLSDokument7 SeitenAnálisis Longitudinal Utilizando El Registro de Empresas BLSraul jonathan palomino ocampoNoch keine Bewertungen
- Measuring Service Utilities in Service Value NetworksDokument26 SeitenMeasuring Service Utilities in Service Value NetworksJinluan RenNoch keine Bewertungen
- Three Dimensions of Organizational InteroperabilityDokument12 SeitenThree Dimensions of Organizational InteroperabilityJosé MªNoch keine Bewertungen
- TanauanDokument22 SeitenTanauannonname713Noch keine Bewertungen
- Linguistic Summaries Applied On Statistics - Case of Municipal StatisticsDokument13 SeitenLinguistic Summaries Applied On Statistics - Case of Municipal StatisticsMohamed ZizoNoch keine Bewertungen
- Succesful ProjectsDokument52 SeitenSuccesful ProjectsabasNoch keine Bewertungen
- Completeness and Accuracy of Data in Spine Registries An Independent Auditbased Studyeuropean Spine JournalDokument9 SeitenCompleteness and Accuracy of Data in Spine Registries An Independent Auditbased Studyeuropean Spine JournalAngga SmNoch keine Bewertungen
- 1 ListDokument16 Seiten1 ListSanjay KoriNoch keine Bewertungen
- Lecture 4Dokument18 SeitenLecture 4Hajra AhmadNoch keine Bewertungen
- Exports and Imports in The Philippine System of National Accounts (PSNA)Dokument24 SeitenExports and Imports in The Philippine System of National Accounts (PSNA)carloNoch keine Bewertungen
- 5/30/2011 1 Mis, Iipm, DelhiDokument23 Seiten5/30/2011 1 Mis, Iipm, DelhiVishal SharmaNoch keine Bewertungen
- 00 Anderson 2017 Very Good Idea For Profile ComparisonDokument10 Seiten00 Anderson 2017 Very Good Idea For Profile Comparisonkmlhectorseth94Noch keine Bewertungen
- IACP PerpectivesDokument2 SeitenIACP PerpectivesdaggerpressNoch keine Bewertungen
- Toward Effective Big Data Analysis in Continuous Auditing: Accounting Horizons February 2015Dokument9 SeitenToward Effective Big Data Analysis in Continuous Auditing: Accounting Horizons February 2015hary daniel sianiparNoch keine Bewertungen
- Firm Size, Business Sector and Quality of Accounting Information SystemDokument8 SeitenFirm Size, Business Sector and Quality of Accounting Information SystemHoàng AnhNoch keine Bewertungen
- Baldwin Et Al 2006 ABS1 XBRL IntermediariesDokument21 SeitenBaldwin Et Al 2006 ABS1 XBRL IntermediariesEsraa S AlkhatibNoch keine Bewertungen
- 1 s2.0 S2352340918315191 MainDokument14 Seiten1 s2.0 S2352340918315191 MainLaik MuhamadNoch keine Bewertungen
- 3 4 6a Short Term Statistics Surveys IIIa Construction Iannaccone NielsenDokument12 Seiten3 4 6a Short Term Statistics Surveys IIIa Construction Iannaccone NielsendobroslavNoch keine Bewertungen
- Presentasi Big Data Analytics - Group 8Dokument32 SeitenPresentasi Big Data Analytics - Group 8IloNoch keine Bewertungen
- Sources of Error in Survey and Administrative Data - Importance of Reporting ProcedureDokument26 SeitenSources of Error in Survey and Administrative Data - Importance of Reporting ProcedureFIZQI ALFAIRUZNoch keine Bewertungen
- Estimating Impact of Infrastructure On Productivity and Efficiency of Indian ManufacturingDokument6 SeitenEstimating Impact of Infrastructure On Productivity and Efficiency of Indian ManufacturingJuanrami918Noch keine Bewertungen
- Resume Big Data Analytics - Group 8Dokument12 SeitenResume Big Data Analytics - Group 8IloNoch keine Bewertungen
- Unit 8Dokument16 SeitenUnit 8DEEPAK SHARMANoch keine Bewertungen
- THE IMPACT OF (IT) ON THE QUALITY of Finan Data - MunicipalitiesDokument7 SeitenTHE IMPACT OF (IT) ON THE QUALITY of Finan Data - MunicipalitiesbilaldboukNoch keine Bewertungen
- Prevention of Money-Laundering and Fiscal Fraud: The BRACCO ProjectDokument41 SeitenPrevention of Money-Laundering and Fiscal Fraud: The BRACCO Projectmyselfandme0Noch keine Bewertungen
- CARRA PVS Record LinkageDokument23 SeitenCARRA PVS Record LinkagePiNoch keine Bewertungen
- Images Letterfromsirandrewdilnottomatthewhancockmp2407201 Tcm97 43942Dokument5 SeitenImages Letterfromsirandrewdilnottomatthewhancockmp2407201 Tcm97 43942AllieWickhamNoch keine Bewertungen
- User Guide To PWT 9.1 Data Files 1Dokument4 SeitenUser Guide To PWT 9.1 Data Files 1Diana CañasNoch keine Bewertungen
- SOAR Modeling Team Progress Report 11082014Dokument20 SeitenSOAR Modeling Team Progress Report 11082014shawwnnnNoch keine Bewertungen
- Pes Manual - UnDokument114 SeitenPes Manual - UnbudyanraNoch keine Bewertungen
- Globalisation in Services: OECD Statistics Working Papers 2008/03Dokument38 SeitenGlobalisation in Services: OECD Statistics Working Papers 2008/03ponce jeraldoNoch keine Bewertungen
- Intellectual AccountingDokument12 SeitenIntellectual AccountingazizNoch keine Bewertungen
- Costos Ingenieria ClínicaDokument4 SeitenCostos Ingenieria ClínicaMauricio AndradeNoch keine Bewertungen
- Measurement of Unrecorded EconomyDokument3 SeitenMeasurement of Unrecorded EconomyLigaya ValmonteNoch keine Bewertungen
- Paper 4Dokument61 SeitenPaper 4Anonymous XIwe3KKNoch keine Bewertungen
- Fin Ac SysDokument4 SeitenFin Ac Syslion009Noch keine Bewertungen
- Boritz and No 2008 ABS 2 XBRL AuditingDokument16 SeitenBoritz and No 2008 ABS 2 XBRL AuditingEsraa S AlkhatibNoch keine Bewertungen
- Industry-Level Expenditure On Intangible Assets in The UK : Haskel@ic - Ac.ukDokument54 SeitenIndustry-Level Expenditure On Intangible Assets in The UK : Haskel@ic - Ac.ukAndry YadisaputraNoch keine Bewertungen
- Input-Output-based Life Cycle Inventory: Development and Validation of A Database For The German Building SectorDokument13 SeitenInput-Output-based Life Cycle Inventory: Development and Validation of A Database For The German Building SectorAnonymous LEVNDh4Noch keine Bewertungen
- A Field Study On The Use of Process Mining of Event Logs As An Analytical Procedure in AuditingDokument23 SeitenA Field Study On The Use of Process Mining of Event Logs As An Analytical Procedure in AuditingNazmiye Ugurlu (NL)Noch keine Bewertungen
- Corporate Carbon Performance Data Quo VadisDokument14 SeitenCorporate Carbon Performance Data Quo VadisVikram ParmarNoch keine Bewertungen
- Scale-Adjusted Metrics For Predicting The Evolution of Urban Indicators and Quantifying The Performance of CitiesDokument28 SeitenScale-Adjusted Metrics For Predicting The Evolution of Urban Indicators and Quantifying The Performance of CitiesVânia Raposo de MouraNoch keine Bewertungen
- Qwi 101Dokument20 SeitenQwi 101Anup SinghNoch keine Bewertungen
- Session 20 - Giovanna BrancatoDokument10 SeitenSession 20 - Giovanna BrancatoRafael Bassegio CaumoNoch keine Bewertungen
- Wcms 632187Dokument40 SeitenWcms 632187Tssavage MwaleNoch keine Bewertungen
- Canberra Group Handbook On Household Income StatisticsDokument208 SeitenCanberra Group Handbook On Household Income StatisticsUNECE Statistical DivisionNoch keine Bewertungen
- International Journal of Accounting Information Systems: John Mccallig, Alastair Robb, Fiona RohdeDokument12 SeitenInternational Journal of Accounting Information Systems: John Mccallig, Alastair Robb, Fiona Rohdenikan movahediNoch keine Bewertungen
- Manual Respuesta 2015Dokument156 SeitenManual Respuesta 2015SantiagoCarmonaNoch keine Bewertungen
- The 6th Edition Construction Echart Book PDFDokument156 SeitenThe 6th Edition Construction Echart Book PDFJakoNoch keine Bewertungen
- Publicação Internacional - Ontologic Audit Trails Mapping For Detection of Irregularities in PayrollsDokument6 SeitenPublicação Internacional - Ontologic Audit Trails Mapping For Detection of Irregularities in PayrollsSandir CamposNoch keine Bewertungen
- European Accounting Review: Please Scroll Down For ArticleDokument26 SeitenEuropean Accounting Review: Please Scroll Down For Articlelananh32Noch keine Bewertungen
- Capital Stocks and Fixed Capital Consumption QMIDokument11 SeitenCapital Stocks and Fixed Capital Consumption QMIimad.charkani.hassaniNoch keine Bewertungen
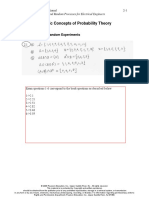
- Chapter 2: Basic Concepts of Probability Theory: 2.1 Specifying Random ExperimentsDokument6 SeitenChapter 2: Basic Concepts of Probability Theory: 2.1 Specifying Random ExperimentsSonam AlviNoch keine Bewertungen
- Speed and Position Control of A DC Motor Using ATmega328Dokument5 SeitenSpeed and Position Control of A DC Motor Using ATmega328GRD JournalsNoch keine Bewertungen
- Biaxial Bending (Beams in Both Axis) : Ce 514 - Steel DesignDokument6 SeitenBiaxial Bending (Beams in Both Axis) : Ce 514 - Steel DesignFrederick Perez IINoch keine Bewertungen
- 2139 12021 1 PB PDFDokument9 Seiten2139 12021 1 PB PDFSantosh Kumar PandeyNoch keine Bewertungen
- New Microsoft Office Word DocumentDokument7 SeitenNew Microsoft Office Word DocumentMangisetty SairamNoch keine Bewertungen
- RM 4Dokument37 SeitenRM 4RHEALYN GEMOTONoch keine Bewertungen
- Course SyllabusDokument4 SeitenCourse SyllabusAndrew KimNoch keine Bewertungen
- An Introduction To Artificial Neural NetworkDokument5 SeitenAn Introduction To Artificial Neural NetworkMajin BuuNoch keine Bewertungen
- SPACE BODY AND MOVEMENT Notes On The Res PDFDokument23 SeitenSPACE BODY AND MOVEMENT Notes On The Res PDFMohammed Gism AllahNoch keine Bewertungen
- GATE 2014 Civil With AnswersDokument33 SeitenGATE 2014 Civil With AnswersJaga NathNoch keine Bewertungen
- Solved Problems - Continuous Random VariablesDokument4 SeitenSolved Problems - Continuous Random VariablesDahanyakage WickramathungaNoch keine Bewertungen
- Marasigan, Christian M. CE-2202 Hydrology Problem Set - Chapter 4 Streamflow MeasurementDokument10 SeitenMarasigan, Christian M. CE-2202 Hydrology Problem Set - Chapter 4 Streamflow Measurementchrstnmrsgn100% (1)
- D-Wave Articulo Prof Venegas Del de Youtube PDFDokument31 SeitenD-Wave Articulo Prof Venegas Del de Youtube PDFMarco A. ErazoNoch keine Bewertungen
- Tutorial Letter 001/3/2021: Complex AnalysisDokument19 SeitenTutorial Letter 001/3/2021: Complex AnalysisKyle MaharajNoch keine Bewertungen
- Minevent 2006 PDFDokument12 SeitenMinevent 2006 PDFJosé Manuel Berrospi CruzNoch keine Bewertungen
- Quality Control and Analysis: Ujvnl Ae 2016Dokument7 SeitenQuality Control and Analysis: Ujvnl Ae 2016Sagar ThengilNoch keine Bewertungen
- Analytical Solution To Transient Heat Conduction in Polar Coordinates With Multiple Layers in Radial DirectionDokument13 SeitenAnalytical Solution To Transient Heat Conduction in Polar Coordinates With Multiple Layers in Radial DirectionGabriel SaavedraNoch keine Bewertungen
- 9 - 28 - 0 - 0 - 40 - 5th Electrical DE&MPDokument165 Seiten9 - 28 - 0 - 0 - 40 - 5th Electrical DE&MPvijay kumar GuptaNoch keine Bewertungen
- Unit 4 - Lesson 2Dokument3 SeitenUnit 4 - Lesson 2api-243891235Noch keine Bewertungen
- Lab ManualDokument125 SeitenLab ManualsurekadeepuNoch keine Bewertungen
- High Low MethodDokument4 SeitenHigh Low MethodSamreen LodhiNoch keine Bewertungen
- SimuPlot5 ManualDokument25 SeitenSimuPlot5 Manualikorishor ambaNoch keine Bewertungen
- Graph Homomorphisms: Open Problems: L Aszl o Lov Asz June 2008Dokument10 SeitenGraph Homomorphisms: Open Problems: L Aszl o Lov Asz June 2008vanaj123Noch keine Bewertungen
- Maths PDFDokument60 SeitenMaths PDFLoh Chee WeiNoch keine Bewertungen
- Mathematics Teaching MethodsDokument134 SeitenMathematics Teaching MethodsDAVID KOIYANoch keine Bewertungen
- Geh 6676 Power System Stabilizer For EX2100 Excitation ControlDokument48 SeitenGeh 6676 Power System Stabilizer For EX2100 Excitation ControlSupolNoch keine Bewertungen
- 2003 HSC Notes From The Marking Centre Mathematics Extension 1Dokument24 Seiten2003 HSC Notes From The Marking Centre Mathematics Extension 1Ye ZhangNoch keine Bewertungen
- Open Set ProofDokument2 SeitenOpen Set Proofsagetbob43Noch keine Bewertungen
- GMAT Club Grammar BookDokument98 SeitenGMAT Club Grammar Bookvinit.parkarNoch keine Bewertungen
- GPS Constellation Toolbox Manual-Version70Dokument131 SeitenGPS Constellation Toolbox Manual-Version70bdkim90Noch keine Bewertungen
- The Internet Con: How to Seize the Means of ComputationVon EverandThe Internet Con: How to Seize the Means of ComputationBewertung: 5 von 5 Sternen5/5 (6)
- Evaluation of Some SMS Verification Services and Virtual Credit Cards Services for Online Accounts VerificationsVon EverandEvaluation of Some SMS Verification Services and Virtual Credit Cards Services for Online Accounts VerificationsBewertung: 5 von 5 Sternen5/5 (2)
- Laws of UX: Using Psychology to Design Better Products & ServicesVon EverandLaws of UX: Using Psychology to Design Better Products & ServicesBewertung: 5 von 5 Sternen5/5 (9)
- The Designer’s Guide to Figma: Master Prototyping, Collaboration, Handoff, and WorkflowVon EverandThe Designer’s Guide to Figma: Master Prototyping, Collaboration, Handoff, and WorkflowNoch keine Bewertungen
- Introduction to Internet Scams and Fraud: Credit Card Theft, Work-At-Home Scams and Lottery ScamsVon EverandIntroduction to Internet Scams and Fraud: Credit Card Theft, Work-At-Home Scams and Lottery ScamsBewertung: 4 von 5 Sternen4/5 (6)
- Branding: What You Need to Know About Building a Personal Brand and Growing Your Small Business Using Social Media Marketing and Offline Guerrilla TacticsVon EverandBranding: What You Need to Know About Building a Personal Brand and Growing Your Small Business Using Social Media Marketing and Offline Guerrilla TacticsBewertung: 5 von 5 Sternen5/5 (32)
- Ten Arguments for Deleting Your Social Media Accounts Right NowVon EverandTen Arguments for Deleting Your Social Media Accounts Right NowBewertung: 4 von 5 Sternen4/5 (388)
- Facing Cyber Threats Head On: Protecting Yourself and Your BusinessVon EverandFacing Cyber Threats Head On: Protecting Yourself and Your BusinessBewertung: 4.5 von 5 Sternen4.5/5 (27)
- The Digital Marketing Handbook: A Step-By-Step Guide to Creating Websites That SellVon EverandThe Digital Marketing Handbook: A Step-By-Step Guide to Creating Websites That SellBewertung: 5 von 5 Sternen5/5 (6)
- OSCP Offensive Security Certified Professional Practice Tests With Answers To Pass the OSCP Ethical Hacking Certification ExamVon EverandOSCP Offensive Security Certified Professional Practice Tests With Answers To Pass the OSCP Ethical Hacking Certification ExamNoch keine Bewertungen
- Grokking Algorithms: An illustrated guide for programmers and other curious peopleVon EverandGrokking Algorithms: An illustrated guide for programmers and other curious peopleBewertung: 4 von 5 Sternen4/5 (16)
- The YouTube Formula: How Anyone Can Unlock the Algorithm to Drive Views, Build an Audience, and Grow RevenueVon EverandThe YouTube Formula: How Anyone Can Unlock the Algorithm to Drive Views, Build an Audience, and Grow RevenueBewertung: 5 von 5 Sternen5/5 (33)
- Microservices Patterns: With examples in JavaVon EverandMicroservices Patterns: With examples in JavaBewertung: 5 von 5 Sternen5/5 (2)
- How to Be Fine: What We Learned by Living by the Rules of 50 Self-Help BooksVon EverandHow to Be Fine: What We Learned by Living by the Rules of 50 Self-Help BooksBewertung: 4.5 von 5 Sternen4.5/5 (48)
- Social Media Marketing 2024, 2025: Build Your Business, Skyrocket in Passive Income, Stop Working a 9-5 Lifestyle, True Online Working from HomeVon EverandSocial Media Marketing 2024, 2025: Build Your Business, Skyrocket in Passive Income, Stop Working a 9-5 Lifestyle, True Online Working from HomeNoch keine Bewertungen
- CISM Certified Information Security Manager Study GuideVon EverandCISM Certified Information Security Manager Study GuideNoch keine Bewertungen
- Tor Darknet Bundle (5 in 1): Master the Art of InvisibilityVon EverandTor Darknet Bundle (5 in 1): Master the Art of InvisibilityBewertung: 4.5 von 5 Sternen4.5/5 (5)
- Ultimate Guide to YouTube for BusinessVon EverandUltimate Guide to YouTube for BusinessBewertung: 5 von 5 Sternen5/5 (1)
- Hacking With Kali Linux : A Comprehensive, Step-By-Step Beginner's Guide to Learn Ethical Hacking With Practical Examples to Computer Hacking, Wireless Network, Cybersecurity and Penetration TestingVon EverandHacking With Kali Linux : A Comprehensive, Step-By-Step Beginner's Guide to Learn Ethical Hacking With Practical Examples to Computer Hacking, Wireless Network, Cybersecurity and Penetration TestingBewertung: 4.5 von 5 Sternen4.5/5 (9)
- Evaluation of Some Websites that Offer Virtual Phone Numbers for SMS Reception and Websites to Obtain Virtual Debit/Credit Cards for Online Accounts VerificationsVon EverandEvaluation of Some Websites that Offer Virtual Phone Numbers for SMS Reception and Websites to Obtain Virtual Debit/Credit Cards for Online Accounts VerificationsBewertung: 5 von 5 Sternen5/5 (1)