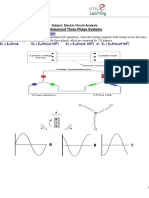
Das könnte Ihnen auch gefallen
- The Quantitative Method - Statistics SolutionsDokument2 SeitenThe Quantitative Method - Statistics SolutionsIsrael PopeNoch keine Bewertungen
- PR2 Lessons 1 3 Study GuideDokument9 SeitenPR2 Lessons 1 3 Study GuideDiana OrdanezaNoch keine Bewertungen
- Manual and Guidelines-ThesisDokument33 SeitenManual and Guidelines-ThesisBrd Emmanuel100% (1)
- Patient Information Systems in The LiteratureDokument6 SeitenPatient Information Systems in The LiteratureJohn MunaonyediNoch keine Bewertungen
- The Good Ones Chapter 3Dokument6 SeitenThe Good Ones Chapter 3jasmin grace tanNoch keine Bewertungen
- Essay: Clinical Data RepositoriesDokument2 SeitenEssay: Clinical Data RepositoriesChristine CondrillonNoch keine Bewertungen
- Doh Hiv Art RegistryDokument7 SeitenDoh Hiv Art Registryrommel mendoza100% (1)
- Radiologic Students' Satisfaction With College FacilitiesDokument2 SeitenRadiologic Students' Satisfaction With College FacilitiesJoanna FernandezNoch keine Bewertungen
- Chapter 1 ResearchDokument6 SeitenChapter 1 ResearchNosaj TriumpsNoch keine Bewertungen
- Proposal Wellness HubDokument8 SeitenProposal Wellness HubAliah Gabrielle SantosNoch keine Bewertungen
- The Impact of Covid19 Pandemic To The Transgression of Cybercrime in MetromanilaDokument39 SeitenThe Impact of Covid19 Pandemic To The Transgression of Cybercrime in MetromanilaMariyaJesika ChengNoch keine Bewertungen
- Factors Influencing Job SatisfactionDokument5 SeitenFactors Influencing Job SatisfactionZaher ArakkalNoch keine Bewertungen
- ProspectusDokument3 SeitenProspectusKaren Kaye LastimosaNoch keine Bewertungen
- CHAPTER 3 GROUP 2 CDokument7 SeitenCHAPTER 3 GROUP 2 CYin ObispoNoch keine Bewertungen
- Demand for Health as Durable Capital StockDokument33 SeitenDemand for Health as Durable Capital StockMichele DalenaNoch keine Bewertungen
- The Clinical Competencies of Radiologic Technology Interns of Batch 2018 2019...Dokument84 SeitenThe Clinical Competencies of Radiologic Technology Interns of Batch 2018 2019...Sunshine Ellen J. GuyoNoch keine Bewertungen
- (Part-Time) Sikap Re-Entry Action PlanDokument3 Seiten(Part-Time) Sikap Re-Entry Action PlanraudenNoch keine Bewertungen
- Handouts in Research 2Dokument5 SeitenHandouts in Research 2nona yamutNoch keine Bewertungen
- Abstract Vs Executive Summary-NHSDokument3 SeitenAbstract Vs Executive Summary-NHSdillamyNoch keine Bewertungen
- Chapter 3 Edited 7-26-22Dokument7 SeitenChapter 3 Edited 7-26-22Raima CABARONoch keine Bewertungen
- PHA Online BLS-ACLS Training ProgramDokument9 SeitenPHA Online BLS-ACLS Training ProgramJoyNoch keine Bewertungen
- Barangay Profilling Information SystemDokument113 SeitenBarangay Profilling Information SystemAnthony Jade BrosasNoch keine Bewertungen
- Determinants of Deviant Workplace BehaviorDokument15 SeitenDeterminants of Deviant Workplace Behaviorerfan441790Noch keine Bewertungen
- Streamline patient data with mobile symptom monitoringDokument1 SeiteStreamline patient data with mobile symptom monitoringKevin VillotaNoch keine Bewertungen
- Rochelle L. Villegas, RMT - Medical Laboratory TechnicianDokument2 SeitenRochelle L. Villegas, RMT - Medical Laboratory TechnicianJigsaw PHNoch keine Bewertungen
- Research Methods and Data Collection of Medical StudentsDokument10 SeitenResearch Methods and Data Collection of Medical StudentsLemuel SabanalNoch keine Bewertungen
- Module 6 - Philippine E-Health Strategic Plan (PeHSP) and Philippine Health Information Exchange (PHIE)Dokument19 SeitenModule 6 - Philippine E-Health Strategic Plan (PeHSP) and Philippine Health Information Exchange (PHIE)Zuriel San PedroNoch keine Bewertungen
- HPAD 201 Session 13 Sep 15 SocMob, Advocacy and Social MarketingDokument26 SeitenHPAD 201 Session 13 Sep 15 SocMob, Advocacy and Social MarketingArianne A ZamoraNoch keine Bewertungen
- Dissertation OutlineDokument9 SeitenDissertation OutlineNaalain e SyedaNoch keine Bewertungen
- Review of Related LiteratureDokument3 SeitenReview of Related LiteratureKeira Estrella100% (1)
- Review of Related LiteratureDokument5 SeitenReview of Related LiteratureCake ManNoch keine Bewertungen
- Factors Inf Luencing Consumer Purchasing Patterns of Generic Versus Brand Name Over-the-Counter DrugsDokument6 SeitenFactors Inf Luencing Consumer Purchasing Patterns of Generic Versus Brand Name Over-the-Counter DrugsRizka Sarastri SumardionoNoch keine Bewertungen
- Capstone Project WWDDokument32 SeitenCapstone Project WWDJhanvi GoelNoch keine Bewertungen
- Positive Youth Development Through Leisure: Confronting The COVID-19 PandemicDokument20 SeitenPositive Youth Development Through Leisure: Confronting The COVID-19 PandemicZaira Magayon100% (1)
- HAAD RequirementsDokument2 SeitenHAAD RequirementscloydmarvinpsegundoNoch keine Bewertungen
- Hospital Info Systems GuideDokument11 SeitenHospital Info Systems GuideClarisse De GuzmanNoch keine Bewertungen
- Edrin Stat Module 1-3Dokument8 SeitenEdrin Stat Module 1-3Edrin Roy Cachero Sy100% (1)
- Who Leprosy Control BurdenDokument44 SeitenWho Leprosy Control BurdenClaire SoletaNoch keine Bewertungen
- Certificate of Validation 1Dokument1 SeiteCertificate of Validation 1Vonn GuintoNoch keine Bewertungen
- Capstone ProjectDokument58 SeitenCapstone ProjectRey Sedigo100% (1)
- Edited Webinar Proposal 5Dokument3 SeitenEdited Webinar Proposal 5Nath Tan ParroNoch keine Bewertungen
- Administrative Order No. 2005-0032Dokument14 SeitenAdministrative Order No. 2005-0032Cherrylou BudayNoch keine Bewertungen
- Bioethics ReflectionDokument3 SeitenBioethics ReflectionDanielle Sy EncinaresNoch keine Bewertungen
- RLE Fee Alleviation Plea to President Marcos JrDokument2 SeitenRLE Fee Alleviation Plea to President Marcos JrLOUISE ANNE NAGALNoch keine Bewertungen
- DLSU Research Congress Explores Knowledge Building for Industry 4.0Dokument189 SeitenDLSU Research Congress Explores Knowledge Building for Industry 4.0Voltaire MistadesNoch keine Bewertungen
- Best Technology Capstone Project Ideas PDFDokument2 SeitenBest Technology Capstone Project Ideas PDFJoel JuanzoNoch keine Bewertungen
- Revised Research Study NCM111Dokument23 SeitenRevised Research Study NCM111Arvin PenalosaNoch keine Bewertungen
- LETTER of Approval HehehehehehDokument3 SeitenLETTER of Approval HehehehehehLeeyan DerNoch keine Bewertungen
- Chapter 3Dokument3 SeitenChapter 3Jane SandovalNoch keine Bewertungen
- Ethical Issues in ResearchDokument3 SeitenEthical Issues in ResearchAbrar AhmadNoch keine Bewertungen
- Teaching Competency of Nursing Educators and Caring Attitude of Nursing StudentsDokument26 SeitenTeaching Competency of Nursing Educators and Caring Attitude of Nursing StudentsJaine NicolleNoch keine Bewertungen
- Rev Manual DCF & Cert Page For Muns & CCs - PY 2018 - 2018 ProjPop - Updated 011619Dokument12 SeitenRev Manual DCF & Cert Page For Muns & CCs - PY 2018 - 2018 ProjPop - Updated 011619Sheena SilorioNoch keine Bewertungen
- Thesis Seminar TopicDokument37 SeitenThesis Seminar Topicruth xylene miguelNoch keine Bewertungen
- Background of The Study: Smart Pushcart System With Automated Billing Using RFID 1Dokument8 SeitenBackground of The Study: Smart Pushcart System With Automated Billing Using RFID 1kennnXDNoch keine Bewertungen
- Nursing Informatics Module 3 5Dokument13 SeitenNursing Informatics Module 3 5Al TheóNoch keine Bewertungen
- Customers Switching Intentions Behavior in Retail Hypermarket Kingdom of Saudi Arabia: Customers Switching Intentions Behavior in Retail HypermarketVon EverandCustomers Switching Intentions Behavior in Retail Hypermarket Kingdom of Saudi Arabia: Customers Switching Intentions Behavior in Retail HypermarketNoch keine Bewertungen
- Disaster Resilience in Asia: A Special Supplement of Asia’s Journey to Prosperity: Policy, Market, and Technology Over 50 YearsVon EverandDisaster Resilience in Asia: A Special Supplement of Asia’s Journey to Prosperity: Policy, Market, and Technology Over 50 YearsNoch keine Bewertungen
- Lesson 1: Introduction To Statistics ObjectivesDokument12 SeitenLesson 1: Introduction To Statistics ObjectivesTracy Blair Napa-egNoch keine Bewertungen
- Chapter One: 1.1definition and Classification of StatisticsDokument22 SeitenChapter One: 1.1definition and Classification of StatisticsasratNoch keine Bewertungen
- "For I Know The Plans I Have For You, Declares The LORD, Plans For Welfare and Not For Evil, To Give You A Future and A Hope." - Jeremiah 29:11Dokument6 Seiten"For I Know The Plans I Have For You, Declares The LORD, Plans For Welfare and Not For Evil, To Give You A Future and A Hope." - Jeremiah 29:11Carmina CarganillaNoch keine Bewertungen
- Electromechanical System Transfer FunctionsDokument15 SeitenElectromechanical System Transfer FunctionsCandy ChocolateNoch keine Bewertungen
- Electromechanical System Transfer FunctionsDokument15 SeitenElectromechanical System Transfer FunctionsCandy ChocolateNoch keine Bewertungen
- Curing of Concrete 4BDokument12 SeitenCuring of Concrete 4BCandy ChocolateNoch keine Bewertungen
- 11 Ligthingdesign CalculationsDokument17 Seiten11 Ligthingdesign CalculationsRussel TalastasNoch keine Bewertungen
- Producing Amorphous White Silica From Rice Husk: ArticleDokument5 SeitenProducing Amorphous White Silica From Rice Husk: ArticleCandy ChocolateNoch keine Bewertungen
- Transfer Function GuideDokument9 SeitenTransfer Function GuideCandy ChocolateNoch keine Bewertungen
- BJT BiasingDokument10 SeitenBJT BiasingCandy Chocolate0% (1)
- Device NumbersDokument1 SeiteDevice NumbersCandy ChocolateNoch keine Bewertungen
- What Is Renewable EnergyDokument1 SeiteWhat Is Renewable EnergyCandy ChocolateNoch keine Bewertungen
- The Effect of Demand Response On DistributionDokument7 SeitenThe Effect of Demand Response On DistributionCandy ChocolateNoch keine Bewertungen
- Pole-to-Ground Fault Analysis in Transmission Line of DC Grids Based On VSCDokument5 SeitenPole-to-Ground Fault Analysis in Transmission Line of DC Grids Based On VSCCandy ChocolateNoch keine Bewertungen
- (Handbook) Neil Sclater, John E. Traister-Handbook of Electrical Design Details-McGraw-Hill Professional (2003)Dokument14 Seiten(Handbook) Neil Sclater, John E. Traister-Handbook of Electrical Design Details-McGraw-Hill Professional (2003)Candy ChocolateNoch keine Bewertungen
- 20 25 Gamil PDFDokument6 Seiten20 25 Gamil PDFNelma Ap. F. LopesNoch keine Bewertungen
- A Case Study For Loss Reduction in Distribution Networks Using Shunt CapacitorsDokument6 SeitenA Case Study For Loss Reduction in Distribution Networks Using Shunt CapacitorsCandy ChocolateNoch keine Bewertungen
- 3 1-CurvilinearmotionDokument19 Seiten3 1-Curvilinearmotionkristine trosoNoch keine Bewertungen
- Chapter2 Boolean Algebra and Logic GatesDokument30 SeitenChapter2 Boolean Algebra and Logic Gateszaman_munooNoch keine Bewertungen
- OJT - Narrative ReportDokument31 SeitenOJT - Narrative Reportzhaljoug89% (114)
- Unbalanced 3-Phase System PDFDokument16 SeitenUnbalanced 3-Phase System PDFCandy ChocolateNoch keine Bewertungen
- SP 1 (Fluid Properties)Dokument14 SeitenSP 1 (Fluid Properties)Jap Ibe50% (2)
- AC and DC Machinery Review QuestionsDokument4 SeitenAC and DC Machinery Review Questionsedwinjayar50% (6)
- SP 1 Fluid PropertiesDokument13 SeitenSP 1 Fluid PropertiesCandy ChocolateNoch keine Bewertungen
- Thermo 5th Chap03P102Dokument20 SeitenThermo 5th Chap03P102IENCSNoch keine Bewertungen
- Engineering Electromagnetics: Dr.-Ing. Erwin Sitompul President UniversityDokument26 SeitenEngineering Electromagnetics: Dr.-Ing. Erwin Sitompul President UniversityCandy Chocolate100% (1)
- Gauss ExamplesDokument5 SeitenGauss ExamplesHerath Mudiyanselage Indika HerathNoch keine Bewertungen
- Air Properties Table for Ideal GasesDokument4 SeitenAir Properties Table for Ideal GasesRandi JanuhapisNoch keine Bewertungen
- Emf and CircuitsDokument5 SeitenEmf and CircuitsCandy ChocolateNoch keine Bewertungen
- Q053 Wegman 2016Dokument35 SeitenQ053 Wegman 2016Heinz PeterNoch keine Bewertungen
- Assignment Usol 2016-2017 PGDSTDokument20 SeitenAssignment Usol 2016-2017 PGDSTpromilaNoch keine Bewertungen
- 1 - BBA - Probability and Statistics - Week-1Dokument36 Seiten1 - BBA - Probability and Statistics - Week-1miriNoch keine Bewertungen
- ML 43 Recruitment Selection and Induction Practice Ilm Assessment GuidanceDokument12 SeitenML 43 Recruitment Selection and Induction Practice Ilm Assessment GuidanceAhmed UzairNoch keine Bewertungen
- Ce223l FW9 e 3Dokument4 SeitenCe223l FW9 e 3ChristianLloyddeLeonNoch keine Bewertungen
- Hurley, Ryan2012 - News Aggregation and Content DifferenceDokument20 SeitenHurley, Ryan2012 - News Aggregation and Content DifferenceGilda BBTTNoch keine Bewertungen
- Bfile: Ch01, Chapter 1: The Role of Marketing Research in Management Decision MakingDokument8 SeitenBfile: Ch01, Chapter 1: The Role of Marketing Research in Management Decision MakingOumaïma M'nounyNoch keine Bewertungen
- Envy, CWB, and Leadership Moderation in Public vs Private OrgsDokument8 SeitenEnvy, CWB, and Leadership Moderation in Public vs Private OrgsAdroit WriterNoch keine Bewertungen
- SLK R10 Week 1Dokument30 SeitenSLK R10 Week 1Pikolo PabloNoch keine Bewertungen
- EPRI Aging Power Cable Maintenance Guideline 1024044Dokument244 SeitenEPRI Aging Power Cable Maintenance Guideline 1024044sulemankhalid100% (2)
- ASTZM E1476-97 Metals Sorting Guide PDFDokument12 SeitenASTZM E1476-97 Metals Sorting Guide PDFKewell LimNoch keine Bewertungen
- Research)Dokument48 SeitenResearch)Isaack MgeniNoch keine Bewertungen
- Task 4Dokument15 SeitenTask 4api-355694232Noch keine Bewertungen
- Sampling and Sample DistributionDokument22 SeitenSampling and Sample DistributionMitika MahajanNoch keine Bewertungen
- Mixed Methods Research: Integrating Qualitative and Quantitative MethodsDokument52 SeitenMixed Methods Research: Integrating Qualitative and Quantitative MethodsShazura ShaariNoch keine Bewertungen
- ECA5103 Chp1Dokument19 SeitenECA5103 Chp1JonathanChanNoch keine Bewertungen
- BH Log ProcedureDokument9 SeitenBH Log ProcedureMohammed Zuber InamdarNoch keine Bewertungen
- 0580 w06 QP 1Dokument8 Seiten0580 w06 QP 1lepton1973Noch keine Bewertungen
- Matthes, Jorg - Framing PoliticsDokument15 SeitenMatthes, Jorg - Framing PoliticsJoaquin PomboNoch keine Bewertungen
- CHAPTER III Sampling and Sampling DistributionDokument48 SeitenCHAPTER III Sampling and Sampling DistributionAldrin Dela CruzNoch keine Bewertungen
- Applied Unit 1 Statistical Sampling QPDokument3 SeitenApplied Unit 1 Statistical Sampling QPnareshbalajiNoch keine Bewertungen
- StatisticsDokument22 SeitenStatisticsbenjamin212Noch keine Bewertungen
- 2023-10-17 Letter To J Dinning From CPPIBDokument3 Seiten2023-10-17 Letter To J Dinning From CPPIBAdam ToyNoch keine Bewertungen
- Action Research - Appraising ProposalsDokument36 SeitenAction Research - Appraising ProposalsLiana ZenNoch keine Bewertungen
- Time Out: Lecture Timings and Lecture EffectivenessDokument17 SeitenTime Out: Lecture Timings and Lecture EffectivenessRadhika KhetanNoch keine Bewertungen
- Research MethodsDokument41 SeitenResearch Methodsharismoten12Noch keine Bewertungen
- Study Skill: Psychology Test Administration at CollegeDokument8 SeitenStudy Skill: Psychology Test Administration at Collegebharathi mvpaNoch keine Bewertungen
- Research Design, Methods & EthicsDokument4 SeitenResearch Design, Methods & EthicsAnna Graziela De Leon AujeroNoch keine Bewertungen
- Iso 13485Dokument2 SeitenIso 13485InnoviaNoch keine Bewertungen
- Stuvia 509464 St104a Statistics 1 Exams With Commentaries 2011 2018Dokument503 SeitenStuvia 509464 St104a Statistics 1 Exams With Commentaries 2011 2018Aruzhan YerbolatovaNoch keine Bewertungen