Das könnte Ihnen auch gefallen
- Tabla Pni Determinación Del Precio de Bienes y ServiciosDokument7 SeitenTabla Pni Determinación Del Precio de Bienes y ServiciosTania CommerceNoch keine Bewertungen
- Definicion de Archivos SecuencialesDokument8 SeitenDefinicion de Archivos SecuencialesLuis Gerardo Picén OrellanaNoch keine Bewertungen
- Principios de Energía y Momentum PDFDokument21 SeitenPrincipios de Energía y Momentum PDFCésarA.LópezNoch keine Bewertungen
- Laboratorio 02 Funciones LogicasDokument49 SeitenLaboratorio 02 Funciones LogicasLuis Enrique Pari Alvarado0% (1)
- Comandos Utilizados en Visual BasicDokument4 SeitenComandos Utilizados en Visual BasicGeovanny Quiroz Moncerrad33% (3)
- Fichas de InvestigaciónDokument20 SeitenFichas de InvestigaciónFrida Yamile Sagastume CanalesNoch keine Bewertungen
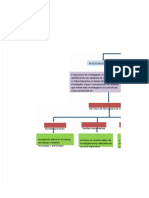
- ETICADokument3 SeitenETICAEduardo CedeñoNoch keine Bewertungen
- Ficha de TrabajoDokument7 SeitenFicha de TrabajoEdna Michel MoyaNoch keine Bewertungen
- Técnicas de FichajeDokument10 SeitenTécnicas de FichajeRuiz antonio Molina quiñonesNoch keine Bewertungen
- Modos de ProduccionDokument9 SeitenModos de ProduccionLeón ColochNoch keine Bewertungen
- División Del MercadoDokument8 SeitenDivisión Del MercadoJorge Luis Ortiz FigueroaNoch keine Bewertungen
- Técnicas Bibliográficas y Documentales de La Investigación CientíficaDokument7 SeitenTécnicas Bibliográficas y Documentales de La Investigación CientíficaAstrid lemus Diaz100% (1)
- Manifestaciones de La Cultura OrganizacionalDokument3 SeitenManifestaciones de La Cultura OrganizacionalAlberto OvallesNoch keine Bewertungen
- Cuál Es El Propósito de La FilosofíaDokument3 SeitenCuál Es El Propósito de La FilosofíaJoseNoch keine Bewertungen
- Importancia Del Profesional de Los ArchivosDokument6 SeitenImportancia Del Profesional de Los Archivosroberto sornozaNoch keine Bewertungen
- Positivismo, Dialéctica Materialista y Fenomenología - Tres Enfoques Filosóficos Del Método Científic PDFDokument22 SeitenPositivismo, Dialéctica Materialista y Fenomenología - Tres Enfoques Filosóficos Del Método Científic PDFGaston SalinasNoch keine Bewertungen
- La Entrevista en El Proceso de Obtención de Información en El Ánalisis de PuestoDokument15 SeitenLa Entrevista en El Proceso de Obtención de Información en El Ánalisis de PuestoJoaquín OrgásNoch keine Bewertungen
- Investigacion en Mexico y Su Evolucion SocialDokument2 SeitenInvestigacion en Mexico y Su Evolucion SocialCelina Hernández XolioNoch keine Bewertungen
- El Ambiente Economico InternacionalDokument15 SeitenEl Ambiente Economico Internacionalald23Noch keine Bewertungen
- Ensayo Crìtico de Enfoque Cuantitativo y CualitativoDokument7 SeitenEnsayo Crìtico de Enfoque Cuantitativo y Cualitativoneidamolina67% (3)
- Funciones de Los InventariosDokument3 SeitenFunciones de Los InventariosKevin CornejoNoch keine Bewertungen
- Unidad IiiDokument15 SeitenUnidad IiiRosa GómezNoch keine Bewertungen
- Autores Mexicanos Más Representativos de La AdministraciónDokument18 SeitenAutores Mexicanos Más Representativos de La AdministraciónYess Estephanie0% (2)
- Resumen Proceso de La InvestigaciónDokument2 SeitenResumen Proceso de La InvestigaciónRik MaidenNoch keine Bewertungen
- Principales Fundamentos Teóricos de La ArchivisticaDokument3 SeitenPrincipales Fundamentos Teóricos de La ArchivisticaCarlos Andres Tordecilla DiazNoch keine Bewertungen
- Martinez Alfredo ReporteDokument2 SeitenMartinez Alfredo ReporteAlfredo CobosNoch keine Bewertungen
- El Cambio Incesante - 104049Dokument1 SeiteEl Cambio Incesante - 104049Veronica vanessa Chocoj lopezNoch keine Bewertungen
- Definición de Fuente atDokument10 SeitenDefinición de Fuente atJuan Sebastian Solis Castro100% (2)
- Metodo Hermenéutico - DialécticoDokument5 SeitenMetodo Hermenéutico - DialécticojguadamuzgNoch keine Bewertungen
- Siete Pilares SconulDokument14 SeitenSiete Pilares SconulNaty CastroNoch keine Bewertungen
- Aguirre, Silvia - Ensayo - Métodos Estadísticos en Los NegociosDokument11 SeitenAguirre, Silvia - Ensayo - Métodos Estadísticos en Los NegociosSilvia AguirreNoch keine Bewertungen
- Fuentes de InvestigacionDokument4 SeitenFuentes de InvestigacionEduard David PulidoNoch keine Bewertungen
- Historia y Desarrollo de La Recuperación de La InformaciónDokument1 SeiteHistoria y Desarrollo de La Recuperación de La InformaciónErick CarreñoNoch keine Bewertungen
- Método Deductivo DirectoDokument3 SeitenMétodo Deductivo DirectoErick CuyuchNoch keine Bewertungen
- La Ciencia, Origen de La Ciencia y Origen Del Pensamiento CientíficoDokument20 SeitenLa Ciencia, Origen de La Ciencia y Origen Del Pensamiento CientíficoCecilioAraujoNoch keine Bewertungen
- Que Es La Ética de ImmanuelDokument4 SeitenQue Es La Ética de ImmanuelLeslie mirella Trujillo RojasNoch keine Bewertungen
- Historia de La Universidad de San Carlos de GuatemalaDokument12 SeitenHistoria de La Universidad de San Carlos de GuatemalaInternet El CentroNoch keine Bewertungen
- (PDF) Mapa Conceptual Tipos de InvestigacionDokument4 Seiten(PDF) Mapa Conceptual Tipos de InvestigacionEdwin Mamani CachuraNoch keine Bewertungen
- Linea Del TiempoDokument4 SeitenLinea Del Tiempoboy in blackNoch keine Bewertungen
- El Método InductivoDokument11 SeitenEl Método InductivoCarelia Arce CastroNoch keine Bewertungen
- A1. Mapa TelarañaDokument1 SeiteA1. Mapa TelarañaValeria CanoNoch keine Bewertungen
- TecnoéticaDokument4 SeitenTecnoéticaLuis Fidel IbañezNoch keine Bewertungen
- La Importancia Del Espiral PublicitarioDokument6 SeitenLa Importancia Del Espiral PublicitarioPablo RiosNoch keine Bewertungen
- Sopa de Letras. Medidas Preventivas Del Corona VirusDokument2 SeitenSopa de Letras. Medidas Preventivas Del Corona VirusJose Ortiz RodriguezNoch keine Bewertungen
- ADMINISTRACION e InformaticaDokument13 SeitenADMINISTRACION e InformaticaSiegfried ReynosoNoch keine Bewertungen
- Sistemas Archivísticos y Modelos de Gestión de Documentos en El Ámbito InternacionalDokument36 SeitenSistemas Archivísticos y Modelos de Gestión de Documentos en El Ámbito Internacionaljose alejandro gomez garciaNoch keine Bewertungen
- Reporte de Lectura La Etica en La CienciaDokument5 SeitenReporte de Lectura La Etica en La CienciaThiago OrtizNoch keine Bewertungen
- Definicion de Método CuantitativoDokument5 SeitenDefinicion de Método CuantitativoAlexandra FernandezNoch keine Bewertungen
- Comentario PersonalDokument2 SeitenComentario PersonalWilder GomezNoch keine Bewertungen
- Estructura Del Marco Jurídico en MéxicoDokument9 SeitenEstructura Del Marco Jurídico en MéxicoAlex DarkNoch keine Bewertungen
- Diagnostico AdministrativoDokument10 SeitenDiagnostico AdministrativoHillary DíazNoch keine Bewertungen
- Ensayo Método CientíficoDokument2 SeitenEnsayo Método CientíficoceciliaNoch keine Bewertungen
- Relacion Entre La Economia y La HistoriaDokument4 SeitenRelacion Entre La Economia y La HistoriaEmerson Huaman Castro100% (1)
- Antecedentes Historicos de La Sociologia y Linea Del Tiempo - Miguel Angel Hernandez LugoDokument11 SeitenAntecedentes Historicos de La Sociologia y Linea Del Tiempo - Miguel Angel Hernandez LugoAngel LugoNoch keine Bewertungen
- Qué Etapas Comprende El Desarrollo de La Perspectiva TeóricaDokument2 SeitenQué Etapas Comprende El Desarrollo de La Perspectiva TeóricamafeNoch keine Bewertungen
- Investigacion Documental y de CampoDokument27 SeitenInvestigacion Documental y de CampoNuria Arlete Hernández MartínezNoch keine Bewertungen
- Caracteristicas EsencialesDokument2 SeitenCaracteristicas EsencialesIrene RodriguezNoch keine Bewertungen
- Comercio Formal e InformalDokument3 SeitenComercio Formal e InformalElvis Dueñas67% (3)
- Administración de PLANTASDokument3 SeitenAdministración de PLANTASYamilet PerezNoch keine Bewertungen
- Escuela de ContingenciaDokument13 SeitenEscuela de ContingenciaNadae Chalco MacotelaNoch keine Bewertungen
- Actividad 2 7moDokument7 SeitenActividad 2 7moSteffani MarquezNoch keine Bewertungen
- Archivos (Estructura de Datos)Dokument4 SeitenArchivos (Estructura de Datos)Franco AngelNoch keine Bewertungen
- Archivo Secuencial IndexadoDokument15 SeitenArchivo Secuencial IndexadoGuillermo José Martínez CarmonaNoch keine Bewertungen
- Movistar CarDokument2 SeitenMovistar CarJosé Luis López GarcíaNoch keine Bewertungen
- Java - Servicios Web y SOADokument3 SeitenJava - Servicios Web y SOAJosé Luis López GarcíaNoch keine Bewertungen
- Upc Megane II PDFDokument22 SeitenUpc Megane II PDFJosé Luis López GarcíaNoch keine Bewertungen
- Herramientas CASE. Temario de Las Oposiciones de Informática y Telecomunicaciones PDFDokument11 SeitenHerramientas CASE. Temario de Las Oposiciones de Informática y Telecomunicaciones PDFJosé Luis López GarcíaNoch keine Bewertungen
- Herramientas CASE. Temario de Las Oposiciones de Informática y TelecomunicacionesDokument11 SeitenHerramientas CASE. Temario de Las Oposiciones de Informática y TelecomunicacionesJosé Luis López GarcíaNoch keine Bewertungen
- Fracciones Impropias y MixtasDokument9 SeitenFracciones Impropias y MixtasHans Romero OrellanaNoch keine Bewertungen
- Estabilidad - Chapa y Cuerpo Rígidos VinculadosDokument36 SeitenEstabilidad - Chapa y Cuerpo Rígidos VinculadosMaru CattaneoNoch keine Bewertungen
- Cálculo y Memoria Técnica Fuerza-ElectricidadDokument5 SeitenCálculo y Memoria Técnica Fuerza-ElectricidadMaría Del Rosario VásquezNoch keine Bewertungen
- MentoplastiaDokument13 SeitenMentoplastiaIsmael Erazo AstudilloNoch keine Bewertungen
- Transductores y AplicacionesDokument42 SeitenTransductores y AplicacionestonaNoch keine Bewertungen
- S3 - Est2 - PROBABILIDAD Y ESTADÍSTICA IIDokument6 SeitenS3 - Est2 - PROBABILIDAD Y ESTADÍSTICA IIMarisol Torres OlánNoch keine Bewertungen
- 2015 Villarrica Xix PucDokument683 Seiten2015 Villarrica Xix PucMatías ValenzuelaNoch keine Bewertungen
- ZigbeeDokument30 SeitenZigbeeTino RuizNoch keine Bewertungen
- Educación Secundaria Con Mención en Matemática y FísicaDokument6 SeitenEducación Secundaria Con Mención en Matemática y FísicaDaniel SandovalNoch keine Bewertungen
- Gps 28500 Tramas EmeaDokument16 SeitenGps 28500 Tramas EmeaJFREY1504Noch keine Bewertungen
- Diseno Hidraulico de Un Sifon InvertidoDokument12 SeitenDiseno Hidraulico de Un Sifon InvertidoJhonatan Burgos100% (1)
- Homologacion ASSET DOC LOC 6836823Dokument105 SeitenHomologacion ASSET DOC LOC 6836823Ricardo Matías Fernández TapiaNoch keine Bewertungen
- Espec. Tecnicas df8Dokument4 SeitenEspec. Tecnicas df8carlaNoch keine Bewertungen
- Ensayo DialecticaDokument3 SeitenEnsayo DialecticaAbry2323100% (1)
- Tarea - Semana - 3-Algebra SuperiorDokument8 SeitenTarea - Semana - 3-Algebra SuperiorBraian Nicolas Camargo GómezNoch keine Bewertungen
- ID Del Documento 2206059Dokument5 SeitenID Del Documento 2206059Harold EncantoNoch keine Bewertungen
- Cuestionario ResueltoDokument54 SeitenCuestionario ResueltoAnto TapiaNoch keine Bewertungen
- Diseño y Construccion de Generadores SincronosDokument3 SeitenDiseño y Construccion de Generadores SincronosPayazita PrincezzNoch keine Bewertungen
- Case Loader 721d Repair Manual SpanishDokument20 SeitenCase Loader 721d Repair Manual Spanishmaude100% (29)
- ABP - Caso Individual, Corona de VolanteDokument11 SeitenABP - Caso Individual, Corona de Volanteoscar intriagoNoch keine Bewertungen
- Trabajo y Energia IVDokument6 SeitenTrabajo y Energia IVrebeca nievesNoch keine Bewertungen
- CL2 ResistenciaDokument4 SeitenCL2 Resistenciadiego20064134Noch keine Bewertungen
- Dimensionamiento de Barras ElectricasDokument9 SeitenDimensionamiento de Barras ElectricasJose Guadalupe ZavalaNoch keine Bewertungen
- Economia Semana 06 - Grupo #06Dokument10 SeitenEconomia Semana 06 - Grupo #06Rodriguez Sánchez LeonorNoch keine Bewertungen
- Semana 02 - GeografíaDokument2 SeitenSemana 02 - Geografíasantiago rafaelNoch keine Bewertungen
- Metodología de Investigación en CcssDokument49 SeitenMetodología de Investigación en CcssAlejandraNoch keine Bewertungen
- Copia de LitioDokument1 SeiteCopia de Litiohenry nova quirogaNoch keine Bewertungen