Das könnte Ihnen auch gefallen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (120)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Skills in Mathematics Integral Calculus For JEE Main and Advanced 2022Dokument319 SeitenSkills in Mathematics Integral Calculus For JEE Main and Advanced 2022Harshil Nagwani100% (3)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (73)
- Chapter 2Dokument36 SeitenChapter 2Shaine C. SantosNoch keine Bewertungen
- Heath y Carter 67Dokument18 SeitenHeath y Carter 67Simon HenriquezNoch keine Bewertungen
- Hungarian Algorithm For Excel - VBADokument9 SeitenHungarian Algorithm For Excel - VBAYinghui LiuNoch keine Bewertungen
- Sample Physics Lab ReportDokument4 SeitenSample Physics Lab ReportTaehyun ChangNoch keine Bewertungen
- Step 1) Calculate The Pressure Derivative Functions of The Well-Test Data (Tabulated in Table 4.11)Dokument13 SeitenStep 1) Calculate The Pressure Derivative Functions of The Well-Test Data (Tabulated in Table 4.11)jonathan_leal09Noch keine Bewertungen
- Hybrid Compressed Hash Based Homomorphic AB Encryption Algorithm For Security of Data in The Cloud EnvironmentDokument9 SeitenHybrid Compressed Hash Based Homomorphic AB Encryption Algorithm For Security of Data in The Cloud EnvironmentAnonymous lPvvgiQjRNoch keine Bewertungen
- Regression Based Sales Data Forecasting For Predicting The Business PerformanceDokument5 SeitenRegression Based Sales Data Forecasting For Predicting The Business PerformanceAnonymous lPvvgiQjRNoch keine Bewertungen
- Sentiment Classification Using Supervised and Unsupervised ApproachDokument5 SeitenSentiment Classification Using Supervised and Unsupervised ApproachAnonymous lPvvgiQjRNoch keine Bewertungen
- Study On Visco-Elastic Fluid and Heat Radiation On The Flow of Walter's LiquidDokument6 SeitenStudy On Visco-Elastic Fluid and Heat Radiation On The Flow of Walter's LiquidAnonymous lPvvgiQjRNoch keine Bewertungen
- Attitude of Secondary School Teachers Towards The Use of ICT in Teaching Learning ProcessDokument4 SeitenAttitude of Secondary School Teachers Towards The Use of ICT in Teaching Learning ProcessAnonymous lPvvgiQjR100% (1)
- Implementation of Modified Lifting and Flipping Plans in D.W.T Architecture For Better Performance.Dokument5 SeitenImplementation of Modified Lifting and Flipping Plans in D.W.T Architecture For Better Performance.Anonymous lPvvgiQjRNoch keine Bewertungen
- A Review On Facial Expression Recognition TechniquesDokument8 SeitenA Review On Facial Expression Recognition TechniquesAnonymous lPvvgiQjRNoch keine Bewertungen
- Engaging Students in Open Source Software For Learning Professional Skills in AcademiaDokument7 SeitenEngaging Students in Open Source Software For Learning Professional Skills in AcademiaAnonymous lPvvgiQjRNoch keine Bewertungen
- Sine Cosine Based Algorithm For Data ClusteringDokument5 SeitenSine Cosine Based Algorithm For Data ClusteringAnonymous lPvvgiQjRNoch keine Bewertungen
- A Review On Distributed Denial of Service Attack On Network TrafficDokument6 SeitenA Review On Distributed Denial of Service Attack On Network TrafficAnonymous lPvvgiQjRNoch keine Bewertungen
- VHDL Implementation of 128 Bit Pipelined Blowfish AlgorithmDokument5 SeitenVHDL Implementation of 128 Bit Pipelined Blowfish AlgorithmAnonymous lPvvgiQjRNoch keine Bewertungen
- An Enhanced Cloud-Based Secure Authentication (Ecsa) Protocol Suite For Prevention of Denial-Of-Service (Dos) AttacksDokument12 SeitenAn Enhanced Cloud-Based Secure Authentication (Ecsa) Protocol Suite For Prevention of Denial-Of-Service (Dos) AttacksAnonymous lPvvgiQjRNoch keine Bewertungen
- 90 1512803801 - 09-12-2017 PDFDokument3 Seiten90 1512803801 - 09-12-2017 PDFAnonymous lPvvgiQjRNoch keine Bewertungen
- 89 1512802578 - 09-12-2017 PDFDokument3 Seiten89 1512802578 - 09-12-2017 PDFAnonymous lPvvgiQjRNoch keine Bewertungen
- 82 1512498557 - 05-12-2017 PDFDokument3 Seiten82 1512498557 - 05-12-2017 PDFAnonymous lPvvgiQjRNoch keine Bewertungen
- Steganography-A Powerful Web Security Tool For Data TransmissionDokument10 SeitenSteganography-A Powerful Web Security Tool For Data TransmissionAnonymous lPvvgiQjRNoch keine Bewertungen
- 84 1512499393 - 05-12-2017 PDFDokument10 Seiten84 1512499393 - 05-12-2017 PDFAnonymous lPvvgiQjRNoch keine Bewertungen
- Seamless Handover of Video Streamingin 4G Wireless Network: Dr. S. M. Koli Anand B. RautDokument5 SeitenSeamless Handover of Video Streamingin 4G Wireless Network: Dr. S. M. Koli Anand B. RautAnonymous lPvvgiQjRNoch keine Bewertungen
- Comparative Study of Various Image Processing Tools With Bigdata Images in Parallel EnvironmentDokument5 SeitenComparative Study of Various Image Processing Tools With Bigdata Images in Parallel EnvironmentAnonymous lPvvgiQjRNoch keine Bewertungen
- Demonstration Instrument: A Blow and Outcome On The Indian PopulaceDokument4 SeitenDemonstration Instrument: A Blow and Outcome On The Indian PopulaceAnonymous lPvvgiQjRNoch keine Bewertungen
- 79 1512458251 - 05-12-2017 PDFDokument7 Seiten79 1512458251 - 05-12-2017 PDFAnonymous lPvvgiQjRNoch keine Bewertungen
- Enhance Data Security Protection For Data Sharing in Cloud Storage SystemDokument4 SeitenEnhance Data Security Protection For Data Sharing in Cloud Storage SystemAnonymous lPvvgiQjRNoch keine Bewertungen
- Assessment of Perform Achieve and Trade (Pat), Cycle in India and Conceptualization of Its Future PerformanceDokument10 SeitenAssessment of Perform Achieve and Trade (Pat), Cycle in India and Conceptualization of Its Future PerformanceAnonymous lPvvgiQjRNoch keine Bewertungen
- Survey On: Multimedia Content Protection Using Cloud: A. M. ChavanDokument3 SeitenSurvey On: Multimedia Content Protection Using Cloud: A. M. ChavanAnonymous lPvvgiQjRNoch keine Bewertungen
- 77 1512289526 - 03-12-2017 PDFDokument10 Seiten77 1512289526 - 03-12-2017 PDFAnonymous lPvvgiQjRNoch keine Bewertungen
- Routing Protocols For Large-Scale Wireless Sensor Networks: A ReviewDokument10 SeitenRouting Protocols For Large-Scale Wireless Sensor Networks: A ReviewAnonymous lPvvgiQjRNoch keine Bewertungen
- 78 1512370802 - 04-12-2017 PDFDokument3 Seiten78 1512370802 - 04-12-2017 PDFAnonymous lPvvgiQjRNoch keine Bewertungen
- Attribute Reduction For Credit Evaluation Using Rough Set ApproachDokument4 SeitenAttribute Reduction For Credit Evaluation Using Rough Set ApproachAnonymous lPvvgiQjRNoch keine Bewertungen
- Various Sequence Classification Mechanisms For Knowledge DiscoveryDokument4 SeitenVarious Sequence Classification Mechanisms For Knowledge DiscoveryAnonymous lPvvgiQjRNoch keine Bewertungen
- Engineering Solutions 11.0 User GuideDokument2.056 SeitenEngineering Solutions 11.0 User GuideNeimar Soares Silva100% (1)
- Prelim FinalDokument440 SeitenPrelim FinalRon AquinoNoch keine Bewertungen
- ManualDokument376 SeitenManualYoseph BirruNoch keine Bewertungen
- Lab Report 1Dokument2 SeitenLab Report 1api-249188694Noch keine Bewertungen
- Lesson Plan in Mathematics 10 I. Weekly Objectives: Voice RelayDokument6 SeitenLesson Plan in Mathematics 10 I. Weekly Objectives: Voice RelayMark Kevin GeraldezNoch keine Bewertungen
- For Integral Representations For Analytic Functions Cauchy Integral FormulaDokument7 SeitenFor Integral Representations For Analytic Functions Cauchy Integral Formulasiddh_kec2003Noch keine Bewertungen
- ST Performance Task g9 MathDokument2 SeitenST Performance Task g9 MathJessan NeriNoch keine Bewertungen
- Capillary Pressure Brooks and Corey Type CurveDokument12 SeitenCapillary Pressure Brooks and Corey Type CurveSadiq KhanNoch keine Bewertungen
- Gamma and Beta Function - Spring 21-22Dokument23 SeitenGamma and Beta Function - Spring 21-22Jamiul HasanNoch keine Bewertungen
- Reversed CurvesDokument7 SeitenReversed CurvesBenidick Santos BernardinoNoch keine Bewertungen
- CodeVisionAVR Revision History 20051208Dokument20 SeitenCodeVisionAVR Revision History 20051208letanbaospkt06Noch keine Bewertungen
- Tybsc - Physics Applied Component Computer Science 1Dokument12 SeitenTybsc - Physics Applied Component Computer Science 1shivNoch keine Bewertungen
- Discrete Maths 103 124Dokument22 SeitenDiscrete Maths 103 124Bamdeb DeyNoch keine Bewertungen
- ABSTRACTDokument41 SeitenABSTRACTSaidhaNoch keine Bewertungen
- Latest Syllabus PDFDokument74 SeitenLatest Syllabus PDFsmit shahNoch keine Bewertungen
- Parametric Versus Non Parametric StatisticsDokument19 SeitenParametric Versus Non Parametric Statisticsمهنوش جوادی پورفرNoch keine Bewertungen
- Nanoantenna Directivity and EnhancementDokument4 SeitenNanoantenna Directivity and EnhancementRitesh kumar NayakNoch keine Bewertungen
- Intro MUSSVDokument4 SeitenIntro MUSSVMohammad Naser HashemniaNoch keine Bewertungen
- Algebraic Geometry - Van Der WaerdenDokument251 SeitenAlgebraic Geometry - Van Der Waerdenandrei129Noch keine Bewertungen
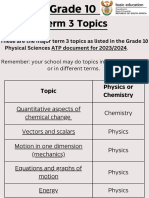
- Grade 10 Term 3 TopicsDokument10 SeitenGrade 10 Term 3 TopicsOwamiirh RsaNoch keine Bewertungen
- Mathematics: Quarter 2 - Module 11: Dividing Decimal With Up To 2 Decimal PlacesDokument9 SeitenMathematics: Quarter 2 - Module 11: Dividing Decimal With Up To 2 Decimal PlaceszytwnklNoch keine Bewertungen
- Math Mid Sem 1 Kiit PaperDokument1 SeiteMath Mid Sem 1 Kiit PapersellyNoch keine Bewertungen
- Linear Systems With Generalized Linear Phase Systems With Linear Phase Generalized Linear PhaseDokument12 SeitenLinear Systems With Generalized Linear Phase Systems With Linear Phase Generalized Linear PhaseAbdullah BilalNoch keine Bewertungen
- A Lesson in Formal LogicDokument8 SeitenA Lesson in Formal LogicJstevens035Noch keine Bewertungen