Das könnte Ihnen auch gefallen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5795)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1091)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- JIP - Field Segmented Fittings - Phase 2 Report - FINAL - 12-06-11 - tcm153-484341Dokument127 SeitenJIP - Field Segmented Fittings - Phase 2 Report - FINAL - 12-06-11 - tcm153-484341quiron2010Noch keine Bewertungen
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
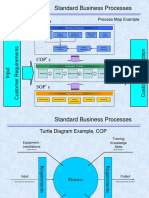
- Process Maps and Turtle Diagrams ExampleDokument2 SeitenProcess Maps and Turtle Diagrams ExampleJohn Oo100% (1)
- Raging Swan Dungeon Dressing Bridges 2.0Dokument12 SeitenRaging Swan Dungeon Dressing Bridges 2.0Alessandro SurraNoch keine Bewertungen
- Silo - Tips - Project Management Plan For The Vdi Data Center Project PDFDokument51 SeitenSilo - Tips - Project Management Plan For The Vdi Data Center Project PDFbalamurali_aNoch keine Bewertungen
- Cyber Security NotesDokument21 SeitenCyber Security Notesbalamurali_aNoch keine Bewertungen
- ASSHTO Example Strut and TieDokument62 SeitenASSHTO Example Strut and TieSothea Born100% (4)
- Hyperion Essbase Bootcamp ExercisesDokument74 SeitenHyperion Essbase Bootcamp Exerciseslog_anupamNoch keine Bewertungen
- KLN 90B Installation ManualDokument152 SeitenKLN 90B Installation Manualsandyz007Noch keine Bewertungen
- 2010-06-14 1300 Project Management Broad Spectrum Overview WikibookDokument522 Seiten2010-06-14 1300 Project Management Broad Spectrum Overview WikibookKits Sri100% (1)
- Management Information System 01Dokument332 SeitenManagement Information System 01ahmadfiroz75% (4)
- Interview Questions For Sap SD PDFDokument50 SeitenInterview Questions For Sap SD PDFRajan S PrasadNoch keine Bewertungen
- Office 365 Support & Managed Services: Service GuideDokument12 SeitenOffice 365 Support & Managed Services: Service Guidebalamurali_aNoch keine Bewertungen
- Tomcat Cat PDFDokument142 SeitenTomcat Cat PDFAptaeex ExtremaduraNoch keine Bewertungen
- Project Report On e CommerceDokument74 SeitenProject Report On e CommerceSom Soumya DasNoch keine Bewertungen
- Brick Bat Coba Water Proofing - Methodology As Per CPWDDokument3 SeitenBrick Bat Coba Water Proofing - Methodology As Per CPWDDeepak Kaushik100% (1)
- Recommended Security Baseline SettingsDokument28 SeitenRecommended Security Baseline Settingsbalamurali_aNoch keine Bewertungen
- Icon Aircarft A5 - BrochureDokument13 SeitenIcon Aircarft A5 - BrochureAiddie GhazlanNoch keine Bewertungen
- Integrating Lean Thinking Into ISO 9001 - A First GuidelineDokument25 SeitenIntegrating Lean Thinking Into ISO 9001 - A First GuidelineakanddevNoch keine Bewertungen
- Remediation and Hardening - O365Dokument39 SeitenRemediation and Hardening - O365balamurali_aNoch keine Bewertungen
- Veritas CloudPoint Administrator's GuideDokument294 SeitenVeritas CloudPoint Administrator's Guidebalamurali_aNoch keine Bewertungen
- What Is Multi-Factor Authentication?: Why MFA?Dokument16 SeitenWhat Is Multi-Factor Authentication?: Why MFA?balamurali_aNoch keine Bewertungen
- Lab4 Microsoft Defender For Office 365 - Attack SimulatorDokument21 SeitenLab4 Microsoft Defender For Office 365 - Attack Simulatorbalamurali_aNoch keine Bewertungen
- Amazon AppStream 2.0 - SAP GUI Deployment GuideDokument51 SeitenAmazon AppStream 2.0 - SAP GUI Deployment Guidebalamurali_aNoch keine Bewertungen
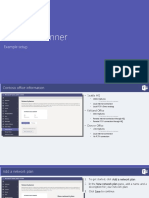
- Network Planner: Example SetupDokument12 SeitenNetwork Planner: Example Setupbalamurali_aNoch keine Bewertungen
- Analyzing The Performance of An Anycast CDNDokument7 SeitenAnalyzing The Performance of An Anycast CDNbalamurali_aNoch keine Bewertungen
- Office 365 Best Practices ChecklistDokument1 SeiteOffice 365 Best Practices Checklistbalamurali_a100% (1)
- ITSE1370AA L1 IntroductionDokument8 SeitenITSE1370AA L1 Introductionbalamurali_aNoch keine Bewertungen
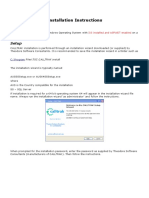
- Installation Instructions SQLServerDokument28 SeitenInstallation Instructions SQLServerbalamurali_aNoch keine Bewertungen
- CIT2016 Creating Custom Automations in A SCCM Task SequenceDokument2 SeitenCIT2016 Creating Custom Automations in A SCCM Task Sequencebalamurali_aNoch keine Bewertungen
- Office365 Forms and FlowDokument13 SeitenOffice365 Forms and Flowbalamurali_aNoch keine Bewertungen
- Forest - General Forest - General: Category Best PracticeDokument11 SeitenForest - General Forest - General: Category Best Practicebalamurali_aNoch keine Bewertungen
- Db-Manual WPM ExtractDokument43 SeitenDb-Manual WPM ExtractSamuel MatiasNoch keine Bewertungen
- Al Nasser ProfileDokument35 SeitenAl Nasser ProfileMuthana JalladNoch keine Bewertungen
- Cardiff University International ProspectusDokument48 SeitenCardiff University International ProspectusEric SunwayNoch keine Bewertungen
- Summary Journal: From Asia To Africa: The International Expansion of Hon Chuan EnterpriseDokument1 SeiteSummary Journal: From Asia To Africa: The International Expansion of Hon Chuan EnterpriseFynNoch keine Bewertungen
- CS2 - Carbon Steel Bars For The Reinforcement of Concrete (1995)Dokument36 SeitenCS2 - Carbon Steel Bars For The Reinforcement of Concrete (1995)don2hmrNoch keine Bewertungen
- ISO Observation Points by AuditorsDokument2 SeitenISO Observation Points by Auditorsvishwas salunkheNoch keine Bewertungen
- EagleBurgmann - B-OGE - E3 - Sealing Competence Oil and Gas Industry - EN - 14.11.2016Dokument24 SeitenEagleBurgmann - B-OGE - E3 - Sealing Competence Oil and Gas Industry - EN - 14.11.2016lokeshkumar_mNoch keine Bewertungen
- Pds Fire Door SlowDokument55 SeitenPds Fire Door SlowRachel IngramNoch keine Bewertungen
- Deloitte - 2022 Global Automotive Consumer StudyDokument34 SeitenDeloitte - 2022 Global Automotive Consumer StudyAakash MalhotraNoch keine Bewertungen
- Best Commercial Real Estate Builders in Sangli at SL HighstreetDokument4 SeitenBest Commercial Real Estate Builders in Sangli at SL HighstreetShah DevelopersNoch keine Bewertungen
- Kim H. Pries-Six Sigma For The New Millennium - A CSSBB Guidebook, Second Edition-ASQ Quality Press (2009)Dokument456 SeitenKim H. Pries-Six Sigma For The New Millennium - A CSSBB Guidebook, Second Edition-ASQ Quality Press (2009)Elvis Sikora100% (1)
- Us 20190016231 A 1Dokument27 SeitenUs 20190016231 A 1Fred Lamert100% (1)
- Instrument Landing SystemDokument62 SeitenInstrument Landing Systemzeeshan_946461113100% (1)
- Nebosh D GuideDokument2 SeitenNebosh D GuideNorman AinomugishaNoch keine Bewertungen
- PhiladelphiaBusinessJournal June 15, 2018Dokument32 SeitenPhiladelphiaBusinessJournal June 15, 2018Craig EyNoch keine Bewertungen
- Preface 1997 Pneumatic Handbook Eighth EditionDokument1 SeitePreface 1997 Pneumatic Handbook Eighth EditionErkanAksoyluNoch keine Bewertungen