Das könnte Ihnen auch gefallen
- Kim v. Tinder ComplaintDokument15 SeitenKim v. Tinder ComplaintRussell BrandomNoch keine Bewertungen
- Kim v. Tinder ComplaintDokument15 SeitenKim v. Tinder ComplaintRussell BrandomNoch keine Bewertungen
- ITC 215: Data Structure and Algorithm Module ObjectivesDokument3 SeitenITC 215: Data Structure and Algorithm Module Objectiveskarthikeyan50700HRNoch keine Bewertungen
- BlackBerry V FacebookDokument117 SeitenBlackBerry V FacebookRussell Brandom75% (4)
- College Website PHPDokument19 SeitenCollege Website PHPRavi Shankar K B76% (59)
- Code of Conduct at Pizza HutDokument2 SeitenCode of Conduct at Pizza HutAdeel Chaudhary0% (1)
- Language As IdeologyDokument26 SeitenLanguage As IdeologyAlcione Gonçalves Campos100% (2)
- Grok System Design InterviewDokument157 SeitenGrok System Design Interviewaragamiyamiko100% (2)
- Critical Reading As ReasoningDokument18 SeitenCritical Reading As ReasoningKyle Velasquez100% (3)
- US v. SnapchatDokument7 SeitenUS v. SnapchatRussell BrandomNoch keine Bewertungen
- PLAXIS Tutorial ManualDokument124 SeitenPLAXIS Tutorial ManualPeteris Skels100% (2)
- Electronics QuestionnaireDokument4 SeitenElectronics QuestionnaireRenie FedericoNoch keine Bewertungen
- Grok System Design InterviewDokument163 SeitenGrok System Design InterviewCarlos Rojas100% (3)
- Bias Goggles: Exploring The Bias of Web Domains Through The Eyes of UsersDokument4 SeitenBias Goggles: Exploring The Bias of Web Domains Through The Eyes of UsersPanagiotis PapadakosNoch keine Bewertungen
- Bias Goggles: Graph-Based Computation of The Bias of Web Domains Through The Eyes of UsersDokument14 SeitenBias Goggles: Graph-Based Computation of The Bias of Web Domains Through The Eyes of UsersPanagiotis PapadakosNoch keine Bewertungen
- WelcomeDokument19 SeitenWelcomevalmiki vickyNoch keine Bewertungen
- NSumsDokument9 SeitenNSumsaaes2Noch keine Bewertungen
- Papadakos 2020 Bias 2020 Demo PDFDokument4 SeitenPapadakos 2020 Bias 2020 Demo PDFPanagiotis PapadakosNoch keine Bewertungen
- Issuecrawlerscenarios UseDokument6 SeitenIssuecrawlerscenarios UsehjdbpNoch keine Bewertungen
- Lecture 5-c Further ReadingsDokument11 SeitenLecture 5-c Further ReadingsFrank WanderiNoch keine Bewertungen
- Petteri Huuhka Google PaperDokument13 SeitenPetteri Huuhka Google PaperZ. WenNoch keine Bewertungen
- Ranking Clustered Keyword Search On Semi Structured DataDokument7 SeitenRanking Clustered Keyword Search On Semi Structured DataEditor IJRITCCNoch keine Bewertungen
- Papadakos 2020 Ecir Bias GogglesDokument14 SeitenPapadakos 2020 Ecir Bias GogglesPanagiotis PapadakosNoch keine Bewertungen
- Web Crawler Research PaperDokument6 SeitenWeb Crawler Research Paperfvf8zrn0100% (1)
- DSE 3 Unit 3Dokument4 SeitenDSE 3 Unit 3Priyaranjan SorenNoch keine Bewertungen
- Database System ConceptDokument33 SeitenDatabase System ConceptDisha SharmaNoch keine Bewertungen
- Web Scraping by Using RDokument3 SeitenWeb Scraping by Using RVijay ChandarNoch keine Bewertungen
- DataminingDokument21 SeitenDatamining21BCS119 S. DeepakNoch keine Bewertungen
- IR Unit 3Dokument47 SeitenIR Unit 3jaganbecsNoch keine Bewertungen
- Boncella Competitive Intelligence and The Web 2003Dokument16 SeitenBoncella Competitive Intelligence and The Web 2003Zakaria DhissiNoch keine Bewertungen
- Saint 03 HeaderDokument6 SeitenSaint 03 Headerapi-3762303Noch keine Bewertungen
- Interactive Query and Search in Semistructured Databases: Roy Goldman, Jennifer WidomDokument7 SeitenInteractive Query and Search in Semistructured Databases: Roy Goldman, Jennifer WidompostscriptNoch keine Bewertungen
- Predicting The Brand Popularity From The Brand MetadataDokument14 SeitenPredicting The Brand Popularity From The Brand MetadataJanie RêNoch keine Bewertungen
- LinkedIn Case StudyDokument11 SeitenLinkedIn Case StudyKumar Ashish Gupta100% (1)
- Discovery of Interesting Usage Patterns From Web Data: 1 Introduction and BackgroundDokument20 SeitenDiscovery of Interesting Usage Patterns From Web Data: 1 Introduction and BackgroundhcamilogaNoch keine Bewertungen
- Unit4 Assignment1 2023 NewTemplateDokument5 SeitenUnit4 Assignment1 2023 NewTemplateyoonNoch keine Bewertungen
- Unit 2 mk05Dokument5 SeitenUnit 2 mk05mohd ahsanNoch keine Bewertungen
- MEM 6120 Assignment 4Dokument23 SeitenMEM 6120 Assignment 4edi jayadiNoch keine Bewertungen
- An Approach To Confidence Based Page Ranking For User Oriented Web SearchDokument6 SeitenAn Approach To Confidence Based Page Ranking For User Oriented Web SearchAditya KulkarniNoch keine Bewertungen
- Pagerank ThesisDokument6 SeitenPagerank Thesisfjnfted4100% (2)
- An Enhanced Technique For Text Retrieval in Web SearchDokument5 SeitenAn Enhanced Technique For Text Retrieval in Web SearchInternational Journal of Application or Innovation in Engineering & ManagementNoch keine Bewertungen
- 1.1 Web MiningDokument16 Seiten1.1 Web MiningsonarkarNoch keine Bewertungen
- A Survey On Web Page Segmentation and Its Applications: U.Arundhathi, V.Sneha Latha, D.Grace PriscillaDokument6 SeitenA Survey On Web Page Segmentation and Its Applications: U.Arundhathi, V.Sneha Latha, D.Grace PriscillaIjesat JournalNoch keine Bewertungen
- IJRPR2077Dokument7 SeitenIJRPR2077Abhishek palNoch keine Bewertungen
- Social Network Analysis of F/OSS Development CommunitiesDokument12 SeitenSocial Network Analysis of F/OSS Development Communitiessreenu_pesNoch keine Bewertungen
- Educative System Design Part1Dokument33 SeitenEducative System Design Part1Shivam JaiswalNoch keine Bewertungen
- CODENADokument9 SeitenCODENAFerman HaciyevNoch keine Bewertungen
- Backlinko Large Scale Page Speed Analysis MethodsDokument9 SeitenBacklinko Large Scale Page Speed Analysis MethodsViorelMocanuNoch keine Bewertungen
- 10SDADokument49 Seiten10SDAAshutosh SrivastavaNoch keine Bewertungen
- Group 4 Hand OutDokument5 SeitenGroup 4 Hand OutAngel Preciosa DelsocoraNoch keine Bewertungen
- How Large Is The WebDokument19 SeitenHow Large Is The WebStefanos AnastasiadisNoch keine Bewertungen
- Guidance On Technical DiscussionsDokument2 SeitenGuidance On Technical Discussionskranti29Noch keine Bewertungen
- Online Visualization of Bibliography Using Visualization TechniquesDokument43 SeitenOnline Visualization of Bibliography Using Visualization TechniquessuntmNoch keine Bewertungen
- Google Interview Warmup QuestionsDokument15 SeitenGoogle Interview Warmup QuestionsGhumaNoch keine Bewertungen
- Evaluation of Jstor DFR: Heuristic EvaluationDokument32 SeitenEvaluation of Jstor DFR: Heuristic Evaluationfoxshee105Noch keine Bewertungen
- Discovering Semantic Similarity Using Web Documents and ContextDokument5 SeitenDiscovering Semantic Similarity Using Web Documents and ContextsamanNoch keine Bewertungen
- Personalized Image Search Using Complex Multiple Words-Based QueriesDokument6 SeitenPersonalized Image Search Using Complex Multiple Words-Based QueriesmayurNoch keine Bewertungen
- Lecture Notes On Database Management SystemDokument10 SeitenLecture Notes On Database Management Systemkamalpreetkaur_mbaNoch keine Bewertungen
- Search Engine Optimization - Using Data Mining ApproachDokument5 SeitenSearch Engine Optimization - Using Data Mining ApproachInternational Journal of Application or Innovation in Engineering & ManagementNoch keine Bewertungen
- Web Page Similarity Draft FinalDokument71 SeitenWeb Page Similarity Draft FinalKALAINoch keine Bewertungen
- Mini ProjectDokument3 SeitenMini ProjectABHISHEK GUPTANoch keine Bewertungen
- Dynamic Ranking Algorithm Using Multi Graph TechnologyDokument9 SeitenDynamic Ranking Algorithm Using Multi Graph TechnologyRachel WheelerNoch keine Bewertungen
- Nursing Informatics Assignment Website AnalysisDokument6 SeitenNursing Informatics Assignment Website AnalysisJopaii TanakaNoch keine Bewertungen
- Unit-1 WADDokument13 SeitenUnit-1 WADshrutiNoch keine Bewertungen
- The International Journal of Engineering and Science (The IJES)Dokument5 SeitenThe International Journal of Engineering and Science (The IJES)theijesNoch keine Bewertungen
- Expert Performance Indexing in SQL Server 2019: Toward Faster Results and Lower MaintenanceVon EverandExpert Performance Indexing in SQL Server 2019: Toward Faster Results and Lower MaintenanceNoch keine Bewertungen
- Data Structures Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesVon EverandData Structures Interview Questions You'll Most Likely Be Asked: Job Interview Questions SeriesNoch keine Bewertungen
- Getting Structured Data from the Internet: Running Web Crawlers/Scrapers on a Big Data Production ScaleVon EverandGetting Structured Data from the Internet: Running Web Crawlers/Scrapers on a Big Data Production ScaleNoch keine Bewertungen
- Keep Big Tech Out of Finance Act: Discussion DraftDokument7 SeitenKeep Big Tech Out of Finance Act: Discussion DraftRyan Todd100% (3)
- Sprint v. AT&T TRODokument3 SeitenSprint v. AT&T TRORussell BrandomNoch keine Bewertungen
- US V AT&T Notice of AppealDokument2 SeitenUS V AT&T Notice of AppealRussell BrandomNoch keine Bewertungen
- In-Car Facial Recognition TestsDokument76 SeitenIn-Car Facial Recognition TestsRussell BrandomNoch keine Bewertungen
- Facebook Stay DeniedDokument4 SeitenFacebook Stay DeniedRussell BrandomNoch keine Bewertungen
- US v. Snapchat User 'Xannieprincess'Dokument18 SeitenUS v. Snapchat User 'Xannieprincess'Russell BrandomNoch keine Bewertungen
- Free Speech Systems v. MenzelDokument6 SeitenFree Speech Systems v. MenzelRussell BrandomNoch keine Bewertungen
- Kurzynski Plea AgreementDokument14 SeitenKurzynski Plea AgreementRussell BrandomNoch keine Bewertungen
- Moskowitz v. SungameDokument11 SeitenMoskowitz v. SungameRussell BrandomNoch keine Bewertungen
- Protective OrderDokument19 SeitenProtective OrderRussell BrandomNoch keine Bewertungen
- V. The French RepublicDokument13 SeitenV. The French RepublicRussell BrandomNoch keine Bewertungen
- Facebook Facial Rec OrderDokument10 SeitenFacebook Facial Rec OrderRussell BrandomNoch keine Bewertungen
- Affidavit To Apple in Wal-Mart Trade Secrets CaseDokument16 SeitenAffidavit To Apple in Wal-Mart Trade Secrets CaseRussell BrandomNoch keine Bewertungen
- Letter To Axon AI Ethics BoardDokument3 SeitenLetter To Axon AI Ethics BoardRussell BrandomNoch keine Bewertungen
- Whatsapp Trap Trace OrderDokument2 SeitenWhatsapp Trap Trace OrderRussell BrandomNoch keine Bewertungen
- DC Schools Timesheet FraudDokument19 SeitenDC Schools Timesheet FraudRussell BrandomNoch keine Bewertungen
- Data Sharing Report - Sacramento Police DepartmentDokument19 SeitenData Sharing Report - Sacramento Police DepartmentRussell BrandomNoch keine Bewertungen
- Rep. McNerney Letter To Intel Arm AMDDokument2 SeitenRep. McNerney Letter To Intel Arm AMDRussell BrandomNoch keine Bewertungen
- Coinbase & IRSDokument14 SeitenCoinbase & IRSTechCrunch100% (2)
- US v. Levashov IndictmentDokument34 SeitenUS v. Levashov IndictmentRussell BrandomNoch keine Bewertungen
- Clarke Gmail AffidavitDokument18 SeitenClarke Gmail AffidavitRussell BrandomNoch keine Bewertungen
- In The Matter of Information Associated With 15 Email AddressesDokument13 SeitenIn The Matter of Information Associated With 15 Email AddressesRussell BrandomNoch keine Bewertungen
- Grumpy Cat LawsuitDokument26 SeitenGrumpy Cat LawsuitchrisfuhrmeisterNoch keine Bewertungen
- Kadar Search WarrantDokument21 SeitenKadar Search WarrantRussell BrandomNoch keine Bewertungen
- 2703 (D) OrdersDokument2 Seiten2703 (D) OrdersRussell BrandomNoch keine Bewertungen
- Mindmup Group-2Dokument10 SeitenMindmup Group-2api-271772521Noch keine Bewertungen
- Tomtom Device ForensicsDokument5 SeitenTomtom Device ForensicsSwaroop WaghadeNoch keine Bewertungen
- List of ComponentsDokument2 SeitenList of ComponentsRainwin TamayoNoch keine Bewertungen
- B2B ApiDokument350 SeitenB2B ApiratnavelpNoch keine Bewertungen
- Smart Bell Notification System Using IoTDokument3 SeitenSmart Bell Notification System Using IoTTony StankNoch keine Bewertungen
- Binary PDFDokument13 SeitenBinary PDFbyprasadNoch keine Bewertungen
- 218477these Stufy of An in Vehicule Infotainement SystemDokument79 Seiten218477these Stufy of An in Vehicule Infotainement SystemKhaled GharbiNoch keine Bewertungen
- BS en 50160 2007Dokument24 SeitenBS en 50160 2007Pepe Eulogio OrtízNoch keine Bewertungen
- SchoolofLifeSciencesAdmissionOpen2021-2022Dokument4 SeitenSchoolofLifeSciencesAdmissionOpen2021-2022Amiruddin RafiudeenNoch keine Bewertungen
- On Tap Water Filter System InstructionsDokument48 SeitenOn Tap Water Filter System InstructionsFilipa FigueiredoNoch keine Bewertungen
- Scoring Rubric For Oral Presentations Total Points ScoreDokument2 SeitenScoring Rubric For Oral Presentations Total Points ScoreLezia pagdonsolanNoch keine Bewertungen
- Nitya Parayana Slokas MalayalamDokument3 SeitenNitya Parayana Slokas MalayalamGopakumar NairNoch keine Bewertungen
- LCD panel and module replacement parts for saleDokument1 SeiteLCD panel and module replacement parts for saleValeria bolañosNoch keine Bewertungen
- ARK Survival 600 Player Level CapDokument16 SeitenARK Survival 600 Player Level CapArcTrooper210Noch keine Bewertungen
- I2C Bus ManualDokument51 SeitenI2C Bus Manualapi-26349602100% (6)
- John Deere 125 HP PDFDokument2 SeitenJohn Deere 125 HP PDFJulio TovarNoch keine Bewertungen
- 0100CT1901 Sec-23 102520202Dokument120 Seiten0100CT1901 Sec-23 102520202Chandra SekaranNoch keine Bewertungen
- DYNAenergetics 2.875 PA Auto-Vent Firing Head Field Assembly ProcedureDokument7 SeitenDYNAenergetics 2.875 PA Auto-Vent Firing Head Field Assembly ProceduremahsaNoch keine Bewertungen
- VAHAN SERVICE - User ManualDokument30 SeitenVAHAN SERVICE - User ManualGURBACHAN SINGH ChouhanNoch keine Bewertungen
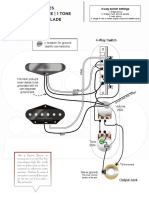
- 4-way switch wiring diagram for a 2 pickup guitarDokument1 Seite4-way switch wiring diagram for a 2 pickup guitarNebojša JoksimovićNoch keine Bewertungen
- 29 KprogDokument582 Seiten29 KprogMike MorrowNoch keine Bewertungen
- Gta Namaste America Cheat CodesDokument4 SeitenGta Namaste America Cheat CodesGaurav PathakNoch keine Bewertungen
- Basic Functions of A Computer SystemDokument3 SeitenBasic Functions of A Computer SystemAlanlovely Arazaampong AmosNoch keine Bewertungen
- Pyxis SPT HepDokument597 SeitenPyxis SPT HepanithaarumallaNoch keine Bewertungen