Das könnte Ihnen auch gefallen
- BackPropagation Through TimeDokument6 SeitenBackPropagation Through Timemilan gemerskyNoch keine Bewertungen
- Fourier Analysis Derives Closed Form of Zeta Function at Even IntegersDokument6 SeitenFourier Analysis Derives Closed Form of Zeta Function at Even IntegersCreative MathNoch keine Bewertungen
- Assignment 5Dokument3 SeitenAssignment 5Minh LuanNoch keine Bewertungen
- ' - Magic: Recovery of Sparse Signals Via Convex ProgrammingDokument19 Seiten' - Magic: Recovery of Sparse Signals Via Convex ProgrammingLan VũNoch keine Bewertungen
- Machine Learning 2: Exercise Sheet 1Dokument2 SeitenMachine Learning 2: Exercise Sheet 1Surya IyerNoch keine Bewertungen
- NNLS1 2019 HW4 SolutionsDokument11 SeitenNNLS1 2019 HW4 SolutionsADSTE ETWNoch keine Bewertungen
- Fe Industrial EngineeringDokument14 SeitenFe Industrial Engineeringvzimak2355Noch keine Bewertungen
- Sparse Regression and Dictionary LearningDokument14 SeitenSparse Regression and Dictionary LearningmamurtazaNoch keine Bewertungen
- Notes On Newton-Cotes QuadratureDokument5 SeitenNotes On Newton-Cotes QuadratureMatija VasilevNoch keine Bewertungen
- TaleextraDokument15 SeitenTaleextraIlja MeijerNoch keine Bewertungen
- ML Lecture06 2Dokument63 SeitenML Lecture06 2Marche RemiNoch keine Bewertungen
- (Part 1: Linear Algebra Concepts Part 2: Orthogonality of FCNS, Intro To Fourier Series) (Haberman Sect 5.5 App) (Continuing From Last Time... )Dokument6 Seiten(Part 1: Linear Algebra Concepts Part 2: Orthogonality of FCNS, Intro To Fourier Series) (Haberman Sect 5.5 App) (Continuing From Last Time... )Alexander BennettNoch keine Bewertungen
- APA Chapter3 T20Dokument24 SeitenAPA Chapter3 T20XxXavillitoxX 5Noch keine Bewertungen
- Class05 LogisticsSVMDokument33 SeitenClass05 LogisticsSVMtimetif286Noch keine Bewertungen
- Bit-And Power-Loading: EIT 140, Tom AT Eit - Lth.seDokument26 SeitenBit-And Power-Loading: EIT 140, Tom AT Eit - Lth.sedeepa2400Noch keine Bewertungen
- InterpolationDokument54 SeitenInterpolationEdwin Okoampa BoaduNoch keine Bewertungen
- Lecture25 PsDokument10 SeitenLecture25 PsSanthosh InigoeNoch keine Bewertungen
- 2 - Discrete-Time Signals: 1 For 0 N N 1 0 OtherwiseDokument4 Seiten2 - Discrete-Time Signals: 1 For 0 N N 1 0 OtherwiseKhalil El LejriNoch keine Bewertungen
- 2.4.1 Length of A Plane Curve - NotesDokument5 Seiten2.4.1 Length of A Plane Curve - NotesKelseyNoch keine Bewertungen
- Nonlinear SVM Classification Using KernelsDokument37 SeitenNonlinear SVM Classification Using KernelsmalikdmaNoch keine Bewertungen
- Wwwwrtyyu FGDHDokument25 SeitenWwwwrtyyu FGDHSaad KhNoch keine Bewertungen
- Ass3 609Dokument2 SeitenAss3 609Nakul singhNoch keine Bewertungen
- DSP Lab: Parametric Spectrum EstimationDokument6 SeitenDSP Lab: Parametric Spectrum EstimationrahehaqguestsNoch keine Bewertungen
- MTL411 - Functional Analysis: N P N I 1 P P NDokument1 SeiteMTL411 - Functional Analysis: N P N I 1 P P NUtsavNoch keine Bewertungen
- 1D Bar Element Fe Formulation From GdeDokument15 Seiten1D Bar Element Fe Formulation From GdeHrithik GoyalNoch keine Bewertungen
- HW 4 SolutionsDokument5 SeitenHW 4 SolutionsKiran AdhikariNoch keine Bewertungen
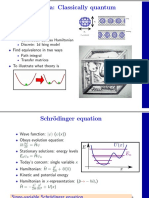
- Particle in a Box Energy LevelsDokument16 SeitenParticle in a Box Energy LevelsAsmayanti GufranNoch keine Bewertungen
- Binomial Coefficient Identity Implies Beukers' ConjectureDokument3 SeitenBinomial Coefficient Identity Implies Beukers' ConjectureOscar GutierrezNoch keine Bewertungen
- SEEMOUS 2009 ProblemsDokument4 SeitenSEEMOUS 2009 ProblemsHipstersdssadadNoch keine Bewertungen
- Penney Kronig ModelDokument10 SeitenPenney Kronig ModelsarmasarmatejaNoch keine Bewertungen
- ME5204 Finite Element Analysis: Class 7: Piecewise Linear Finite Elements and Properties of The Stiffness MatrixDokument13 SeitenME5204 Finite Element Analysis: Class 7: Piecewise Linear Finite Elements and Properties of The Stiffness MatrixObulapuram Sai Pavan Kumar me17b157Noch keine Bewertungen
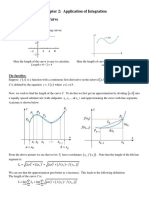
- Integration: Area and Estimating Finite SumsDokument12 SeitenIntegration: Area and Estimating Finite SumsFahrettin CakirNoch keine Bewertungen
- MTH4100 Calculus I: Lecture Notes For Week 10 Thomas' Calculus, Sections 5.2 To 5.5Dokument12 SeitenMTH4100 Calculus I: Lecture Notes For Week 10 Thomas' Calculus, Sections 5.2 To 5.5Roy VeseyNoch keine Bewertungen
- ECS 171: Machine Learning: Lecture 16: Matrix Completion, Word EmbeddingDokument34 SeitenECS 171: Machine Learning: Lecture 16: Matrix Completion, Word EmbeddingSam DillingerNoch keine Bewertungen
- 2015 - Ma - Energy-Efficient Reconstruction of Compressively Sensed Bioelectrical Signals With Stochastic Computing CircuitsDokument4 Seiten2015 - Ma - Energy-Efficient Reconstruction of Compressively Sensed Bioelectrical Signals With Stochastic Computing CircuitsDaniel Prado de CamposNoch keine Bewertungen
- Lecture - 01 - Basic Concepts About Metric Spaces and ExamplesDokument4 SeitenLecture - 01 - Basic Concepts About Metric Spaces and ExamplesdnyNoch keine Bewertungen
- ch7 PDFDokument33 Seitench7 PDFAndrew BorgNoch keine Bewertungen
- Hints To Problems On Fundamentals of Vector SpacesDokument6 SeitenHints To Problems On Fundamentals of Vector SpaceschandrahasNoch keine Bewertungen
- Problem Set 6 SolutionDokument3 SeitenProblem Set 6 SolutionSourajit RoyNoch keine Bewertungen
- Support Vector Machines for ClassificationDokument84 SeitenSupport Vector Machines for ClassificationAkustika HorozNoch keine Bewertungen
- Experiment 10Dokument3 SeitenExperiment 10Abhishek SharmaNoch keine Bewertungen
- Example ProblemsDokument104 SeitenExample ProblemssignatureHNoch keine Bewertungen
- Simulation Power ElectronicDokument5 SeitenSimulation Power Electronicchroeun sokayNoch keine Bewertungen
- HW7 ManualDokument19 SeitenHW7 ManualDmitrii GudinNoch keine Bewertungen
- 12-3: Fourier Series with Period 2π: Prakash Balachandran Department of Mathematics Duke University April 5, 2010Dokument2 Seiten12-3: Fourier Series with Period 2π: Prakash Balachandran Department of Mathematics Duke University April 5, 2010gizeaNoch keine Bewertungen
- Chapter2 Further Integration TechniquesDokument23 SeitenChapter2 Further Integration TechniquesShaundre NeoNoch keine Bewertungen
- Fundamental Approximation Theorems: Kunal Narayan ChaudhuryDokument4 SeitenFundamental Approximation Theorems: Kunal Narayan Chaudhuryabd 01Noch keine Bewertungen
- Dis10 Sol PDFDokument6 SeitenDis10 Sol PDFAlua KadyrbekNoch keine Bewertungen
- Physics Challenge For Teachers and Students: A BLT SandwichDokument3 SeitenPhysics Challenge For Teachers and Students: A BLT Sandwichcuongnguyendinh100% (1)
- Linear Regression Lecture NotesDokument11 SeitenLinear Regression Lecture NotesbprtxrcqilmqsvsdhrNoch keine Bewertungen
- Lower bounds for first order optimization algorithmsDokument9 SeitenLower bounds for first order optimization algorithmsFaragNoch keine Bewertungen
- Extreme Points and Basic SolutionsDokument4 SeitenExtreme Points and Basic SolutionsHillal TOUATINoch keine Bewertungen
- TMA 4180 Optimeringsteori Variational Calculus and Classical MechanicsDokument9 SeitenTMA 4180 Optimeringsteori Variational Calculus and Classical MechanicsshalukprNoch keine Bewertungen
- Synthesis of Wavelet Filters Using WaveletDokument4 SeitenSynthesis of Wavelet Filters Using WaveletWajdi BELLILNoch keine Bewertungen
- HW2 Solutions PDFDokument12 SeitenHW2 Solutions PDFchirag sharmaNoch keine Bewertungen
- Homework For Module 3 Part 1 PDFDokument3 SeitenHomework For Module 3 Part 1 PDFSai Chaitanya GudariNoch keine Bewertungen
- Mathematical Sci. Paper 2 PDFDokument7 SeitenMathematical Sci. Paper 2 PDFعنترة بن شدادNoch keine Bewertungen
- Polynomial Coefficients and Distribution of The Sum of Discrete Uniform VariablesDokument13 SeitenPolynomial Coefficients and Distribution of The Sum of Discrete Uniform VariablesNikhil DikshitNoch keine Bewertungen
- Nonlinear Functional Analysis and Applications: Proceedings of an Advanced Seminar Conducted by the Mathematics Research Center, the University of Wisconsin, Madison, October 12-14, 1970Von EverandNonlinear Functional Analysis and Applications: Proceedings of an Advanced Seminar Conducted by the Mathematics Research Center, the University of Wisconsin, Madison, October 12-14, 1970Louis B. RallNoch keine Bewertungen
- Tables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesVon EverandTables of The Legendre Functions P—½+it(x): Mathematical Tables SeriesNoch keine Bewertungen
- J K Shah Classes Class Room Test: Syjc Feb' 19Dokument12 SeitenJ K Shah Classes Class Room Test: Syjc Feb' 19Govardhan ReghuramNoch keine Bewertungen
- Using Artificial Bee Colony Algorithm FoDokument8 SeitenUsing Artificial Bee Colony Algorithm FoSama TaleeNoch keine Bewertungen
- Ch13 - NLP, DP, GP2005Dokument76 SeitenCh13 - NLP, DP, GP2005Sonya DewiNoch keine Bewertungen
- DS Ex1Dokument21 SeitenDS Ex1jeff omangaNoch keine Bewertungen
- Artificial Intelligence Heuristics in Solving Vehicle Routing Problems With Time Window ConstraintsDokument13 SeitenArtificial Intelligence Heuristics in Solving Vehicle Routing Problems With Time Window ConstraintsDiego Alejandro MejiaNoch keine Bewertungen
- Diploma - PracticalDokument11 SeitenDiploma - PracticalGunaNoch keine Bewertungen
- CEB 311 - Stochastic Vs Deterministic Models - Pros N ConsDokument19 SeitenCEB 311 - Stochastic Vs Deterministic Models - Pros N Consakawunggabriel23Noch keine Bewertungen
- Experiment 5 AIM:Write A Program To Design Proportional, Proportional+Integral, Proportional+Dokument4 SeitenExperiment 5 AIM:Write A Program To Design Proportional, Proportional+Integral, Proportional+saumya desaiNoch keine Bewertungen
- Modeling A Pin Connection Between Crossing MembersDokument5 SeitenModeling A Pin Connection Between Crossing MembersMauricio_Vera_5259Noch keine Bewertungen
- Risk analysis techniques for capital budgeting decisionsDokument59 SeitenRisk analysis techniques for capital budgeting decisionsDiptish RamtekeNoch keine Bewertungen
- 2017fall SyllabusDokument3 Seiten2017fall SyllabusPerry RaskinNoch keine Bewertungen
- Casagrade CalculationDokument7 SeitenCasagrade CalculationDamian AlexanderNoch keine Bewertungen
- AI & DS - AD3351 DAA - 2marks (Unit 1 & 2) Question BankDokument7 SeitenAI & DS - AD3351 DAA - 2marks (Unit 1 & 2) Question BankDHANYANoch keine Bewertungen
- Cholesky DecompositionDokument4 SeitenCholesky DecompositionislamNoch keine Bewertungen
- Lecture - Notes - II PseudocodeDokument30 SeitenLecture - Notes - II PseudocodemphullatwambilireNoch keine Bewertungen
- Stack, Queue and Heap Data Structures Intermediate Level QuestionsDokument6 SeitenStack, Queue and Heap Data Structures Intermediate Level QuestionsAnonymous GeekNoch keine Bewertungen
- TW 11 ADokument11 SeitenTW 11 ASwapna ThoutiNoch keine Bewertungen
- Y = β β x y xDokument6 SeitenY = β β x y xdolly kate cagadasNoch keine Bewertungen
- Mathematical and Computational Methods For Compressible FlowDokument8 SeitenMathematical and Computational Methods For Compressible FlowmacromoleculeNoch keine Bewertungen
- FIR and IIR Filter Design TechniquesDokument55 SeitenFIR and IIR Filter Design TechniquesShanmuka ReddyNoch keine Bewertungen
- Submitted To: Mohammed Mosleh-Uddin School and Business Economics Subject: Business Statistics Course Code: BUS 511Dokument6 SeitenSubmitted To: Mohammed Mosleh-Uddin School and Business Economics Subject: Business Statistics Course Code: BUS 511Arindam BardhanNoch keine Bewertungen
- Rumor Riding: Anonymizing Unstructured Peer-to-Peer SystemsDokument31 SeitenRumor Riding: Anonymizing Unstructured Peer-to-Peer SystemsKarthi KeyanNoch keine Bewertungen
- Finding Roots Methods ComparisonDokument18 SeitenFinding Roots Methods ComparisonRenu Bharat KewalramaniNoch keine Bewertungen
- Numerical Methods On Finding The RootsDokument26 SeitenNumerical Methods On Finding The RootsRobby Andre ChingNoch keine Bewertungen
- Teaching DemoDokument50 SeitenTeaching DemoRoqui M. GonzagaNoch keine Bewertungen
- Problem E: Cat and MouseDokument2 SeitenProblem E: Cat and MouseHello misterNoch keine Bewertungen
- Lesson 2 Arithmetic SequenceDokument27 SeitenLesson 2 Arithmetic SequenceLady Ann LugoNoch keine Bewertungen
- Dsa (10-8-2012)Dokument11 SeitenDsa (10-8-2012)HenryHai NguyenNoch keine Bewertungen
- Business Analytics June 2022 CalendarDokument1 SeiteBusiness Analytics June 2022 CalendarKowshik KunduNoch keine Bewertungen
- Credit Modelling - Survival Models: 1 Random VariablesDokument5 SeitenCredit Modelling - Survival Models: 1 Random VariablesandrewNoch keine Bewertungen