Das könnte Ihnen auch gefallen
- ME2142E Feedback Control Systems-CheatsheetDokument2 SeitenME2142E Feedback Control Systems-CheatsheetPhyo Wai Aung67% (9)
- Solution PDFDokument20 SeitenSolution PDFVard FarrellNoch keine Bewertungen
- What Is A Political SubjectDokument7 SeitenWhat Is A Political SubjectlukaNoch keine Bewertungen
- Linear Algebra For Machine LearningDokument65 SeitenLinear Algebra For Machine Learning黃振嘉Noch keine Bewertungen
- CIS 4526: Foundations of Machine Learning Linear Regression (modified from Sanja FidlerDokument20 SeitenCIS 4526: Foundations of Machine Learning Linear Regression (modified from Sanja FidlerMary LiuNoch keine Bewertungen
- Deep Learning Nonlinear ControlDokument68 SeitenDeep Learning Nonlinear ControlDaotao DaihocNoch keine Bewertungen
- Large Scale Deep LearningDokument170 SeitenLarge Scale Deep Learningpavancreative81Noch keine Bewertungen
- Chap 1 PDFDokument101 SeitenChap 1 PDFkaren dejoNoch keine Bewertungen
- School of Engineering and Computer Science Department of Electrical & Electronic EngineeringDokument8 SeitenSchool of Engineering and Computer Science Department of Electrical & Electronic EngineeringMD. Akif RahmanNoch keine Bewertungen
- Lab 4Dokument4 SeitenLab 4Mian BlalNoch keine Bewertungen
- 5a Patterns and ExpressionsDokument38 Seiten5a Patterns and ExpressionsFlors BorneaNoch keine Bewertungen
- Chapter 4Dokument10 SeitenChapter 4Emanuel DiegoNoch keine Bewertungen
- MATH 1 No. 4Dokument3 SeitenMATH 1 No. 4Reina GodioNoch keine Bewertungen
- 1.02.mathematical BackgroundDokument50 Seiten1.02.mathematical BackgroundMohamed AliNoch keine Bewertungen
- Linear Algebra Hoffman Homework SolutionsDokument6 SeitenLinear Algebra Hoffman Homework Solutionsaxhwefzod100% (1)
- School of Engineering and Computer Science Department of Electrical & Electronic EngineeringDokument18 SeitenSchool of Engineering and Computer Science Department of Electrical & Electronic EngineeringMD. Akif RahmanNoch keine Bewertungen
- Algematics DemoDokument18 SeitenAlgematics DemoMohanNoch keine Bewertungen
- Statistics Chapter3Dokument60 SeitenStatistics Chapter3Zhiye Tang100% (1)
- Learning 2Dokument104 SeitenLearning 2Noel Roy DenjaNoch keine Bewertungen
- Math Concepts Reference Guide PDFDokument7 SeitenMath Concepts Reference Guide PDFAUSTRANoch keine Bewertungen
- Structural Equation Modeling: MGMT 291 Sep 28, 2009Dokument38 SeitenStructural Equation Modeling: MGMT 291 Sep 28, 2009sahojjatNoch keine Bewertungen
- School of Engineering and Computer Science Department of Electrical & Electronic EngineeringDokument9 SeitenSchool of Engineering and Computer Science Department of Electrical & Electronic EngineeringMD. Akif RahmanNoch keine Bewertungen
- Diff 01 4Dokument7 SeitenDiff 01 4ashraf shalghoumNoch keine Bewertungen
- Slides AnalisisI 2021Dokument75 SeitenSlides AnalisisI 2021FelipeNoch keine Bewertungen
- 28 - AI-Regression vs. ClassificationDokument35 Seiten28 - AI-Regression vs. ClassificationMuhammad FaisalNoch keine Bewertungen
- Superior Mathematics From An Elementary Point of ViewDokument196 SeitenSuperior Mathematics From An Elementary Point of ViewJoão MotaNoch keine Bewertungen
- Fakulti Kejuruteraan Mekanikal Dan Pembuatan: Ts. Dr. Mohd Fadhli Bin ZulkafliDokument15 SeitenFakulti Kejuruteraan Mekanikal Dan Pembuatan: Ts. Dr. Mohd Fadhli Bin ZulkafliThiuyah A/p RajandranNoch keine Bewertungen
- ISC MathematicsDokument20 SeitenISC MathematicsprinceNoch keine Bewertungen
- Scheme of Work: Hrs Units Notes Examples ReferencesDokument17 SeitenScheme of Work: Hrs Units Notes Examples ReferencesOluseye AkinNoch keine Bewertungen
- Linear Regression: Machine Learning Course - CS-433Dokument5 SeitenLinear Regression: Machine Learning Course - CS-433Diego Iriarte SainzNoch keine Bewertungen
- NLP-NeuralNetworks Reading NotesDokument13 SeitenNLP-NeuralNetworks Reading NotesDavidNoch keine Bewertungen
- Wanna Be A Millionaire? Then Pay Attention To This Presentation and You Might Just Learn How!Dokument8 SeitenWanna Be A Millionaire? Then Pay Attention To This Presentation and You Might Just Learn How!Javeria AmjadNoch keine Bewertungen
- Machine Learning in Action: Linear RegressionDokument47 SeitenMachine Learning in Action: Linear RegressionRaushan Kashyap100% (1)
- A Proof of Local Convergence For The Adam OptimizerDokument8 SeitenA Proof of Local Convergence For The Adam OptimizerPuja Dwi LestariNoch keine Bewertungen
- EC205 Mathematics For Economics and Business: The Straight Line and Applications IDokument5 SeitenEC205 Mathematics For Economics and Business: The Straight Line and Applications IpereNoch keine Bewertungen
- DSD: D - S - D T D N N: Ense Parse Ense Raining For EEP Eural EtworksDokument13 SeitenDSD: D - S - D T D N N: Ense Parse Ense Raining For EEP Eural EtworksHesham HefnyNoch keine Bewertungen
- 1.1 RSG Ans PDFDokument3 Seiten1.1 RSG Ans PDFSamara LigginsNoch keine Bewertungen
- 2022 Gr10 Maths WRKBK ENGDokument18 Seiten2022 Gr10 Maths WRKBK ENGKarabo MahloNoch keine Bewertungen
- Algorithms For Division Free Perspective Correct RenderingDokument7 SeitenAlgorithms For Division Free Perspective Correct Renderingn1234567890987654321Noch keine Bewertungen
- Unit 3 Polynomial PacketDokument28 SeitenUnit 3 Polynomial PacketHaileyNoch keine Bewertungen
- Summary of New Features in 12.0Dokument19 SeitenSummary of New Features in 12.0Dennis La CoteraNoch keine Bewertungen
- approximate-solution-to-firstorder-integrodifferential-equations-using-polynomial-collocation-approach_2Dokument4 Seitenapproximate-solution-to-firstorder-integrodifferential-equations-using-polynomial-collocation-approach_2rrrNoch keine Bewertungen
- Homework 1Dokument7 SeitenHomework 1Muhammad MurtazaNoch keine Bewertungen
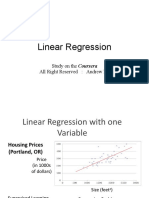
- Linear Regression: Study On The Coursera All Right Reserved: Andrew NGDokument29 SeitenLinear Regression: Study On The Coursera All Right Reserved: Andrew NGRabbia KhalidNoch keine Bewertungen
- Matlab Graph & PlottingDokument21 SeitenMatlab Graph & PlottingkarlapuditharunNoch keine Bewertungen
- Lecture 04 - Supervised Learning by Computing Distances (2) - PlainDokument16 SeitenLecture 04 - Supervised Learning by Computing Distances (2) - PlainRajaNoch keine Bewertungen
- The Functions of Deep Learning: Gilbert StrangDokument1 SeiteThe Functions of Deep Learning: Gilbert StrangGurpinder SinghNoch keine Bewertungen
- DLL - Mathematics 6 - Q2 - W10Dokument7 SeitenDLL - Mathematics 6 - Q2 - W10Shaun BarsolascoNoch keine Bewertungen
- Lecture NotesDokument86 SeitenLecture NotesShweta ChavanNoch keine Bewertungen
- Optional Math Teachers' Guide 9Dokument209 SeitenOptional Math Teachers' Guide 9insectsparkNoch keine Bewertungen
- LINEAR MODEL - KEY CONCEPTS OF LINEAR REGRESSIONDokument33 SeitenLINEAR MODEL - KEY CONCEPTS OF LINEAR REGRESSIONSwastik SindhaniNoch keine Bewertungen
- 5.1 Number and OperationsDokument4 Seiten5.1 Number and Operationsguanajuato_christopherNoch keine Bewertungen
- Apprentice Teaching: Lesson Plan Summary TemplateDokument7 SeitenApprentice Teaching: Lesson Plan Summary Templateapi-538475699Noch keine Bewertungen
- Math NoteDokument10 SeitenMath NoteTrong Nguyen DucNoch keine Bewertungen
- National Harmonised Correction of The Paper Introduction To Statistics Applied To EducationDokument4 SeitenNational Harmonised Correction of The Paper Introduction To Statistics Applied To EducationNganku JuniorNoch keine Bewertungen
- Relations and FunctionDokument28 SeitenRelations and Functionsheikh66752Noch keine Bewertungen
- MAT114 Multivariable Calculus and Differential Equations ETH 1.01 AC34Dokument2 SeitenMAT114 Multivariable Calculus and Differential Equations ETH 1.01 AC34Karan DesaiNoch keine Bewertungen
- Adzema 3Dokument3 SeitenAdzema 3api-563599311Noch keine Bewertungen
- Technical Aptitude Questions EbookDokument175 SeitenTechnical Aptitude Questions EbookJothi BossNoch keine Bewertungen
- Gemp Et Al. - 2020 - EigenGame PCA As A Nash EquilibriumDokument11 SeitenGemp Et Al. - 2020 - EigenGame PCA As A Nash EquilibriumclearlyInvisibleNoch keine Bewertungen
- Let's Practise: Maths Workbook Coursebook 8Von EverandLet's Practise: Maths Workbook Coursebook 8Noch keine Bewertungen
- Let's Practise: Maths Workbook Coursebook 7Von EverandLet's Practise: Maths Workbook Coursebook 7Noch keine Bewertungen
- Lecture2 Camera Models NotesDokument57 SeitenLecture2 Camera Models NoteshsujustinNoch keine Bewertungen
- Lecture1 IntroductionDokument83 SeitenLecture1 IntroductionhsujustinNoch keine Bewertungen
- 19 Homework 6.3Dokument2 Seiten19 Homework 6.3hsujustinNoch keine Bewertungen
- Lecture1 IntroductionDokument83 SeitenLecture1 IntroductionhsujustinNoch keine Bewertungen
- Hmwk#6Dokument1 SeiteHmwk#6hsujustinNoch keine Bewertungen
- ProbabilityDokument41 SeitenProbabilitySaleha ShakoorNoch keine Bewertungen
- X4 Review AnswersDokument6 SeitenX4 Review AnswershsujustinNoch keine Bewertungen
- PlainDokument1 SeitePlainhsujustinNoch keine Bewertungen
- Ps 0Dokument2 SeitenPs 0hsujustinNoch keine Bewertungen
- Data Structures Trees BSTDokument94 SeitenData Structures Trees BSThsujustinNoch keine Bewertungen
- Greensheet 19Dokument2 SeitenGreensheet 19hsujustinNoch keine Bewertungen
- CS10 Ch6 LectureDokument23 SeitenCS10 Ch6 LecturehsujustinNoch keine Bewertungen
- Assignment 0: R Bootcamp: Turn in DeadlineDokument2 SeitenAssignment 0: R Bootcamp: Turn in DeadlinehsujustinNoch keine Bewertungen
- ChatterbotDokument5 SeitenChatterbothsujustinNoch keine Bewertungen
- Lab4 MSA Forms ReportsDokument10 SeitenLab4 MSA Forms ReportshsujustinNoch keine Bewertungen
- Ken Goldberg's MS Access Lab Notes on RelationshipsDokument11 SeitenKen Goldberg's MS Access Lab Notes on RelationshipshsujustinNoch keine Bewertungen
- Assignment 0: R Bootcamp: Turn in DeadlineDokument2 SeitenAssignment 0: R Bootcamp: Turn in DeadlinehsujustinNoch keine Bewertungen
- Economics of SpeedDokument54 SeitenEconomics of SpeedhsujustinNoch keine Bewertungen
- Cycle TimeDokument14 SeitenCycle TimehsujustinNoch keine Bewertungen
- Course OutlineDokument2 SeitenCourse OutlinehsujustinNoch keine Bewertungen
- Cycle TimeDokument14 SeitenCycle TimehsujustinNoch keine Bewertungen
- Nikbakht H. EFL Pronunciation Teaching - A Theoretical Review.Dokument30 SeitenNikbakht H. EFL Pronunciation Teaching - A Theoretical Review.researchdomain100% (1)
- Experienced Design Engineer Seeks Challenging PositionDokument2 SeitenExperienced Design Engineer Seeks Challenging PositionjmashkNoch keine Bewertungen
- Galletto 1250 User GuideDokument9 SeitenGalletto 1250 User Guidesimcsimc1Noch keine Bewertungen
- Professional Training Academy: Professional Level IV - Preparation & Final TestDokument2 SeitenProfessional Training Academy: Professional Level IV - Preparation & Final TestJayant SinhaNoch keine Bewertungen
- Scheduling BODS Jobs Sequentially and ConditionDokument10 SeitenScheduling BODS Jobs Sequentially and ConditionwicvalNoch keine Bewertungen
- (Genus - Gender in Modern Culture 12.) Segal, Naomi - Anzieu, Didier - Consensuality - Didier Anzieu, Gender and The Sense of Touch-Rodopi (2009)Dokument301 Seiten(Genus - Gender in Modern Culture 12.) Segal, Naomi - Anzieu, Didier - Consensuality - Didier Anzieu, Gender and The Sense of Touch-Rodopi (2009)Anonymous r3ZlrnnHcNoch keine Bewertungen
- LLRP PROTOCOLDokument19 SeitenLLRP PROTOCOLRafo ValverdeNoch keine Bewertungen
- Guia de Manejo Sdra 2019Dokument27 SeitenGuia de Manejo Sdra 2019Jorge VidalNoch keine Bewertungen
- Critical Review By:: Shema Sheravie Ivory F. QuebecDokument3 SeitenCritical Review By:: Shema Sheravie Ivory F. QuebecShema Sheravie IvoryNoch keine Bewertungen
- Bus210 Week5 Reading1Dokument33 SeitenBus210 Week5 Reading1eadyden330% (1)
- Question Notes On Production Management (Final)Dokument63 SeitenQuestion Notes On Production Management (Final)Vineet Walia100% (1)
- The Four Humor Mechanisms 42710Dokument4 SeitenThe Four Humor Mechanisms 42710Viorel100% (1)
- NPTEL Managerial Economics Video CourseDokument3 SeitenNPTEL Managerial Economics Video CourseAmanda AdamsNoch keine Bewertungen
- 373 07 2Dokument143 Seiten373 07 2fpttmmNoch keine Bewertungen
- Synthesis and Characterization of Nanoparticles of Iron OxideDokument8 SeitenSynthesis and Characterization of Nanoparticles of Iron OxideDipteemaya BiswalNoch keine Bewertungen
- FeminismDokument8 SeitenFeminismismailjuttNoch keine Bewertungen
- English Language and Applied Linguistics Textbooks Lo Res USDDokument61 SeitenEnglish Language and Applied Linguistics Textbooks Lo Res USDJames Blackburn Quéré Cutbirth100% (2)
- Constructed Wetland Design Guidelines for DevelopersDokument32 SeitenConstructed Wetland Design Guidelines for DevelopersBere QuintosNoch keine Bewertungen
- Differential Aptitude TestsDokument2 SeitenDifferential Aptitude Testsiqrarifat50% (4)
- Construction Vibrations and Their Impact On Vibration-Sensitive FacilitiesDokument10 SeitenConstruction Vibrations and Their Impact On Vibration-Sensitive FacilitiesKwan Hau LeeNoch keine Bewertungen
- RoboServer Users Guide PDFDokument25 SeitenRoboServer Users Guide PDFdavid0young_2Noch keine Bewertungen
- HTTP API - SMS Help GuideDokument8 SeitenHTTP API - SMS Help Guideaksh11inNoch keine Bewertungen
- Chapter 1&2 Exercise Ce StatisticDokument19 SeitenChapter 1&2 Exercise Ce StatisticSky FireNoch keine Bewertungen
- Bilingual Language Development TypesDokument29 SeitenBilingual Language Development Typesirish delacruzNoch keine Bewertungen
- Colortrac Cx40 Utilities Service Manual PDFDokument21 SeitenColortrac Cx40 Utilities Service Manual PDFTintila StefanNoch keine Bewertungen
- Ch10 Mendelian GeneticsDokument42 SeitenCh10 Mendelian GeneticseubacteriaNoch keine Bewertungen
- Textual Equivalence-CohesionDokument39 SeitenTextual Equivalence-CohesionTaufikNoch keine Bewertungen
- Question 1: Bezier Quadratic Curve Successive Linear Interpolation EquationDokument4 SeitenQuestion 1: Bezier Quadratic Curve Successive Linear Interpolation Equationaushad3mNoch keine Bewertungen