Das könnte Ihnen auch gefallen
- Unit - I Artificial Neural NetworksDokument23 SeitenUnit - I Artificial Neural NetworksMary MorseNoch keine Bewertungen
- Handbook of Series for Scientists and EngineersVon EverandHandbook of Series for Scientists and EngineersBewertung: 3 von 5 Sternen3/5 (1)
- Unit - I Artificial Neural NetworksDokument23 SeitenUnit - I Artificial Neural NetworksMary MorseNoch keine Bewertungen
- 09 - COE426-Differential Privacy IIDokument30 Seiten09 - COE426-Differential Privacy IIomar.alnajjar.3001Noch keine Bewertungen
- Knowledge and ReasoningDokument28 SeitenKnowledge and Reasoningsnehalsadgir0101Noch keine Bewertungen
- CV w6 - Deep LearningDokument86 SeitenCV w6 - Deep LearningDestu WijayadiningratNoch keine Bewertungen
- Unit 4.1 Agent ArchitectureDokument21 SeitenUnit 4.1 Agent ArchitectureJEYANTHI maryNoch keine Bewertungen
- Recurrent Neural Networks: CMSC498LDokument36 SeitenRecurrent Neural Networks: CMSC498LZu KiNoch keine Bewertungen
- Lecture 2 - Supervised LearningDokument6 SeitenLecture 2 - Supervised LearningEric WangNoch keine Bewertungen
- Experiment No: 4: Artificial Intelligence (3170716)Dokument34 SeitenExperiment No: 4: Artificial Intelligence (3170716)krishnaviramgama57Noch keine Bewertungen
- DL Slides 3Dokument99 SeitenDL Slides 3ABI RAJESH GANESHA RAJANoch keine Bewertungen
- 03 Convolutional Neural NetworksDokument83 Seiten03 Convolutional Neural NetworksManish kumawatNoch keine Bewertungen
- Features 0328Dokument85 SeitenFeatures 0328manojaNoch keine Bewertungen
- Lecture4 - Convnets For CV SlideDokument65 SeitenLecture4 - Convnets For CV SlidemohdharislcpNoch keine Bewertungen
- Lecture 3 (A)Dokument32 SeitenLecture 3 (A)Yingqi SuNoch keine Bewertungen
- Lecture 4 - 2007 - Backpropagation - (HINTON)Dokument60 SeitenLecture 4 - 2007 - Backpropagation - (HINTON)alan1966Noch keine Bewertungen
- Do Large Language Models Need Sensory Grounding For Meaning and Understanding?Dokument38 SeitenDo Large Language Models Need Sensory Grounding For Meaning and Understanding?Zakhar KoganNoch keine Bewertungen
- Mod 2.1,2.2Dokument24 SeitenMod 2.1,2.2Christeena AntonyNoch keine Bewertungen
- Lecture 5 - Least Square and Linear (DONE!!)Dokument29 SeitenLecture 5 - Least Square and Linear (DONE!!)Sharelle TewNoch keine Bewertungen
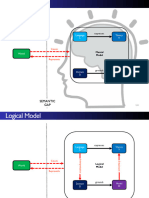
- Language L Theory T: Semantic GAPDokument62 SeitenLanguage L Theory T: Semantic GAPmustabshirah.nayerNoch keine Bewertungen
- Lecturenotes Cse176Dokument80 SeitenLecturenotes Cse176burtNoch keine Bewertungen
- First-Order Logic in Artificial IntelligenceDokument5 SeitenFirst-Order Logic in Artificial IntelligenceAnil Kumar SagarNoch keine Bewertungen
- Recurrent Nets, Convolutional Nets: Yann Lecun Nyu - Courant Institute & Center For Data Science Facebook Ai ResearchDokument32 SeitenRecurrent Nets, Convolutional Nets: Yann Lecun Nyu - Courant Institute & Center For Data Science Facebook Ai ResearchZan GiefNoch keine Bewertungen
- User Manual For CASA/Python Pipeline: Kanchan SoniDokument3 SeitenUser Manual For CASA/Python Pipeline: Kanchan SonigahafemNoch keine Bewertungen
- ST M Hdstat RNN Deep LearningDokument17 SeitenST M Hdstat RNN Deep LearningArif RahmanNoch keine Bewertungen
- Lecture 5Dokument36 SeitenLecture 5emmanuelmachar5Noch keine Bewertungen
- 1 C3 M1 L1 NeuralNetwork1-MLPDokument51 Seiten1 C3 M1 L1 NeuralNetwork1-MLPHuston LAMNoch keine Bewertungen
- Basics of Quantum Mechanics: Reading: QM Course Packet - CH 5Dokument17 SeitenBasics of Quantum Mechanics: Reading: QM Course Packet - CH 5Harshdeep MauryaNoch keine Bewertungen
- Reinforcement LearningDokument32 SeitenReinforcement LearningRajat SinghNoch keine Bewertungen
- Saam Slide l5Dokument54 SeitenSaam Slide l5dorentin.mrnNoch keine Bewertungen
- HW04Dokument9 SeitenHW04Nguyen HikariNoch keine Bewertungen
- Laplace Finite DifferenceDokument5 SeitenLaplace Finite DifferenceFarid MorabetNoch keine Bewertungen
- Machine LearningDokument79 SeitenMachine LearningLOPASNoch keine Bewertungen
- Supervised Learning Cornell CsDokument5 SeitenSupervised Learning Cornell CsMUHAMMAD ALI SIDDIQUENoch keine Bewertungen
- Artificial Neural NetworksDokument55 SeitenArtificial Neural NetworksP K SinghNoch keine Bewertungen
- Python 1Dokument7 SeitenPython 1JyotiNoch keine Bewertungen
- Fuzzy Sets and Fuzzy LogicDokument63 SeitenFuzzy Sets and Fuzzy LogicEman FathyNoch keine Bewertungen
- Chap2 EDokument34 SeitenChap2 EThùy Linh VũNoch keine Bewertungen
- A Programming Language Kenneth E. Iverson: Z/ X ? X Y !Dokument8 SeitenA Programming Language Kenneth E. Iverson: Z/ X ? X Y !haigaisNoch keine Bewertungen
- A Language of ProgrammingDokument8 SeitenA Language of ProgrammingMandlendy OtisNoch keine Bewertungen
- 02 Linear RegressionDokument6 Seiten02 Linear RegressionMatixNoch keine Bewertungen
- Large Scale Deep LearningDokument170 SeitenLarge Scale Deep Learningpavancreative81Noch keine Bewertungen
- Lecturenotes PDFDokument80 SeitenLecturenotes PDFdinesharulNoch keine Bewertungen
- Chapter 11 Fuzzy Control TheoryDokument63 SeitenChapter 11 Fuzzy Control TheoryTihitna TsegayeNoch keine Bewertungen
- Data Mining: Practical Machine Learning Tools and TechniquesDokument123 SeitenData Mining: Practical Machine Learning Tools and TechniquesArvindNoch keine Bewertungen
- Python Programming LanguageDokument25 SeitenPython Programming LanguageMisbah NaqviNoch keine Bewertungen
- Ni 6Dokument40 SeitenNi 6Mohammad Al SamhouriNoch keine Bewertungen
- All LectureNotesDokument155 SeitenAll LectureNotesSrinivas NemaniNoch keine Bewertungen
- For SeminarDokument17 SeitenFor SeminarAnsh BaldeNoch keine Bewertungen
- Sca L1Dokument91 SeitenSca L1S K PrajapatNoch keine Bewertungen
- Lecture-921-NW FunctionsDokument12 SeitenLecture-921-NW FunctionsBangle ChNoch keine Bewertungen
- MLP Lecture 4Dokument35 SeitenMLP Lecture 4amjad tamishNoch keine Bewertungen
- Knowledge RepresentationDokument50 SeitenKnowledge Representationvishakha_18Noch keine Bewertungen
- MOD 3.1 Propositional LogicDokument80 SeitenMOD 3.1 Propositional LogicGUNEET SURANoch keine Bewertungen
- Cs229 Notes Deep LearningDokument21 SeitenCs229 Notes Deep LearningChirag PramodNoch keine Bewertungen
- Dodge The Dynamite Decision-Making in Programming: Boolean LogicDokument8 SeitenDodge The Dynamite Decision-Making in Programming: Boolean Logicbhatsarim80Noch keine Bewertungen
- MAE331Lecture8 PDFDokument24 SeitenMAE331Lecture8 PDFPranav BhardwajNoch keine Bewertungen
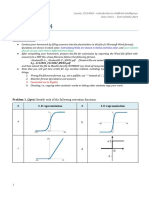
- Mathematics: Lesson 1: FunctionsDokument6 SeitenMathematics: Lesson 1: FunctionsBenard OderoNoch keine Bewertungen
- Novel Approach of Surround SymbolismDokument121 SeitenNovel Approach of Surround SymbolismssfofoNoch keine Bewertungen
- A Machine-Learning-Based Technique For False Data Injection Attacks Detection in Industrial IoTDokument10 SeitenA Machine-Learning-Based Technique For False Data Injection Attacks Detection in Industrial IoTLê Kim HùngNoch keine Bewertungen
- Plant Disease Detection and Classification by Deep Learning-A ReviewDokument16 SeitenPlant Disease Detection and Classification by Deep Learning-A ReviewLê Kim HùngNoch keine Bewertungen
- Cyber Vulnerability Intelligence For Internet of Things BinaryDokument10 SeitenCyber Vulnerability Intelligence For Internet of Things BinaryLê Kim HùngNoch keine Bewertungen
- KFRNN An Effective False Data Injection Attack Detection in Smart Grid Based On Kalman Filter and Recurrent Neural NetworkDokument12 SeitenKFRNN An Effective False Data Injection Attack Detection in Smart Grid Based On Kalman Filter and Recurrent Neural NetworkLê Kim HùngNoch keine Bewertungen
- Multi-Channel Deep Feature Learning For Intrusion DetectionDokument14 SeitenMulti-Channel Deep Feature Learning For Intrusion DetectionLê Kim HùngNoch keine Bewertungen
- 1 s2.0 S0306437915001349 MainDokument17 Seiten1 s2.0 S0306437915001349 MainLê Kim HùngNoch keine Bewertungen
- Clean and Prepare Room For GuestDokument120 SeitenClean and Prepare Room For GuestElizabella Henrietta TanaquilNoch keine Bewertungen
- Huang Et Al. - 2016 - A Non-Parameter Outlier Detection Algorithm Based On Natural NeighborDokument7 SeitenHuang Et Al. - 2016 - A Non-Parameter Outlier Detection Algorithm Based On Natural NeighborLê Kim HùngNoch keine Bewertungen
- Survey SensorNetworkAnalytics 2012Dokument29 SeitenSurvey SensorNetworkAnalytics 2012Lê Kim HùngNoch keine Bewertungen
- Contextual Anomaly Detection Framework For Big Sensor DataDokument92 SeitenContextual Anomaly Detection Framework For Big Sensor DataLê Kim HùngNoch keine Bewertungen
- Internet of Things (IoT) - Hafedh Alyahmadi - May 29, 2015 PDFDokument40 SeitenInternet of Things (IoT) - Hafedh Alyahmadi - May 29, 2015 PDFKavita Saxena KhareNoch keine Bewertungen
- Sensing and Actuation As A Service, A Key Enabler For A New Cloud ParadigmDokument8 SeitenSensing and Actuation As A Service, A Key Enabler For A New Cloud ParadigmLê Kim HùngNoch keine Bewertungen
- An Scalable Iot Framework To Design Logical Data Flow Using Virtual SensorDokument7 SeitenAn Scalable Iot Framework To Design Logical Data Flow Using Virtual SensorLê Kim HùngNoch keine Bewertungen
- WSN Trends: Sensor Infrastructure Virtualization As A Driver Towards The Evolution of The Internet of ThingsDokument6 SeitenWSN Trends: Sensor Infrastructure Virtualization As A Driver Towards The Evolution of The Internet of ThingsLê Kim HùngNoch keine Bewertungen
- IOT TutorialDokument170 SeitenIOT TutorialLê Kim Hùng100% (1)
- Essay WritingDokument74 SeitenEssay Writingtiendn92% (50)
- 014 Snortinstallguide292Dokument12 Seiten014 Snortinstallguide292lyax1365Noch keine Bewertungen
- Estill Voice Training and Voice Quality Control in Contemporary Commercial Singing: An Exploratory StudyDokument8 SeitenEstill Voice Training and Voice Quality Control in Contemporary Commercial Singing: An Exploratory StudyVisal SasidharanNoch keine Bewertungen
- Gummy Bear Story RubricDokument1 SeiteGummy Bear Story Rubricapi-365008921Noch keine Bewertungen
- Menara PMB Assessment Criteria Score SummaryDokument2 SeitenMenara PMB Assessment Criteria Score SummarySyerifaizal Hj. MustaphaNoch keine Bewertungen
- Bankers ChoiceDokument18 SeitenBankers ChoiceArchana ThirunagariNoch keine Bewertungen
- Advanced Statistical Approaches To Quality: INSE 6220 - Week 4Dokument44 SeitenAdvanced Statistical Approaches To Quality: INSE 6220 - Week 4picalaNoch keine Bewertungen
- Computer in Community Pharmacy by Adnan Sarwar ChaudharyDokument10 SeitenComputer in Community Pharmacy by Adnan Sarwar ChaudharyDr-Adnan Sarwar Chaudhary100% (1)
- Onco Case StudyDokument2 SeitenOnco Case StudyAllenNoch keine Bewertungen
- Yojananov 2021Dokument67 SeitenYojananov 2021JackNoch keine Bewertungen
- Retail Visibility Project of AircelDokument89 SeitenRetail Visibility Project of Aircelabhishekkraj100% (1)
- Tanque: Equipment Data SheetDokument1 SeiteTanque: Equipment Data SheetAlonso DIAZNoch keine Bewertungen
- Reservoir Bag Physics J PhilipDokument44 SeitenReservoir Bag Physics J PhilipJashim JumliNoch keine Bewertungen
- GT I9100g Service SchematicsDokument8 SeitenGT I9100g Service SchematicsMassolo RoyNoch keine Bewertungen
- Unit 2 Operations of PolynomialsDokument28 SeitenUnit 2 Operations of Polynomialsapi-287816312Noch keine Bewertungen
- Module 4 How To Make Self-Rescue Evacuation Maps?Dokument85 SeitenModule 4 How To Make Self-Rescue Evacuation Maps?RejieNoch keine Bewertungen
- 30 de Thi Hoc Ky 2 Mon Tieng Anh Lop 9 Co Dap An 2023Dokument64 Seiten30 de Thi Hoc Ky 2 Mon Tieng Anh Lop 9 Co Dap An 2023Trần MaiNoch keine Bewertungen
- Pepcoding - Coding ContestDokument2 SeitenPepcoding - Coding ContestAjay YadavNoch keine Bewertungen
- Financial Statement AnalysisDokument18 SeitenFinancial Statement AnalysisAbdul MajeedNoch keine Bewertungen
- Intraoperative RecordDokument2 SeitenIntraoperative Recordademaala06100% (1)
- A Project Report On "A Comparative Study Between Hero Honda Splendor+ and Its Competitors To Increase The Market Share in MUDHOL RegionDokument70 SeitenA Project Report On "A Comparative Study Between Hero Honda Splendor+ and Its Competitors To Increase The Market Share in MUDHOL RegionBabasab Patil (Karrisatte)Noch keine Bewertungen
- Credit Risk ManagementDokument64 SeitenCredit Risk Managementcherry_nu100% (12)
- Name: Mercado, Kath DATE: 01/15 Score: Activity Answer The Following Items On A Separate Sheet of Paper. Show Your Computations. (4 Items X 5 Points)Dokument2 SeitenName: Mercado, Kath DATE: 01/15 Score: Activity Answer The Following Items On A Separate Sheet of Paper. Show Your Computations. (4 Items X 5 Points)Kathleen MercadoNoch keine Bewertungen
- Genie PDFDokument264 SeitenGenie PDFjohanaNoch keine Bewertungen
- CSR Report On Tata SteelDokument72 SeitenCSR Report On Tata SteelJagadish Sahu100% (1)
- Industry and Community Project: Jacobs - Creating A Smart Systems Approach To Future Cities Project OutlineDokument14 SeitenIndustry and Community Project: Jacobs - Creating A Smart Systems Approach To Future Cities Project OutlineCalebNoch keine Bewertungen
- Corporate Valuation WhartonDokument6 SeitenCorporate Valuation Whartonebrahimnejad64Noch keine Bewertungen
- Data Structures and Algorithms SyllabusDokument9 SeitenData Structures and Algorithms SyllabusBongbong GalloNoch keine Bewertungen
- Army Watercraft SafetyDokument251 SeitenArmy Watercraft SafetyPlainNormalGuy2Noch keine Bewertungen
- The Global Entrepreneurship and Development Index 2014 For Web1 PDFDokument249 SeitenThe Global Entrepreneurship and Development Index 2014 For Web1 PDFAlex Yuri Rodriguez100% (1)
- GSM Radio ConceptsDokument3 SeitenGSM Radio ConceptsMD SahidNoch keine Bewertungen
- Ezpdf Reader 1 9 8 1Dokument1 SeiteEzpdf Reader 1 9 8 1AnthonyNoch keine Bewertungen