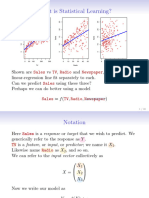
Das könnte Ihnen auch gefallen
- Optimal Experimental Design For Non-Linear Models Theory and ApplicationsDokument104 SeitenOptimal Experimental Design For Non-Linear Models Theory and ApplicationsRaul VelasquezNoch keine Bewertungen
- Sample Definition: A Sample Is A Group of Units Selected From A Larger Group (TheDokument7 SeitenSample Definition: A Sample Is A Group of Units Selected From A Larger Group (Theaqsa_sheikh3294Noch keine Bewertungen
- Digital StrategyDokument4 SeitenDigital StrategyPETERNoch keine Bewertungen
- Essential Unani Medicines LRDokument57 SeitenEssential Unani Medicines LRDrRaghvendra Kumar SinghNoch keine Bewertungen
- ISOMDokument5 SeitenISOMAntaraNoch keine Bewertungen
- Slides 06 Lab RDokument23 SeitenSlides 06 Lab RSaD.- MegakillNoch keine Bewertungen
- 330 Lecture18 2014Dokument24 Seiten330 Lecture18 2014PETERNoch keine Bewertungen
- Prelims StatsDokument39 SeitenPrelims StatsSergioNoch keine Bewertungen
- C2 Statistical LearningDokument37 SeitenC2 Statistical LearningLluïsa GualNoch keine Bewertungen
- Duke RegressionDokument17 SeitenDuke RegressionHarshal ChaudhariNoch keine Bewertungen
- 2014 TestDokument13 Seiten2014 TestAnonymous gUySMcpSqNoch keine Bewertungen
- Lect5 Math231Dokument31 SeitenLect5 Math231Qasim RafiNoch keine Bewertungen
- Course2 - Principal Component Analysis (PCA) : Fiche TD Avec Le LogicielDokument17 SeitenCourse2 - Principal Component Analysis (PCA) : Fiche TD Avec Le LogicielJohnnyNoch keine Bewertungen
- Agile Practices, Collaboration and Experience: November 2016Dokument17 SeitenAgile Practices, Collaboration and Experience: November 2016Haja ShareefNoch keine Bewertungen
- Introduction To Time Series Analysis: Welcome To The Course!Dokument20 SeitenIntroduction To Time Series Analysis: Welcome To The Course!enrique gonzalez duranNoch keine Bewertungen
- Covariance, Regression, and Correlation: Galton 1877Dokument42 SeitenCovariance, Regression, and Correlation: Galton 1877Mayra AlbuquerqueNoch keine Bewertungen
- 330 Lecture15 2014Dokument53 Seiten330 Lecture15 2014PiNoch keine Bewertungen
- Q Q Plot of Residuals: Batch# 1 Batch# 2 Batch# 3Dokument2 SeitenQ Q Plot of Residuals: Batch# 1 Batch# 2 Batch# 3apsara karkiNoch keine Bewertungen
- (With Residual Plot) : 40 60 80 100 120 140 160 WeightDokument11 Seiten(With Residual Plot) : 40 60 80 100 120 140 160 WeightmehrinfatimaNoch keine Bewertungen
- Week 8 and 9 Session 1Dokument23 SeitenWeek 8 and 9 Session 1Diana LazarNoch keine Bewertungen
- Lect6 Math231Dokument38 SeitenLect6 Math231Qasim RafiNoch keine Bewertungen
- Sim RDokument6 SeitenSim Rsipho23Noch keine Bewertungen
- V64i04 PDFDokument34 SeitenV64i04 PDFElíGomaraGilNoch keine Bewertungen
- SLR NotesDokument96 SeitenSLR NotesRafi DawarNoch keine Bewertungen
- Midterm Test: Reaction Times Vs Caffeine IntakeDokument2 SeitenMidterm Test: Reaction Times Vs Caffeine IntakeAnonymous gUySMcpSqNoch keine Bewertungen
- RootsExtremaInflections 2017-05-26Dokument16 SeitenRootsExtremaInflections 2017-05-26mgrubisicNoch keine Bewertungen
- Lecture3 AestheticDokument59 SeitenLecture3 AestheticLois RiveraNoch keine Bewertungen
- Noncentral TDokument56 SeitenNoncentral TMadara RadillaNoch keine Bewertungen
- Economics 536 The Regression FallacyDokument9 SeitenEconomics 536 The Regression FallacyMaria RoaNoch keine Bewertungen
- 6 Slides-Ggplot2 Part1Dokument27 Seiten6 Slides-Ggplot2 Part1Ashwani KumarNoch keine Bewertungen
- Sample 3648Dokument16 SeitenSample 3648P Singh Karki0% (1)
- Multi Media Presentation ADokument26 SeitenMulti Media Presentation AAnnette DodsonNoch keine Bewertungen
- Mock Midterm Test 1: Exercise Exercise ExerciseDokument2 SeitenMock Midterm Test 1: Exercise Exercise ExercisePETERNoch keine Bewertungen
- TransformationsDokument21 SeitenTransformationslemuel sardualNoch keine Bewertungen
- Rise of The Machines: Larry WassermanDokument12 SeitenRise of The Machines: Larry WassermanIsmael KaïssyNoch keine Bewertungen
- Week2 StatisticalLearningDokument46 SeitenWeek2 StatisticalLearningMuntaz MuntazNoch keine Bewertungen
- Chapter One: CRM, Database Marketing and Customer ValueDokument26 SeitenChapter One: CRM, Database Marketing and Customer Valuemazhar_ibaNoch keine Bewertungen
- Displaying Model Plots in Lattice PlotsDokument16 SeitenDisplaying Model Plots in Lattice PlotsAriake SwyceNoch keine Bewertungen
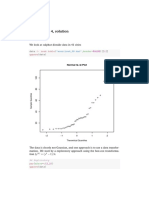
- Week 4, Solution: Exercise 4.38Dokument15 SeitenWeek 4, Solution: Exercise 4.38John SmithNoch keine Bewertungen
- Bus p2 2015Dokument16 SeitenBus p2 2015iilongamarthinNoch keine Bewertungen
- Wide 0Dokument3 SeitenWide 0gg hhNoch keine Bewertungen
- TQM Six+SigmaDokument14 SeitenTQM Six+SigmaEktaSinghNoch keine Bewertungen
- Graphics Course 0125Dokument73 SeitenGraphics Course 0125Federico CarusoNoch keine Bewertungen
- The Bayesian Lasso: Rebecca C. Steorts Predictive Modeling and Data Mining: STA 521Dokument16 SeitenThe Bayesian Lasso: Rebecca C. Steorts Predictive Modeling and Data Mining: STA 521Malika BehroozrazeghNoch keine Bewertungen
- t04 Nested EvaluationDokument14 Seitent04 Nested EvaluationsameenapathankhanNoch keine Bewertungen
- Biostatistics of HKU MMEDSC Session2handoutprint3Dokument23 SeitenBiostatistics of HKU MMEDSC Session2handoutprint3Xin chao LiNoch keine Bewertungen
- pt4 Adv Regression Models PDFDokument170 Seitenpt4 Adv Regression Models PDFVishwajit kumarNoch keine Bewertungen
- Bayesian Structural Time Series ModelsDokument100 SeitenBayesian Structural Time Series ModelsClaudyaNoch keine Bewertungen
- 330 Lecture11 2014Dokument61 Seiten330 Lecture11 2014PETERNoch keine Bewertungen
- TQM Six SigmaDokument21 SeitenTQM Six Sigmap ganeshNoch keine Bewertungen
- Lecture 2: Summarizing Data: Bo LiDokument73 SeitenLecture 2: Summarizing Data: Bo LiLee ChiaNoch keine Bewertungen
- Data ScienceDokument35 SeitenData ScienceVenkata Anil Kumar SudiNoch keine Bewertungen
- STAT1400 2022 1st Week4-Lecture 8Dokument22 SeitenSTAT1400 2022 1st Week4-Lecture 8Sameer GuptaNoch keine Bewertungen
- IASSC Black Belt - Examination Preparation Training For Black Belt ExaminationDokument10 SeitenIASSC Black Belt - Examination Preparation Training For Black Belt ExaminationMahmoud ElemamNoch keine Bewertungen
- Lect6 PDFDokument22 SeitenLect6 PDF杜晓晚Noch keine Bewertungen
- K-Means Vs Mini Batch K-Means: A ComparisonDokument12 SeitenK-Means Vs Mini Batch K-Means: A Comparisonrather AarifNoch keine Bewertungen
- STAT1400 2022 1st Week4-Lecture 7Dokument19 SeitenSTAT1400 2022 1st Week4-Lecture 7Sameer GuptaNoch keine Bewertungen
- 9-4 Trend Line EquationsDokument2 Seiten9-4 Trend Line EquationsDylan Early (STUDENT)Noch keine Bewertungen
- Regression Analysis - From Statistics To Machine Learning: Ronald Hochreiter Sensational - AiDokument50 SeitenRegression Analysis - From Statistics To Machine Learning: Ronald Hochreiter Sensational - AithcNoch keine Bewertungen
- MMack Workforce Innovations CoenrollmentDokument27 SeitenMMack Workforce Innovations Coenrollmentsicklesb100% (2)
- MissingdataDokument10 SeitenMissingdataAyaan ShahNoch keine Bewertungen
- Coimisiún Na Scrúduithe Stáit: State Examinations CommissionDokument72 SeitenCoimisiún Na Scrúduithe Stáit: State Examinations CommissionKhyle Hero Lapid SobrevigaNoch keine Bewertungen
- Robots Mean Business A Conversation With Rodney BrooksDokument4 SeitenRobots Mean Business A Conversation With Rodney BrooksPiNoch keine Bewertungen
- 5 Tricks When Ab Testing Is Off The Table - Teconomics - MediumDokument13 Seiten5 Tricks When Ab Testing Is Off The Table - Teconomics - MediumPETERNoch keine Bewertungen
- Sky TeamDokument22 SeitenSky TeamPETERNoch keine Bewertungen
- Analytics in Action With Teradata CloudDokument19 SeitenAnalytics in Action With Teradata CloudPETERNoch keine Bewertungen
- Cold StartDokument3 SeitenCold StartPETERNoch keine Bewertungen
- Safety Data Sheet: Die Hardener PremiumDokument7 SeitenSafety Data Sheet: Die Hardener PremiumPiNoch keine Bewertungen
- Methylated Spirits Msds 56454 Jun08Dokument8 SeitenMethylated Spirits Msds 56454 Jun08PETERNoch keine Bewertungen
- Vertex Self Curing LiquidDokument18 SeitenVertex Self Curing LiquidPETERNoch keine Bewertungen
- Special Methylated Spirit 70% Untinted: Material Safety Data SheetDokument3 SeitenSpecial Methylated Spirit 70% Untinted: Material Safety Data SheetPETERNoch keine Bewertungen
- Modelling Wax Iw421xxDokument4 SeitenModelling Wax Iw421xxPETERNoch keine Bewertungen
- 2015 Student FeesDokument24 Seiten2015 Student FeesPETERNoch keine Bewertungen
- Methylated Spirits Msds 56454 Jun08Dokument8 SeitenMethylated Spirits Msds 56454 Jun08PETERNoch keine Bewertungen
- MethylatedDokument3 SeitenMethylatedPETERNoch keine Bewertungen
- Hazardous Substance Fact Sheet: Right To KnowDokument6 SeitenHazardous Substance Fact Sheet: Right To KnowPETERNoch keine Bewertungen
- Dentaurum Rema Exakt, Rema Exakt F Mixing LiquidDokument6 SeitenDentaurum Rema Exakt, Rema Exakt F Mixing LiquidPETERNoch keine Bewertungen
- Wacker Catalyst T 35Dokument6 SeitenWacker Catalyst T 35PETERNoch keine Bewertungen
- File Vertex Ortoplast Polvere Scheda Di SicurezzaDokument6 SeitenFile Vertex Ortoplast Polvere Scheda Di SicurezzaPiNoch keine Bewertungen
- Msds B50Dokument3 SeitenMsds B50PETERNoch keine Bewertungen
- Msds SDHDokument2 SeitenMsds SDHPETERNoch keine Bewertungen
- 128 301 20Dokument4 Seiten128 301 20PETERNoch keine Bewertungen
- Government Response: Pricing VET Under Smart and Skilled - Final ReportDokument7 SeitenGovernment Response: Pricing VET Under Smart and Skilled - Final ReportPETERNoch keine Bewertungen
- Eligible Occupations For The Hecs Help BenefitDokument3 SeitenEligible Occupations For The Hecs Help BenefitPiNoch keine Bewertungen
- 989 800 12Dokument5 Seiten989 800 12PETERNoch keine Bewertungen
- Ips Inline System Glaze and Stains LiquidDokument5 SeitenIps Inline System Glaze and Stains LiquidPETERNoch keine Bewertungen
- 2015 Prices Fees SubsidiesDokument16 Seiten2015 Prices Fees SubsidiesPETERNoch keine Bewertungen
- 2015 Prices Fees SubsidiesDokument18 Seiten2015 Prices Fees SubsidiesPETERNoch keine Bewertungen
- 20Dokument9 Seiten20PiNoch keine Bewertungen
- 2014 Skills List at Qualification V2Dokument20 Seiten2014 Skills List at Qualification V2PETERNoch keine Bewertungen
- Sp16 6us PDFDokument97 SeitenSp16 6us PDFPETERNoch keine Bewertungen
- The Kolmogorov Smirnov One Sample TestDokument13 SeitenThe Kolmogorov Smirnov One Sample TestLito LarinoNoch keine Bewertungen
- Kruskal-Wallis H Test in SPSS Statistics - Procedure, Output and Interpretation of The Output Using A Relevant Example - PDFDokument8 SeitenKruskal-Wallis H Test in SPSS Statistics - Procedure, Output and Interpretation of The Output Using A Relevant Example - PDFArun Kumar SinghNoch keine Bewertungen
- Poison Distribution TableDokument1 SeitePoison Distribution TableKibet KiptooNoch keine Bewertungen
- UNIT-4: Reading Material On Hypothesis Testing With Single SampleDokument7 SeitenUNIT-4: Reading Material On Hypothesis Testing With Single Samplesamaya pypNoch keine Bewertungen
- Lesson Plan in Statistics and Probability November 13, 2019Dokument2 SeitenLesson Plan in Statistics and Probability November 13, 2019Elmer PiadNoch keine Bewertungen
- SME Performance Separating Myth From Reality (PDFDrive)Dokument167 SeitenSME Performance Separating Myth From Reality (PDFDrive)Livia Naftharani100% (1)
- MIT - Statistics For ApplicationsDokument294 SeitenMIT - Statistics For ApplicationsaffieexyqznxeeNoch keine Bewertungen
- Regression EquationDokument56 SeitenRegression EquationMuhammad TariqNoch keine Bewertungen
- Needleman-Wunsch and Smith-Waterman AlgorithmDokument19 SeitenNeedleman-Wunsch and Smith-Waterman Algorithmgayu_positive67% (9)
- ON "Marketing Layout and Strategy in Oil and Natural Gas Corporation-Ongc"Dokument35 SeitenON "Marketing Layout and Strategy in Oil and Natural Gas Corporation-Ongc"shyamNoch keine Bewertungen
- Gage Repeatability and Reproducibility Data Collection SheetDokument1 SeiteGage Repeatability and Reproducibility Data Collection SheetIng. Alejandro Hernández B.Noch keine Bewertungen
- Ejc h2 MathDokument5 SeitenEjc h2 MathcannotknowNoch keine Bewertungen
- Syllabus 463 2016Dokument2 SeitenSyllabus 463 2016M PNoch keine Bewertungen
- Stability of Money Demand in An Emerging Market Economy: An Error Correction and ARDL Model For IndonesiaDokument9 SeitenStability of Money Demand in An Emerging Market Economy: An Error Correction and ARDL Model For Indonesiaahmad_subhan1832Noch keine Bewertungen
- Time Management On Distance Learning EDU 580 Chapter 1Dokument24 SeitenTime Management On Distance Learning EDU 580 Chapter 1John Michael BernardinoNoch keine Bewertungen
- Multiple RegressionDokument57 SeitenMultiple RegressionChristian Alfred VillenaNoch keine Bewertungen
- Cashflow Timing vs. Discount-Rate Timing: A Decomposition of Mutual Fund Market-Timing SkillsDokument59 SeitenCashflow Timing vs. Discount-Rate Timing: A Decomposition of Mutual Fund Market-Timing SkillsSteffen KutscherNoch keine Bewertungen
- Introduction To A319 Environmental Data AnalysisDokument18 SeitenIntroduction To A319 Environmental Data AnalysisLim Liang XuanNoch keine Bewertungen
- Multivariate Statistical Analysis: Old SchoolDokument319 SeitenMultivariate Statistical Analysis: Old SchoolVivek11Noch keine Bewertungen
- Correlation and Causal Comparative ResearchDokument34 SeitenCorrelation and Causal Comparative ResearchBanu PriyaNoch keine Bewertungen
- Neural Voice Cloning With A Few Samples: February 2018Dokument17 SeitenNeural Voice Cloning With A Few Samples: February 2018Suvedhya ReddyNoch keine Bewertungen
- Chapter 3. Decision Theory: ObjectiveDokument26 SeitenChapter 3. Decision Theory: ObjectiveThien TranNoch keine Bewertungen
- Lecture III - Types of ResearchDokument14 SeitenLecture III - Types of ResearchJoshua Mark MuhenyeriNoch keine Bewertungen
- Amreen HandicraftDokument66 SeitenAmreen Handicraftajay sharmaNoch keine Bewertungen
- Stats Chapter 6 ProbabilityDokument22 SeitenStats Chapter 6 ProbabilityMadison HartfieldNoch keine Bewertungen
- Basic Terminology: - Trial & Event ExhaustiveDokument38 SeitenBasic Terminology: - Trial & Event ExhaustiveJennifer Duke100% (1)
- CHP 3 Notes, GujaratiDokument4 SeitenCHP 3 Notes, GujaratiDiwakar ChakrabortyNoch keine Bewertungen