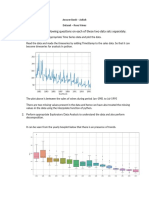
Das könnte Ihnen auch gefallen
- FRA ReportDokument30 SeitenFRA ReportRaja Sekhar P100% (1)
- Clustering Analysis: Prepared by Muralidharan NDokument16 SeitenClustering Analysis: Prepared by Muralidharan Nrakesh sandhyapoguNoch keine Bewertungen
- Data Mining Project - 27.06.2021Dokument6 SeitenData Mining Project - 27.06.2021vansh guptaNoch keine Bewertungen
- Time Series ForecastingDokument1 SeiteTime Series ForecastingAshu0% (1)
- Statisitics Project 6Dokument48 SeitenStatisitics Project 6AMAN PRAKASH100% (2)
- Data Science & Business Analytics: Post Graduate Program inDokument16 SeitenData Science & Business Analytics: Post Graduate Program inbalaNoch keine Bewertungen
- MRA Project Milestone2 PDFDokument1 SeiteMRA Project Milestone2 PDFRekha Rajaram100% (1)
- DM Gopala Satish Kumar Business Report G8 DSBADokument26 SeitenDM Gopala Satish Kumar Business Report G8 DSBASatish Kumar100% (2)
- Customer Churn Prediction in ECommerce SectorDokument40 SeitenCustomer Churn Prediction in ECommerce SectorChinmay Danaraddi100% (1)
- Factor-Hair RV PDFDokument23 SeitenFactor-Hair RV PDFRamachandran VenkataramanNoch keine Bewertungen
- MRA Project Milestone 2Dokument31 SeitenMRA Project Milestone 2Puvya Ravi100% (1)
- Extended Project FastKart SQLite MYSQL 1 1 PDFDokument5 SeitenExtended Project FastKart SQLite MYSQL 1 1 PDFAmey UdapureNoch keine Bewertungen
- AS Notebook - PCA - Wine Data-4Dokument1 SeiteAS Notebook - PCA - Wine Data-4Pranali Malode100% (1)
- Time+Series+Forecasting MonographDokument58 SeitenTime+Series+Forecasting MonographAvinash ShuklaNoch keine Bewertungen
- David R Brillinger Time Series Data Analysis and Theory 2001 CompressDokument561 SeitenDavid R Brillinger Time Series Data Analysis and Theory 2001 CompresssumantadasdrdoNoch keine Bewertungen
- Analyze House Price For King CountyDokument15 SeitenAnalyze House Price For King CountyyshprasdNoch keine Bewertungen
- Data Mining Business ReportDokument38 SeitenData Mining Business ReportThaku SinghNoch keine Bewertungen
- LDA KNN LogisticDokument29 SeitenLDA KNN Logisticshruti gujar100% (1)
- Business Report TSF - Rose DataSetDokument52 SeitenBusiness Report TSF - Rose DataSetCharit Sharma100% (2)
- NIrupam Agarwal Business Report-MLDokument23 SeitenNIrupam Agarwal Business Report-MLNirupam AgarwalNoch keine Bewertungen
- TimeSeries ReportDokument41 SeitenTimeSeries ReportSukanya ManickavelNoch keine Bewertungen
- Sunira - Predictive ModelingDokument65 SeitenSunira - Predictive ModelingDeepanshu ParasharNoch keine Bewertungen
- Time Series Forecasting Business Report: Name: S.Krishna Veni Date: 20/02/2022Dokument31 SeitenTime Series Forecasting Business Report: Name: S.Krishna Veni Date: 20/02/2022Krishna Veni100% (1)
- Predictive Model: Submitted byDokument27 SeitenPredictive Model: Submitted byAnkita Mishra100% (1)
- Suresh-Rose Time Series Forecasting Project ReportDokument75 SeitenSuresh-Rose Time Series Forecasting Project ReportARCHANA R100% (1)
- Project Predictive Modeling PDFDokument58 SeitenProject Predictive Modeling PDFAYUSH AWASTHINoch keine Bewertungen
- Quiz 3 Name: Kainat Iftikhar Reg# 2021630007 1. List Three Examples of Time Series Data. Time Series DataDokument2 SeitenQuiz 3 Name: Kainat Iftikhar Reg# 2021630007 1. List Three Examples of Time Series Data. Time Series Dataraja ahmedNoch keine Bewertungen
- Anshul Dyundi Predictive Modelling Alternate Project July 2022Dokument11 SeitenAnshul Dyundi Predictive Modelling Alternate Project July 2022Anshul DyundiNoch keine Bewertungen
- Capstone Project SubmissionDokument31 SeitenCapstone Project Submissionguruss604684Noch keine Bewertungen
- PM ProjectJune - 2021Dokument33 SeitenPM ProjectJune - 2021Abhishek Roy100% (1)
- Project - Time Series Forecasting (Sparkling - CSV) & (Rose - CSV)Dokument15 SeitenProject - Time Series Forecasting (Sparkling - CSV) & (Rose - CSV)guillermo cocoNoch keine Bewertungen
- Mra Project - Milestone1: Student Name: Gowri Srinivasan Batch: Dsba Online Mar 20Dokument30 SeitenMra Project - Milestone1: Student Name: Gowri Srinivasan Batch: Dsba Online Mar 20Sania QamarNoch keine Bewertungen
- Linear RegressionDokument15 SeitenLinear RegressionAnil Bera67% (3)
- CafeSales MRA PresentationDokument40 SeitenCafeSales MRA PresentationKyotoNoch keine Bewertungen
- DSBAProject Oct 2020Dokument24 SeitenDSBAProject Oct 2020Abhay PoddarNoch keine Bewertungen
- Project Predictive ModelingDokument69 SeitenProject Predictive Modelingyuktha50% (2)
- Girish Chadha - 29th December 2022Dokument35 SeitenGirish Chadha - 29th December 2022Girish Chadha100% (3)
- Data Mining Assignment: Sudhanva SaralayaDokument16 SeitenData Mining Assignment: Sudhanva SaralayaSudhanva S100% (1)
- Machine Learning - Nabeel Khan - Final Project Report - Problem 2Dokument24 SeitenMachine Learning - Nabeel Khan - Final Project Report - Problem 2KhursheedKhan100% (1)
- Travel Agency PackageDokument26 SeitenTravel Agency PackageKATHIRVEL SNoch keine Bewertungen
- Ashish BR 19-12-21Dokument65 SeitenAshish BR 19-12-21Ashish Pavan Kumar KNoch keine Bewertungen
- Machine Learning Business Report - Compress (AutoRecovered)Dokument69 SeitenMachine Learning Business Report - Compress (AutoRecovered)Deepanshu Parashar100% (2)
- Answer Book - Rose WinesDokument11 SeitenAnswer Book - Rose WinesAshish Agrawal100% (1)
- Business Report Data MiningDokument29 SeitenBusiness Report Data Mininghepzi selvamNoch keine Bewertungen
- MRA Project - Shehroz KhanDokument19 SeitenMRA Project - Shehroz KhanShehroz Khan67% (3)
- Cart-Rf-ANN: Prepared by Muralidharan NDokument16 SeitenCart-Rf-ANN: Prepared by Muralidharan NKrishnaveni Raj0% (1)
- FRA AssignmentDokument31 SeitenFRA AssignmentPranav ViswanathanNoch keine Bewertungen
- Time Series Rose Shehroz ArfeenDokument42 SeitenTime Series Rose Shehroz ArfeenShehroz Khan100% (1)
- Tableau QuestionsDokument2 SeitenTableau QuestionsGhulamNoch keine Bewertungen
- ML Assignemnt PDFDokument21 SeitenML Assignemnt PDFEric NormanNoch keine Bewertungen
- Financial Risk Analytics: ProjectreportDokument94 SeitenFinancial Risk Analytics: ProjectreportFiza ssNoch keine Bewertungen
- Arnab Chowdhury As1Dokument12 SeitenArnab Chowdhury As1ARNAB CHOWDHURY.Noch keine Bewertungen
- Marketing & Retail Analytics - Report - Part ADokument18 SeitenMarketing & Retail Analytics - Report - Part AAshish Agrawal100% (2)
- Time Series and ForecastingDokument3 SeitenTime Series and ForecastingkaviyapriyaNoch keine Bewertungen
- Capstone ProjectDokument7 SeitenCapstone ProjectSurya PhaniNoch keine Bewertungen
- Data Mining Project ReportDokument98 SeitenData Mining Project Reportpadma medariNoch keine Bewertungen
- Data Mining Clustering PDFDokument15 SeitenData Mining Clustering PDFSwing TradeNoch keine Bewertungen
- Project QuestionsDokument3 SeitenProject QuestionsravikgovinduNoch keine Bewertungen
- Business Report On Data Mining: By: Aditya Janardan Hajare Batch: PGPDSBA Mar'C21 Group 1Dokument18 SeitenBusiness Report On Data Mining: By: Aditya Janardan Hajare Batch: PGPDSBA Mar'C21 Group 1Aditya HajareNoch keine Bewertungen
- Clustering ProjectDokument44 SeitenClustering Projectkirti sharma100% (1)
- DataMining Aug2021Dokument49 SeitenDataMining Aug2021sakshi narang100% (1)
- Andreas Behr (Auth.) - Production and Efficiency Analysis With R (2015, Springer International Publishing) PDFDokument235 SeitenAndreas Behr (Auth.) - Production and Efficiency Analysis With R (2015, Springer International Publishing) PDFcrissyosserNoch keine Bewertungen
- CS771 IITK EndSem SolutionsDokument8 SeitenCS771 IITK EndSem SolutionsAnujNagpal100% (1)
- Endsem PDFDokument16 SeitenEndsem PDFAnujNagpalNoch keine Bewertungen
- Camera Angles (Part 1)Dokument18 SeitenCamera Angles (Part 1)AnujNagpalNoch keine Bewertungen
- TA-201 Lab MannualDokument19 SeitenTA-201 Lab MannualAnujNagpalNoch keine Bewertungen
- Primality v6 PrimesIsInPDokument9 SeitenPrimality v6 PrimesIsInPwoodbrent7Noch keine Bewertungen
- EXTC Advanced Digital Signal ProcessingDokument7 SeitenEXTC Advanced Digital Signal Processingsumit sanchetiNoch keine Bewertungen
- 20 A Long-Run and Short-Run Component Model of Stock Return VolatilityDokument23 Seiten20 A Long-Run and Short-Run Component Model of Stock Return Volatilityrob-engleNoch keine Bewertungen
- Time Series Analysis in Python With StatsmodelsDokument8 SeitenTime Series Analysis in Python With StatsmodelsChong Hoo ChuahNoch keine Bewertungen
- Time Series Forecasting (Australian Gas) : Akalya KSDokument15 SeitenTime Series Forecasting (Australian Gas) : Akalya KSstudent loginNoch keine Bewertungen
- Stochastic Models, Information Theory, and Lie Groups, Volume 1 (Gregory S. Chirikjian)Dokument395 SeitenStochastic Models, Information Theory, and Lie Groups, Volume 1 (Gregory S. Chirikjian)王舜緯100% (1)
- Testing Seasonal Unit Roots in Data at Any FrequencyDokument35 SeitenTesting Seasonal Unit Roots in Data at Any FrequencyViorel AdirvaNoch keine Bewertungen
- Panel Unit Root Tests - A Review PDFDokument57 SeitenPanel Unit Root Tests - A Review PDFDimitris AnastasiouNoch keine Bewertungen
- Rutgers: 332:322 Principles of Communications Systems Spring 2004Dokument8 SeitenRutgers: 332:322 Principles of Communications Systems Spring 2004srattovNoch keine Bewertungen
- Spatial Variation of Seismic Ground Motions PDFDokument27 SeitenSpatial Variation of Seismic Ground Motions PDFahm2011100% (1)
- Guideline For Offshore Structural Reliability Analysis (Aplication To Tension Leg Platforms) DNVDokument66 SeitenGuideline For Offshore Structural Reliability Analysis (Aplication To Tension Leg Platforms) DNVfranciscoerezNoch keine Bewertungen
- Ch7 SlidesDokument71 SeitenCh7 SlidesthelastsevenNoch keine Bewertungen
- GDP Forecasting Using Time Series AnalysisDokument15 SeitenGDP Forecasting Using Time Series AnalysisAnujNagpalNoch keine Bewertungen
- Arimax ArimaDokument57 SeitenArimax ArimaTeresaMadurai100% (1)
- M Tech Ec SyllabusDokument13 SeitenM Tech Ec SyllabusDhaval PatelNoch keine Bewertungen
- Establishing The Effectiveness of Market Ratios in Predicting Financial Distress of Listed Firms in Nairobi Security Exchange MarketDokument13 SeitenEstablishing The Effectiveness of Market Ratios in Predicting Financial Distress of Listed Firms in Nairobi Security Exchange MarketOIRCNoch keine Bewertungen
- Chapter No.1Dokument53 SeitenChapter No.1sohaibNoch keine Bewertungen
- Rational Bubbles in The Real Housing Stock MarketDokument13 SeitenRational Bubbles in The Real Housing Stock MarketFrancisco ValdésNoch keine Bewertungen
- Last Time TodayDokument34 SeitenLast Time TodayHarshvardhan SinghNoch keine Bewertungen
- Development of Geospatial Models For Multi-Criteria Decision Making in Traffic Environmental Impacts of Heavy Vehicle Freight TransportationDokument196 SeitenDevelopment of Geospatial Models For Multi-Criteria Decision Making in Traffic Environmental Impacts of Heavy Vehicle Freight TransportationTaal TablaNoch keine Bewertungen
- Time Series EconometricsDokument223 SeitenTime Series Econometricsfenomanana100% (1)
- BSC Honours in Statistics: HSTS 203: Time Series Analysis University of ZimbabweDokument6 SeitenBSC Honours in Statistics: HSTS 203: Time Series Analysis University of ZimbabweKeith Tanyaradzwa MushiningaNoch keine Bewertungen
- When Is An Autoregressive Model Dynamically Stable - v3.2Dokument17 SeitenWhen Is An Autoregressive Model Dynamically Stable - v3.2RaghavanNoch keine Bewertungen
- Spatial Statistical and Multivariate Regression Approach To Earthwork Shrinkage-Factor CalculationDokument168 SeitenSpatial Statistical and Multivariate Regression Approach To Earthwork Shrinkage-Factor CalculationChandana SarkarNoch keine Bewertungen
- Stationary ProcessDokument178 SeitenStationary ProcessMohamed AsimNoch keine Bewertungen
- Assignment 4Dokument2 SeitenAssignment 4Priya RadhakrishnanNoch keine Bewertungen
- Stationarity, Cointegration: Arnaud Chevalier University College Dublin January 2004Dokument52 SeitenStationarity, Cointegration: Arnaud Chevalier University College Dublin January 2004Josh2002Noch keine Bewertungen
- Jrpo D 23 00182Dokument22 SeitenJrpo D 23 00182saeedNoch keine Bewertungen
- Real-Time Temperature Anomaly Detection Method For IoT DataDokument7 SeitenReal-Time Temperature Anomaly Detection Method For IoT DataGhaida BouchâalaNoch keine Bewertungen