Das könnte Ihnen auch gefallen
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- The Ethics in Artificial Intelligence: Are Intelligent Machines Friend or Foe?Dokument43 SeitenThe Ethics in Artificial Intelligence: Are Intelligent Machines Friend or Foe?Kristian Marlowe OleNoch keine Bewertungen
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- B.V. Patel Umarakh.: Guided BY: Shaunak DesaiDokument28 SeitenB.V. Patel Umarakh.: Guided BY: Shaunak DesaiKristian Marlowe OleNoch keine Bewertungen
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Pharmacy Professional Ethics: Lecture - 2 Topic: The Professional Decision-Making ProcessDokument23 SeitenPharmacy Professional Ethics: Lecture - 2 Topic: The Professional Decision-Making ProcessKristian Marlowe OleNoch keine Bewertungen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- Third Quarter 2004 Results and Fourth Quarter Guidance October 21, 2004Dokument31 SeitenThird Quarter 2004 Results and Fourth Quarter Guidance October 21, 2004Kristian Marlowe OleNoch keine Bewertungen
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Ethics in Artificial Intelligence: Are Intelligent Machines Friend or Foe?Dokument43 SeitenThe Ethics in Artificial Intelligence: Are Intelligent Machines Friend or Foe?Kristian Marlowe OleNoch keine Bewertungen
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- Is Seeing Believing? Living in A Digital WorldDokument39 SeitenIs Seeing Believing? Living in A Digital WorldKristian Marlowe OleNoch keine Bewertungen
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (400)
- A Report On Papercrete: Submitted By:Anurag Singh B.Arch 3 Year Roll No.: 14Dokument41 SeitenA Report On Papercrete: Submitted By:Anurag Singh B.Arch 3 Year Roll No.: 14Kristian Marlowe OleNoch keine Bewertungen
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- PAPERCRETE-Towards A New Beginning: CategoryDokument25 SeitenPAPERCRETE-Towards A New Beginning: CategoryKristian Marlowe OleNoch keine Bewertungen
- Welcome: Presented By: Tanya SharmaDokument16 SeitenWelcome: Presented By: Tanya SharmaKristian Marlowe OleNoch keine Bewertungen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Composite Materials Uc5713-Jil Sheth Uc1813-Keshav SharmaDokument18 SeitenComposite Materials Uc5713-Jil Sheth Uc1813-Keshav SharmaKristian Marlowe OleNoch keine Bewertungen
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Businessplancoffeeshop 130224072102 Phpapp02 PDFDokument22 SeitenBusinessplancoffeeshop 130224072102 Phpapp02 PDFKristian Marlowe OleNoch keine Bewertungen
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Maintenance Engineering: Anirudh GoyalDokument24 SeitenMaintenance Engineering: Anirudh GoyalKristian Marlowe OleNoch keine Bewertungen
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Indian AgricultureDokument16 SeitenIndian AgricultureKristian Marlowe OleNoch keine Bewertungen
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (74)
- How The New Dog Laws Affect You, The Owner/GuardianDokument35 SeitenHow The New Dog Laws Affect You, The Owner/GuardianKristian Marlowe OleNoch keine Bewertungen
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (345)
- Pressure Is Defined As Force Per Unit Area or P F / A P (800 N) / (2.0 M) P 400 N / M 400 PaDokument1 SeitePressure Is Defined As Force Per Unit Area or P F / A P (800 N) / (2.0 M) P 400 N / M 400 PaKristian Marlowe OleNoch keine Bewertungen
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- NumberseverymarketershouldknowDokument13 SeitenNumberseverymarketershouldknowKristian Marlowe OleNoch keine Bewertungen
- Reliability Engineering: Fred SchenkelbergDokument29 SeitenReliability Engineering: Fred SchenkelbergKristian Marlowe OleNoch keine Bewertungen
- The Elements and Principles of Art DesignDokument17 SeitenThe Elements and Principles of Art DesignKristian Marlowe OleNoch keine Bewertungen
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- A Lesson in The American Artistic Movement : by Aja Alim-YoungDokument14 SeitenA Lesson in The American Artistic Movement : by Aja Alim-YoungKristian Marlowe OleNoch keine Bewertungen
- Isabelo Clarissa: My Family TreeDokument1 SeiteIsabelo Clarissa: My Family TreeKristian Marlowe OleNoch keine Bewertungen
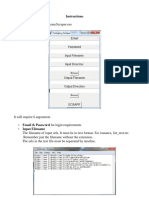
- InstructionDokument2 SeitenInstructionKristian Marlowe OleNoch keine Bewertungen
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- Homework 1: EE 737 Spring 2019-20 Assigned: 30 Jan Due: Beginning of Class, 06 FebDokument2 SeitenHomework 1: EE 737 Spring 2019-20 Assigned: 30 Jan Due: Beginning of Class, 06 FebAnkit Pal100% (1)
- An Introduction To Support Vector Machines and Other Kernel-Based Learning MethodsDokument214 SeitenAn Introduction To Support Vector Machines and Other Kernel-Based Learning Methodszhmzy100% (1)
- CH 12Dokument37 SeitenCH 12yashwanthr3Noch keine Bewertungen
- Machine LearningDokument73 SeitenMachine LearningtesscarcamoNoch keine Bewertungen
- Advances in Neural Information Processing SystemsDokument40 SeitenAdvances in Neural Information Processing SystemsAdi NouashcinciNoch keine Bewertungen
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (121)
- Anfis Adap Tive-Ne Twork-Based Fuzzy Inference SystemDokument21 SeitenAnfis Adap Tive-Ne Twork-Based Fuzzy Inference SystemshathyaNoch keine Bewertungen
- J Forecast Moody WuDokument36 SeitenJ Forecast Moody WuErezwaNoch keine Bewertungen
- Online Passive-Aggressive Algorithms On A BudgetDokument8 SeitenOnline Passive-Aggressive Algorithms On A BudgetP6E7P7Noch keine Bewertungen
- Ex Lecture1Dokument2 SeitenEx Lecture1AlNoch keine Bewertungen
- Lecture NotesDokument324 SeitenLecture NotesSeverus100% (1)
- Memahami Deep LearningDokument109 SeitenMemahami Deep Learninghendriganting100% (1)
- Building A Large Scale Machine Learning-Based Anomaly Detection SystemDokument60 SeitenBuilding A Large Scale Machine Learning-Based Anomaly Detection SystemAnonymous dQZRlcoLdhNoch keine Bewertungen
- SSRN Id937847Dokument18 SeitenSSRN Id937847Srinu BonuNoch keine Bewertungen
- Stochastic Optimization For Machine LearningDokument59 SeitenStochastic Optimization For Machine LearningjsprchinaNoch keine Bewertungen
- Introduction To Machine Learning and Hands On SessionsDokument50 SeitenIntroduction To Machine Learning and Hands On SessionsJohan Christhofer Armas ValenciaNoch keine Bewertungen
- Active Online Learning For Social Media Analysis To Support Crisis ManagementDokument14 SeitenActive Online Learning For Social Media Analysis To Support Crisis Managementrock starNoch keine Bewertungen
- 2 Machine Learning Introduction PDFDokument42 Seiten2 Machine Learning Introduction PDFranaNoch keine Bewertungen
- Kernel Adaptive Filtering PDFDokument124 SeitenKernel Adaptive Filtering PDFgeorgez111Noch keine Bewertungen
- Underwater Sonar Signals Recognition by Incremental Data Stream Mining With Conflit Analysis PDFDokument12 SeitenUnderwater Sonar Signals Recognition by Incremental Data Stream Mining With Conflit Analysis PDFfisegej698Noch keine Bewertungen
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Encryption & Decryption ApkDokument27 SeitenEncryption & Decryption ApkAjay YadavNoch keine Bewertungen
- SSRN Id3952925Dokument49 SeitenSSRN Id3952925Mindaugas ZickusNoch keine Bewertungen
- Lecture Notes For Machine Learning TheoryDokument167 SeitenLecture Notes For Machine Learning Theorychea rothaNoch keine Bewertungen
- Logistic RegressionDokument34 SeitenLogistic RegressionĐức Lại AnhNoch keine Bewertungen
- Towards A Real-Time Occupancy Detection Approach For Smart BuildingsDokument7 SeitenTowards A Real-Time Occupancy Detection Approach For Smart BuildingsEsma ÖzelNoch keine Bewertungen
- Mathematical Analysis of Machine Learning AlgsDokument477 SeitenMathematical Analysis of Machine Learning AlgsrichyeivNoch keine Bewertungen
- Machine Learning A Bayesian and Optimization Perspective 2Nd Edition Theodoridis S Download PDF ChapterDokument51 SeitenMachine Learning A Bayesian and Optimization Perspective 2Nd Edition Theodoridis S Download PDF Chapterfelicia.grove475100% (18)
- ML DataDokument6 SeitenML DataAptech PitampuraNoch keine Bewertungen
- Online Hashing: Long-Kai Huang, Qiang Yang, and Wei-Shi ZhengDokument14 SeitenOnline Hashing: Long-Kai Huang, Qiang Yang, and Wei-Shi ZhengooooNoch keine Bewertungen
- 2021 Book PatternRecognitionICPRInternatDokument696 Seiten2021 Book PatternRecognitionICPRInternatYuvaraj DhandapaniNoch keine Bewertungen
- ANN - WikiDokument39 SeitenANN - Wikirudy_tanagaNoch keine Bewertungen