Das könnte Ihnen auch gefallen
- Darien - Conn IgguldenDokument260 SeitenDarien - Conn IgguldenNerea Violet Rose100% (1)
- NTP 339.181 Esclerometria (2013)Dokument14 SeitenNTP 339.181 Esclerometria (2013)Demetrio Carranza Peña100% (6)
- Secretos Del Perfecto Actor de TeatroDokument46 SeitenSecretos Del Perfecto Actor de TeatroJosue Manuel Rodriguez del ValleNoch keine Bewertungen
- Metodo de Los Minimos CuadradosDokument10 SeitenMetodo de Los Minimos CuadradosVannessa VicŤorio CasŤilloNoch keine Bewertungen
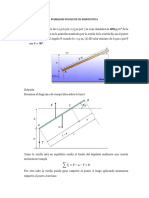
- Ejercicios de fuerzas en elementos de armadurasDokument4 SeitenEjercicios de fuerzas en elementos de armadurasPatricia Lizbeth Abanto LinaresNoch keine Bewertungen
- Practica 3Dokument8 SeitenPractica 3leny perezNoch keine Bewertungen
- Fundamentos de econometría intermedia: Teoría y aplicacionesVon EverandFundamentos de econometría intermedia: Teoría y aplicacionesNoch keine Bewertungen
- Proyectos Con Pic y Simulacion en ProteusDokument27 SeitenProyectos Con Pic y Simulacion en ProteusNaomiTk0% (1)
- Coeficientes de Rugosidad en Canales AbiertosDokument20 SeitenCoeficientes de Rugosidad en Canales AbiertosAnderson Esmid Gonzalez Pacheco100% (1)
- Presupuesto Con Iva y LetraDokument9 SeitenPresupuesto Con Iva y LetraAntonio CarbajalNoch keine Bewertungen
- Ensayo Notacion IndicialDokument8 SeitenEnsayo Notacion IndicialJareth ReyesNoch keine Bewertungen
- ¿Quién Es El CENAMDokument2 Seiten¿Quién Es El CENAMIsaac VillamaresNoch keine Bewertungen
- Método de Extensión Grafic1Dokument4 SeitenMétodo de Extensión Grafic1Tania ChoqueNoch keine Bewertungen
- Desarrollo Sustentable Unidad 4 PACHECO KANTUN ULISES ING CIVIL 3BDokument57 SeitenDesarrollo Sustentable Unidad 4 PACHECO KANTUN ULISES ING CIVIL 3Bulises pachecoNoch keine Bewertungen
- Compactadoras: tipos y usos en construcciónDokument10 SeitenCompactadoras: tipos y usos en construcciónCarlos Abreu VivasNoch keine Bewertungen
- Pruebas de Laboratorio Que Se Realizan A Los Agregados PetreosDokument19 SeitenPruebas de Laboratorio Que Se Realizan A Los Agregados PetreosRiioga Hiidekii100% (1)
- Extracción de asfalto por centrifugaciónDokument9 SeitenExtracción de asfalto por centrifugaciónDaniel Camilo Fernandez AcevedoNoch keine Bewertungen
- Obras de captación de agua superficial y subterráneaDokument42 SeitenObras de captación de agua superficial y subterráneaJeancarlo LanzaNoch keine Bewertungen
- 2017 2 DIN Taller4 ConservacionDokument2 Seiten2017 2 DIN Taller4 Conservacionaker_wildchildNoch keine Bewertungen
- Investigación de Tipos de Parametrización (Concepto, Definiciones) PDFDokument11 SeitenInvestigación de Tipos de Parametrización (Concepto, Definiciones) PDFpedro garciaNoch keine Bewertungen
- Monografia PUENTE BROOKLYNDokument23 SeitenMonografia PUENTE BROOKLYNEdwin Bejarano AbreguNoch keine Bewertungen
- Método Directo de IntegraciónDokument9 SeitenMétodo Directo de IntegracióncayatopaNoch keine Bewertungen
- Practica 4 Prueba BrasileñaDokument3 SeitenPractica 4 Prueba BrasileñaIbsán Yoval SeguraNoch keine Bewertungen
- 7 Tema6 AnálisisdeEstructurasEstáticamenteDeterminadas Estática TNMDokument36 Seiten7 Tema6 AnálisisdeEstructurasEstáticamenteDeterminadas Estática TNMMercury xNoch keine Bewertungen
- Cargas NodalesDokument9 SeitenCargas NodalesbelyNoch keine Bewertungen
- Instituto Tecnológico Superior de La MontañaDokument14 SeitenInstituto Tecnológico Superior de La MontañaAnyta RamirezNoch keine Bewertungen
- Maestria en Ingenieria Civil Distribucion de FrecuenciasDokument39 SeitenMaestria en Ingenieria Civil Distribucion de FrecuenciasRocío LauraNoch keine Bewertungen
- Ingeniería Romana - AcueductosDokument2 SeitenIngeniería Romana - AcueductosMarlonRincónNoch keine Bewertungen
- Diseño Hidráulico Cárdenas PanamáDokument16 SeitenDiseño Hidráulico Cárdenas PanamáfranNoch keine Bewertungen
- Tema 1.2 Elementos Que Conforman Una Edificacion de Concreto ArmadoDokument55 SeitenTema 1.2 Elementos Que Conforman Una Edificacion de Concreto Armadodulcemarielcarrasco7100% (1)
- Historia UthhDokument2 SeitenHistoria UthhFernando Bautista100% (2)
- Ecuación Diferencial de Una Barra Sujeta A FlexiónDokument10 SeitenEcuación Diferencial de Una Barra Sujeta A FlexiónCristian Canseco de los santosNoch keine Bewertungen
- Análisis de Estructuras Indeterminadas Por El Método de Las FlexibilidadesDokument6 SeitenAnálisis de Estructuras Indeterminadas Por El Método de Las FlexibilidadesjoseNoch keine Bewertungen
- Distribuciones de probabilidad y ejercicios resueltosDokument5 SeitenDistribuciones de probabilidad y ejercicios resueltosdania yarizuelNoch keine Bewertungen
- Interpolación por Splines de 2° GradoDokument4 SeitenInterpolación por Splines de 2° GradoValentín VeintemillaNoch keine Bewertungen
- Sistemas Vibratorios Vibracion Libre No AmortiguadaDokument23 SeitenSistemas Vibratorios Vibracion Libre No AmortiguadaZulema Doria DelgadoNoch keine Bewertungen
- Instituto Americano Del ConcretoDokument6 SeitenInstituto Americano Del ConcretoAugusto Diaz ValdiviaNoch keine Bewertungen
- Diapositivas Circulo de MohrDokument20 SeitenDiapositivas Circulo de MohrLiz Ccastillo100% (1)
- Pasos para El Proporcionamiento 1Dokument12 SeitenPasos para El Proporcionamiento 1juniorNoch keine Bewertungen
- METODO DE ESQUINA NOROESTE Y VOGUEL PARA RESOLVER PROBLEMAS DE PROGRAMACIÓN LINEALDokument4 SeitenMETODO DE ESQUINA NOROESTE Y VOGUEL PARA RESOLVER PROBLEMAS DE PROGRAMACIÓN LINEALAlejandroNoch keine Bewertungen
- Secciones de ConstrucciónDokument10 SeitenSecciones de ConstrucciónMauricio Alvarez SalazarNoch keine Bewertungen
- Probabilidad y EstadisticaDokument19 SeitenProbabilidad y EstadisticaOmarNoch keine Bewertungen
- Análisis estructural I con método de CrossDokument18 SeitenAnálisis estructural I con método de CrossWilmer Huaripata Mestanza100% (1)
- Dotacion y ConsumoDokument5 SeitenDotacion y ConsumoLUCNoch keine Bewertungen
- 2 Modelos de Optimización Matenegocios - Unidad 2Dokument44 Seiten2 Modelos de Optimización Matenegocios - Unidad 2hugo_castrillon_20% (1)
- Planteamiento Del ProblemaDokument8 SeitenPlanteamiento Del ProblemaAlexa Alcas100% (1)
- Metodos numericos UNCAL solucionarioDokument38 SeitenMetodos numericos UNCAL solucionariocarlospelaezNoch keine Bewertungen
- Hidráulica de CanalesDokument2 SeitenHidráulica de CanalesKalid Del BosqueNoch keine Bewertungen
- Problemas Resueltos de Hidrostatica LaboratorioDokument7 SeitenProblemas Resueltos de Hidrostatica LaboratorioH3RNAN 2BNoch keine Bewertungen
- Curva de Duración de Caudales AcumuladosDokument9 SeitenCurva de Duración de Caudales AcumuladosJokrsNoch keine Bewertungen
- Metodo de Los Pesos ElásticosDokument2 SeitenMetodo de Los Pesos ElásticosDaniela Alvarado CastilloNoch keine Bewertungen
- Método de Los DesplazamientosDokument6 SeitenMétodo de Los DesplazamientosJosé Ignacio LunaNoch keine Bewertungen
- Resistencia A La Compresión RequeridaDokument2 SeitenResistencia A La Compresión RequeridaRubén Darío EspinozaNoch keine Bewertungen
- Unidad 5 - Ecuaciones DiferencialesDokument55 SeitenUnidad 5 - Ecuaciones DiferencialesJulio c Resendiz100% (1)
- INVESTIGACIÓN DE MÉTODOS PARA EL CÁLCULO DE VALORES Y VECTORES PROPIOS - Denisse PérezDokument21 SeitenINVESTIGACIÓN DE MÉTODOS PARA EL CÁLCULO DE VALORES Y VECTORES PROPIOS - Denisse PérezAmethyst SmithNoch keine Bewertungen
- 2.4 Obras AccesoriasDokument6 Seiten2.4 Obras Accesoriasmanuel cervantes vazquezNoch keine Bewertungen
- Canales - Parcial 2 - Diseño HidraulicoDokument6 SeitenCanales - Parcial 2 - Diseño HidraulicoCarmen SandovalNoch keine Bewertungen
- Deduccion Matriz de Rigidez de Un Elemento Tipo VigaDokument10 SeitenDeduccion Matriz de Rigidez de Un Elemento Tipo VigaHaroldBriñezNoch keine Bewertungen
- CLASE 28 EJEMPLOS Metodo Estandar - Tanteo y Error y Paso DirectoDokument28 SeitenCLASE 28 EJEMPLOS Metodo Estandar - Tanteo y Error y Paso DirectoLizethVelascoNoch keine Bewertungen
- Aplicacion de La Tranformada de Laplace en La IngenieriaDokument7 SeitenAplicacion de La Tranformada de Laplace en La IngenieriaLuis Gerardo Sánchez SaavedraNoch keine Bewertungen
- Memoria Descriptiva 20210611 114615 899Dokument8 SeitenMemoria Descriptiva 20210611 114615 899Ing. Lemuel Sanchez PaucarNoch keine Bewertungen
- Serie de Taylor: Aplicaciones y ventajas de aproximar funcionesDokument3 SeitenSerie de Taylor: Aplicaciones y ventajas de aproximar funcionesCalixto Apaza Duran0% (1)
- UNIDAD 5 Modelos para La Planeación Programación y Control de Proyectos de ConstrucciónDokument31 SeitenUNIDAD 5 Modelos para La Planeación Programación y Control de Proyectos de ConstrucciónGino ReyesNoch keine Bewertungen
- Estadística AplicadaDokument4 SeitenEstadística AplicadaCarlos Rincón100% (1)
- RM #531-2021-Minedu - Disposiciones para El Retorno A La Presencialidad y - o Semipresencialidad y La Prestacion Del Servicio Educativo para El Año Escolar 2022 en IieeDokument52 SeitenRM #531-2021-Minedu - Disposiciones para El Retorno A La Presencialidad y - o Semipresencialidad y La Prestacion Del Servicio Educativo para El Año Escolar 2022 en IieejaimesanchezgNoch keine Bewertungen
- EXT joOIG1Lz6VLxLbX8OHTJDokument5 SeitenEXT joOIG1Lz6VLxLbX8OHTJAlvaro Gaitan PeñaNoch keine Bewertungen
- Hazen - Williams Trabajoi FinalDokument13 SeitenHazen - Williams Trabajoi FinalDaymerRousselHuaytaHuamanNoch keine Bewertungen
- Productos NotablesDokument9 SeitenProductos NotablesKristian Mulatillo PanduroNoch keine Bewertungen
- 3 Epistemología y Teoría Del ConocimientoDokument19 Seiten3 Epistemología y Teoría Del ConocimientoDaymerRousselHuaytaHuamanNoch keine Bewertungen
- Problemas - Mecanica - Unidad 1 - VectoresDokument2 SeitenProblemas - Mecanica - Unidad 1 - VectoresDaymerRousselHuaytaHuamanNoch keine Bewertungen
- Ciencia Tecnologia 5 2020Dokument72 SeitenCiencia Tecnologia 5 2020DaymerRousselHuaytaHuaman100% (2)
- La Ciencia, Definición, Objetivos, CaracterísticasDokument13 SeitenLa Ciencia, Definición, Objetivos, CaracterísticasDaymerRousselHuaytaHuamanNoch keine Bewertungen
- Bases Del ConcursoDokument7 SeitenBases Del ConcursoDaymerRousselHuaytaHuamanNoch keine Bewertungen
- 2 Aspectos Generales de La Epistemología.Dokument15 Seiten2 Aspectos Generales de La Epistemología.DaymerRousselHuaytaHuaman33% (3)
- Primera Practicada Calificada de Mecánica - EpialDokument1 SeitePrimera Practicada Calificada de Mecánica - EpialDaymerRousselHuaytaHuamanNoch keine Bewertungen
- Efecto InvernaderoDokument11 SeitenEfecto InvernaderoDaymerRousselHuaytaHuamanNoch keine Bewertungen
- Precioparticularinsumotipovtipo2 ElectDokument1 SeitePrecioparticularinsumotipovtipo2 ElectAndre Vega LiñanNoch keine Bewertungen
- Norma E030 ModificadaDokument32 SeitenNorma E030 ModificadaGabriela Cunia Pérez100% (1)
- Presupuestoclienteresumen PDFDokument4 SeitenPresupuestoclienteresumen PDFCesar GuevaraNoch keine Bewertungen
- Gestión Del Tiempo Como Habilidad DirectivaDokument25 SeitenGestión Del Tiempo Como Habilidad DirectivaIvan OrozcoNoch keine Bewertungen
- Construcción de alcantarillaDokument1 SeiteConstrucción de alcantarillaDaymerRousselHuaytaHuamanNoch keine Bewertungen
- Apu Elect PDFDokument11 SeitenApu Elect PDFtigres1212Noch keine Bewertungen
- Apu - Sanit 2015Dokument10 SeitenApu - Sanit 2015joellontopNoch keine Bewertungen
- Precioparticularinsumotipovtipo2 ArqDokument1 SeitePrecioparticularinsumotipovtipo2 Arqnoctambulo2Noch keine Bewertungen
- CronogrmaDokument2 SeitenCronogrmaDaymerRousselHuaytaHuamanNoch keine Bewertungen
- Base y ReglamentoDokument3 SeitenBase y ReglamentoDaymerRousselHuaytaHuamanNoch keine Bewertungen
- Apu Arquit PDFDokument8 SeitenApu Arquit PDFCesar GuevaraNoch keine Bewertungen
- Precioparticularinsumotipovtipo2 ArqDokument1 SeitePrecioparticularinsumotipovtipo2 Arqnoctambulo2Noch keine Bewertungen
- Impacto AmbientalDokument37 SeitenImpacto AmbientalAndrea Vivianna Alcalá ValcárcelNoch keine Bewertungen
- ExpedienteDokument12 SeitenExpedienteDaymerRousselHuaytaHuamanNoch keine Bewertungen
- Redes VialesDokument16 SeitenRedes VialesJoseph Valdez GarcíaNoch keine Bewertungen
- Sistema de TransportesDokument22 SeitenSistema de TransportesDaymerRousselHuaytaHuamanNoch keine Bewertungen
- IntroducciónDokument28 SeitenIntroducciónDaymerRousselHuaytaHuamanNoch keine Bewertungen
- RAICES COMUNEsDokument2 SeitenRAICES COMUNEsLeonel David de LimaNoch keine Bewertungen
- Termo PlusDokument9 SeitenTermo PlusZeus RamirezNoch keine Bewertungen
- LENGUAJE TemarioDokument75 SeitenLENGUAJE TemarioMila DCNoch keine Bewertungen
- 2dogrado ComputacionDokument86 Seiten2dogrado ComputacionAlfredo HernandezNoch keine Bewertungen
- Plan Haccp Queso EdamDokument14 SeitenPlan Haccp Queso EdamWilmer Rodriguez100% (2)
- Formato-02-Silabo SE214-2023-1Dokument3 SeitenFormato-02-Silabo SE214-2023-1ANDRE ROSALES SAAVEDRANoch keine Bewertungen
- Jesús es el camino, la verdad y la vidaDokument1 SeiteJesús es el camino, la verdad y la vidaJorge Pedro Condori NeiraNoch keine Bewertungen
- CONVERSION DE UNIDADES ReflexionDokument2 SeitenCONVERSION DE UNIDADES ReflexionalvaroNoch keine Bewertungen
- Formacion VilquechicoDokument1 SeiteFormacion VilquechicoalexanderNoch keine Bewertungen
- Alineamiento Entre PuntosDokument18 SeitenAlineamiento Entre PuntosCarlos Ivan Cojal Aguilar50% (2)
- GSA: El Riesgo Oculto en Los (Re) Encuentros. Barbara GonyoDokument11 SeitenGSA: El Riesgo Oculto en Los (Re) Encuentros. Barbara GonyoGavi CanoNoch keine Bewertungen
- 1SFN030300R1000 vm19Dokument3 Seiten1SFN030300R1000 vm19OMAR QUISBERTNoch keine Bewertungen
- Reglamento de Protección Ambiental DS 019 - 97 ITINCIDokument38 SeitenReglamento de Protección Ambiental DS 019 - 97 ITINCIWilder Casimir Manuelo100% (1)
- Cinética EnzimáticaDokument4 SeitenCinética EnzimáticaDiego LegaspiNoch keine Bewertungen
- Técnicas de Coordinación MotrizDokument7 SeitenTécnicas de Coordinación MotrizJULIETH CAROLINA LUNA TIMANANoch keine Bewertungen
- Historia Santa Faz icono antiguo JesúsDokument19 SeitenHistoria Santa Faz icono antiguo JesúsSissy Villagómez100% (2)
- Informe MohoDokument3 SeitenInforme MohoVictor LaraNoch keine Bewertungen
- El Teatro Negro3Dokument2 SeitenEl Teatro Negro3Arely HernandezNoch keine Bewertungen
- Análisis Espacial de BarcinoDokument5 SeitenAnálisis Espacial de BarcinoFABRICIO GABRIEL SEMINARIO RAMIREZNoch keine Bewertungen
- Foda EjemploDokument3 SeitenFoda EjemploCisne SalasNoch keine Bewertungen
- MAGNETOTERAPIADokument6 SeitenMAGNETOTERAPIAJUAN MIGUEL Huisacayna YanaNoch keine Bewertungen
- Lección 1 - Ge - GiDokument4 SeitenLección 1 - Ge - GiAlejandra MandarinaNoch keine Bewertungen
- Arquitectura inca: solidez, sencillez y simetríaDokument3 SeitenArquitectura inca: solidez, sencillez y simetríaVerónica Rodriguez OrtizNoch keine Bewertungen
- MODULO 2 Filosofia UncausDokument7 SeitenMODULO 2 Filosofia UncausMarcelo FleitaNoch keine Bewertungen
- Entrega Cronograma y ExamenesDokument6 SeitenEntrega Cronograma y ExamenesAlejandra Minero RamosNoch keine Bewertungen
- 10c Cultivo de Conchas de AbanicoDokument20 Seiten10c Cultivo de Conchas de AbanicoraswerNoch keine Bewertungen