Das könnte Ihnen auch gefallen
- Boost RewardsDokument4 SeitenBoost RewardsXxGamerZxX ツ67% (3)
- Robust and Efficient Multi-Object Detection and Tracking For Vehicle Perception Systems Using Radar and CameraDokument6 SeitenRobust and Efficient Multi-Object Detection and Tracking For Vehicle Perception Systems Using Radar and CameraDivine Grace BurmalNoch keine Bewertungen
- Power Analysis and Ir Drop Analysis FlowDokument18 SeitenPower Analysis and Ir Drop Analysis FlowMayur AgarwalNoch keine Bewertungen
- Adobe Illustrator CC Keyboard Shortcuts For WindowsDokument1 SeiteAdobe Illustrator CC Keyboard Shortcuts For Windowstranthengoc920% (1)
- Basic PeopleSoft Query Updated 011702Dokument58 SeitenBasic PeopleSoft Query Updated 011702anusha12344321Noch keine Bewertungen
- Oracle Incentive Compensation Demo: Presenter: Abhijit ChakrabortyDokument20 SeitenOracle Incentive Compensation Demo: Presenter: Abhijit Chakrabortyகண்ணன் ராமன்Noch keine Bewertungen
- Synopsis Format 6th Sem JDCOEM GRP 4Dokument17 SeitenSynopsis Format 6th Sem JDCOEM GRP 4Prajwal BhajeNoch keine Bewertungen
- Feature Fusion Based On Convolutional Neural Netwo PDFDokument8 SeitenFeature Fusion Based On Convolutional Neural Netwo PDFNguyễn Thành TânNoch keine Bewertungen
- Convolutional Neural Network With Data Augmentation For SAR Target RecognitionDokument5 SeitenConvolutional Neural Network With Data Augmentation For SAR Target RecognitionS M RizviNoch keine Bewertungen
- POSTER 162 MahmudulArifDokument1 SeitePOSTER 162 MahmudulArifT T RezaNoch keine Bewertungen
- Image Upscaling Based Convolutional Neural Network For Better Reconstruction QualityDokument6 SeitenImage Upscaling Based Convolutional Neural Network For Better Reconstruction Qualityhieu phamNoch keine Bewertungen
- Measurement: Xiaoxun Zhu, Dongnan Hou, Pei Zhou, Zhonghe Han, Yiming Yuan, Weiwei Zhou, Qianqian YinDokument10 SeitenMeasurement: Xiaoxun Zhu, Dongnan Hou, Pei Zhou, Zhonghe Han, Yiming Yuan, Weiwei Zhou, Qianqian YinErick Pizarro BarreraNoch keine Bewertungen
- Explaining Neural Networks Semantically and QuantitativelyDokument19 SeitenExplaining Neural Networks Semantically and Quantitativelygupnaval2473Noch keine Bewertungen
- Character Proposal Network For Robust Text Extraction: Shuye Zhang, Mude Lin, Tianshui Chen, Lianwen Jin, Liang LinDokument5 SeitenCharacter Proposal Network For Robust Text Extraction: Shuye Zhang, Mude Lin, Tianshui Chen, Lianwen Jin, Liang LinKeana LermanNoch keine Bewertungen
- 5634 Convolutional Neural Networks With Intra Layer Recurrent Connections For Scene LabelingDokument9 Seiten5634 Convolutional Neural Networks With Intra Layer Recurrent Connections For Scene LabelingheavywaterNoch keine Bewertungen
- Mid2 Wang Decoupling-and-Aggregating For Image Exposure CorrectionDokument10 SeitenMid2 Wang Decoupling-and-Aggregating For Image Exposure Correctionperry1005Noch keine Bewertungen
- Deeplab: Semantic Image Segmentation With Deep Convolutional Nets, Atrous Convolution, and Fully Connected CrfsDokument14 SeitenDeeplab: Semantic Image Segmentation With Deep Convolutional Nets, Atrous Convolution, and Fully Connected CrfsDesigner TeesNoch keine Bewertungen
- SCT 3Dokument9 SeitenSCT 3Saumya ChauhanNoch keine Bewertungen
- Segmentation and Classification of CT Renal Images Using Deep NetworksDokument8 SeitenSegmentation and Classification of CT Renal Images Using Deep NetworksraghunaathNoch keine Bewertungen
- ASDN: A Deep Convolutional Network For Arbitrary Scale Image Super-ResolutionDokument12 SeitenASDN: A Deep Convolutional Network For Arbitrary Scale Image Super-ResolutionVadim Koz Jr.Noch keine Bewertungen
- Quantifying Translation-Invariance in Convolutional Neural NetworksDokument6 SeitenQuantifying Translation-Invariance in Convolutional Neural Networkseric fantonNoch keine Bewertungen
- Convolutional Neural Networks For No-Reference Image Quality AssessmentDokument8 SeitenConvolutional Neural Networks For No-Reference Image Quality Assessmentgitov13916Noch keine Bewertungen
- SAR ATR With Full-Angle Data Augmentation and FeatDokument5 SeitenSAR ATR With Full-Angle Data Augmentation and FeatLeoNoch keine Bewertungen
- A Rotation-Invariant Convolutional Neural Network For ImageDokument5 SeitenA Rotation-Invariant Convolutional Neural Network For ImageMohammad WaleedNoch keine Bewertungen
- DPC-Net: Deep Pose Correction For Visual Localization: Valentin Peretroukhin, and Jonathan KellyDokument8 SeitenDPC-Net: Deep Pose Correction For Visual Localization: Valentin Peretroukhin, and Jonathan Kellypradip guptaNoch keine Bewertungen
- P C N N R E I: Runing Onvolutional Eural Etworks FOR Esource Fficient NferenceDokument17 SeitenP C N N R E I: Runing Onvolutional Eural Etworks FOR Esource Fficient NferenceAnshul VijayNoch keine Bewertungen
- Corresponding AuthorDokument6 SeitenCorresponding AuthorArs Arifur RahmanNoch keine Bewertungen
- Hardware Complexity Analysis of Deep Neural Networks and Decision Tree Ensembles For Real-Time Neural Data Classi CationDokument5 SeitenHardware Complexity Analysis of Deep Neural Networks and Decision Tree Ensembles For Real-Time Neural Data Classi CationSimon linNoch keine Bewertungen
- A Deep Neural Network For Image Quality AssessmentDokument5 SeitenA Deep Neural Network For Image Quality Assessmentgitov13916Noch keine Bewertungen
- CNN Imaging NetworksDokument13 SeitenCNN Imaging NetworksnwuxvNoch keine Bewertungen
- Improvement of Classical Wavelet Network Over ANN in Image CompressionDokument6 SeitenImprovement of Classical Wavelet Network Over ANN in Image Compressionanil kasotNoch keine Bewertungen
- Resiliency of Deep Neural Networks Under QuantizationsDokument11 SeitenResiliency of Deep Neural Networks Under QuantizationsGod GamingNoch keine Bewertungen
- Image Super-Resolution Using Very Deep Residual Channel Attention NetworksDokument16 SeitenImage Super-Resolution Using Very Deep Residual Channel Attention NetworksDenis ChikiBrikiNoch keine Bewertungen
- Conditional Health Monitoring of Gear Box Using Convolutional Neural NetworkDokument14 SeitenConditional Health Monitoring of Gear Box Using Convolutional Neural NetworkKaustav DeNoch keine Bewertungen
- P100-Morocho CayamcelaDokument5 SeitenP100-Morocho CayamcelanullNoch keine Bewertungen
- Deep Cellular Recurrent Network For Efficient Analysis of Time-Series Data With Spatial InformationDokument10 SeitenDeep Cellular Recurrent Network For Efficient Analysis of Time-Series Data With Spatial Informationbaltazzar_90Noch keine Bewertungen
- Sensors: HEMIGEN: Human Embryo Image Generator Based On Generative Adversarial NetworksDokument16 SeitenSensors: HEMIGEN: Human Embryo Image Generator Based On Generative Adversarial NetworksPrabhuti ChauhanNoch keine Bewertungen
- Competitive Inner-Imaging Squeeze and Excitation For Residual Network PDFDokument17 SeitenCompetitive Inner-Imaging Squeeze and Excitation For Residual Network PDFMistlemagicNoch keine Bewertungen
- Semantic Segmentation Architecture: A Key Part of Scene Understanding ApplicationsDokument9 SeitenSemantic Segmentation Architecture: A Key Part of Scene Understanding ApplicationsSunilmahek MahekNoch keine Bewertungen
- Csrnet: Dilated Convolutional Neural Networks For Understanding The Highly Congested ScenesDokument16 SeitenCsrnet: Dilated Convolutional Neural Networks For Understanding The Highly Congested ScenesJoseph JeremyNoch keine Bewertungen
- Deep Learning For Waveform Estimation and Imaging in Passive RadarDokument25 SeitenDeep Learning For Waveform Estimation and Imaging in Passive RadarefgdfhsdNoch keine Bewertungen
- Multiresolution Neural Networks For ImagingDokument12 SeitenMultiresolution Neural Networks For Imagingangel.paternina423Noch keine Bewertungen
- Concurrent Spatial and Channel Squeeze & Excitation' in Fully Convolutional NetworksDokument8 SeitenConcurrent Spatial and Channel Squeeze & Excitation' in Fully Convolutional NetworksMistlemagicNoch keine Bewertungen
- RACE-Net: A Recurrent Neural Network For Biomedical Image SegmentationDokument12 SeitenRACE-Net: A Recurrent Neural Network For Biomedical Image SegmentationSnehaNoch keine Bewertungen
- Neural 1Dokument7 SeitenNeural 1Mudassir RNoch keine Bewertungen
- Snowflake An Efficient Hardware Accelerator For Convolutional Neural NetworksDokument4 SeitenSnowflake An Efficient Hardware Accelerator For Convolutional Neural Networksynn1095004648Noch keine Bewertungen
- Skeleton-Based Action Recognition With Convolutional Neural Networks Chao Li, Qiaoyong Zhong, Di Xie, Shiliang Pu Hikvision Research Institute, Hangzhou, ChinaDokument4 SeitenSkeleton-Based Action Recognition With Convolutional Neural Networks Chao Li, Qiaoyong Zhong, Di Xie, Shiliang Pu Hikvision Research Institute, Hangzhou, ChinaArs Arifur RahmanNoch keine Bewertungen
- 15 SPL PcqiDokument4 Seiten15 SPL PcqiRasool ReddyNoch keine Bewertungen
- 1807 10584fhwfDokument6 Seiten1807 10584fhwfTiến Việt PhạmNoch keine Bewertungen
- Approximate MultiplierDokument12 SeitenApproximate MultiplierSohan SaiNoch keine Bewertungen
- 11 TOPS Photonic Convolutional Accelerator For Optical Neural Networks - RM - NatureDokument14 Seiten11 TOPS Photonic Convolutional Accelerator For Optical Neural Networks - RM - NaturemahadimasnadNoch keine Bewertungen
- Semantic Image Segmentation With Task-Specific Edge Detection Using Cnns and A Discriminatively Trained Domain TransformDokument10 SeitenSemantic Image Segmentation With Task-Specific Edge Detection Using Cnns and A Discriminatively Trained Domain TransformUnaixa KhanNoch keine Bewertungen
- Going Deeper With Contextual CNN For Hyperspectral Image ClassificationDokument14 SeitenGoing Deeper With Contextual CNN For Hyperspectral Image ClassificationaaaNoch keine Bewertungen
- Sedai2018 Joint Segmentation Uncertainty Visualization Retinal LayersDokument8 SeitenSedai2018 Joint Segmentation Uncertainty Visualization Retinal LayersbrecheisenNoch keine Bewertungen
- Transattunet: Multi-Level Attention-Guided U-Net With Transformer For Medical Image SegmentationDokument13 SeitenTransattunet: Multi-Level Attention-Guided U-Net With Transformer For Medical Image Segmentationnavneet prabhakarNoch keine Bewertungen
- GRAM Gradient Rescaling Attention Model For Data Uncertainty Estimation in Single Image Super ResolutionDokument6 SeitenGRAM Gradient Rescaling Attention Model For Data Uncertainty Estimation in Single Image Super ResolutionRaymon ArnoldNoch keine Bewertungen
- CSPN++: Learning Context and Resource Aware Convolutional Spatial Propagation Networks For Depth CompletionDokument8 SeitenCSPN++: Learning Context and Resource Aware Convolutional Spatial Propagation Networks For Depth CompletionArmandoNoch keine Bewertungen
- Exact Decomposition of Joint Low Rankness and Local Smoothness Plus Sparse Matrices PDFDokument16 SeitenExact Decomposition of Joint Low Rankness and Local Smoothness Plus Sparse Matrices PDFAMISHI VIJAY VIJAYNoch keine Bewertungen
- Fast and Accurate Image Super Resolution by Deep CNN With Skip Connection and Network in NetworkDokument9 SeitenFast and Accurate Image Super Resolution by Deep CNN With Skip Connection and Network in NetworkSAURABH nlNoch keine Bewertungen
- A Deep Learning Based No-Reference Image Quality Assessment Model For Single-Image Super-ResolutionDokument5 SeitenA Deep Learning Based No-Reference Image Quality Assessment Model For Single-Image Super-Resolutiongitov13916Noch keine Bewertungen
- 1-S2.0-S1746809421010727-Main - Trés ImportantDokument12 Seiten1-S2.0-S1746809421010727-Main - Trés ImportantZAHRA FASKANoch keine Bewertungen
- Reversible Data HidingDokument5 SeitenReversible Data HidingFahim ShaikNoch keine Bewertungen
- Facial Keypoint Recognition: Under The Guidance Of: Prof Amitabha MukerjeeDokument8 SeitenFacial Keypoint Recognition: Under The Guidance Of: Prof Amitabha MukerjeeRohitSansiyaNoch keine Bewertungen
- VQGAN: Taming Transformer For High-Resolution Image SynthesisDokument52 SeitenVQGAN: Taming Transformer For High-Resolution Image Synthesis3532929121Noch keine Bewertungen
- 1 s2.0 S0263224121002402 MainDokument19 Seiten1 s2.0 S0263224121002402 Mainvikas sharmaNoch keine Bewertungen
- Negotin 682 Reviewer Digests 2Dokument51 SeitenNegotin 682 Reviewer Digests 2Divine Grace BurmalNoch keine Bewertungen
- GravityDokument2 SeitenGravityDivine Grace BurmalNoch keine Bewertungen
- Astro Electronics Corp. & Peter Roxas V. Philippine Export and Foreign Loan Guarantee Corporation G.R. No. 136729 September 23, 2003Dokument1 SeiteAstro Electronics Corp. & Peter Roxas V. Philippine Export and Foreign Loan Guarantee Corporation G.R. No. 136729 September 23, 2003Divine Grace BurmalNoch keine Bewertungen
- RESPONSE TIME - Definition in The Cambridge English DictionaryDokument7 SeitenRESPONSE TIME - Definition in The Cambridge English DictionaryDivine Grace BurmalNoch keine Bewertungen
- RAM, ROM, and Flash Memory - DummiesDokument2 SeitenRAM, ROM, and Flash Memory - DummiesDivine Grace BurmalNoch keine Bewertungen
- J2802 - Blind Spot Monitoring System (BSMS) - Operating Characteristics and User Interface - SAE InternationalDokument1 SeiteJ2802 - Blind Spot Monitoring System (BSMS) - Operating Characteristics and User Interface - SAE InternationalDivine Grace BurmalNoch keine Bewertungen
- A Comprehensive Examination of Naturalistic Lane-ChangesDokument236 SeitenA Comprehensive Examination of Naturalistic Lane-ChangesDivine Grace BurmalNoch keine Bewertungen
- ISO 17387 - 2008 (En), Intelligent Transport SystemsDokument1 SeiteISO 17387 - 2008 (En), Intelligent Transport SystemsDivine Grace BurmalNoch keine Bewertungen
- Automatic Motorcycle Detection On Public Roads PDFDokument9 SeitenAutomatic Motorcycle Detection On Public Roads PDFDivine Grace BurmalNoch keine Bewertungen
- 01 09 FAS 2500 Platform Tour PDFDokument4 Seiten01 09 FAS 2500 Platform Tour PDFmukiveNoch keine Bewertungen
- New Instructions Manual - New (30-06-2022)Dokument19 SeitenNew Instructions Manual - New (30-06-2022)rarhi.krish8480Noch keine Bewertungen
- CPPDokument10 SeitenCPPUltimateDBZNoch keine Bewertungen
- Applied Mathematics (9035)Dokument4 SeitenApplied Mathematics (9035)Mukul KulkarniNoch keine Bewertungen
- Register Transfer LanguageDokument14 SeitenRegister Transfer Languagemanojrajput81811Noch keine Bewertungen
- Fmea PDFDokument2 SeitenFmea PDFPradeep RNoch keine Bewertungen
- CS8080 - IRT - Question Bank - R 2017 - GCTDokument10 SeitenCS8080 - IRT - Question Bank - R 2017 - GCT20CS001 Abinaya S CSENoch keine Bewertungen
- B28012018V5 1Dokument23 SeitenB28012018V5 1Sebastián Zamorano GuerreroNoch keine Bewertungen
- Unit 1 Notes-1Dokument10 SeitenUnit 1 Notes-1sanchitghareNoch keine Bewertungen
- White Paper Bone Suppression Chest 201403Dokument6 SeitenWhite Paper Bone Suppression Chest 201403ShinjaKarasumoriNoch keine Bewertungen
- IM Appendix C UCL Verification Ed12Dokument34 SeitenIM Appendix C UCL Verification Ed12Chong Fong KimNoch keine Bewertungen
- BMC Control-M ArchitectureDokument66 SeitenBMC Control-M ArchitecturejchaurasiaNoch keine Bewertungen
- 3200T ProcessorDokument45 Seiten3200T ProcessorJosé Miguel Espinoza JiménezNoch keine Bewertungen
- Transfer of Delivery Line in Cycle CountDokument10 SeitenTransfer of Delivery Line in Cycle CountsubbaraocrmNoch keine Bewertungen
- CP776Dokument58 SeitenCP776jeevan_v_mNoch keine Bewertungen
- Bill Format Computer Repair ServiceDokument2 SeitenBill Format Computer Repair ServicejedossousNoch keine Bewertungen
- Odoo Case StudyDokument2 SeitenOdoo Case StudyDawit SeleshNoch keine Bewertungen
- 5th Semester MG University Civil Engineering SyllabusDokument12 Seiten5th Semester MG University Civil Engineering SyllabusJerrin JustinNoch keine Bewertungen
- OS WorksheetDokument5 SeitenOS WorksheetWiki EthiopiaNoch keine Bewertungen
- XxcvsaaDokument4 SeitenXxcvsaaMON FRYNoch keine Bewertungen
- Computer AmbushDokument33 SeitenComputer Ambushremow100% (2)
- Fingerprinting 802.11 Rate Adaptation AlgorithmsDokument9 SeitenFingerprinting 802.11 Rate Adaptation AlgorithmsFavour AdenugbaNoch keine Bewertungen
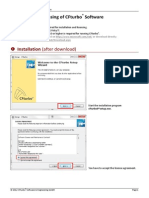
- Cfturbo Setup GuideDokument5 SeitenCfturbo Setup GuideBurnles SnaeyNoch keine Bewertungen
- RFI DARPA-SN-13-35 Far Out Networking SymposiumDokument5 SeitenRFI DARPA-SN-13-35 Far Out Networking SymposiumforamitgargNoch keine Bewertungen