Das könnte Ihnen auch gefallen
- Role of Statistics in EngineeringDokument17 SeitenRole of Statistics in EngineeringOngNoch keine Bewertungen
- G Power CalculationDokument9 SeitenG Power CalculationbernutNoch keine Bewertungen
- 2015CEP2096 - LAB 8 Parking Study PDFDokument8 Seiten2015CEP2096 - LAB 8 Parking Study PDFMohit KohliNoch keine Bewertungen
- Sensitivity Analysis in Statistical Decision TheoryDokument19 SeitenSensitivity Analysis in Statistical Decision TheoryyackyesNoch keine Bewertungen
- Sample Size in Factor Analysis: Why Size Matters Helen C Lingard and Steve RowlinsonDokument6 SeitenSample Size in Factor Analysis: Why Size Matters Helen C Lingard and Steve Rowlinsonmanjunatha tNoch keine Bewertungen
- Economics 2018 4Dokument33 SeitenEconomics 2018 4Hufzi KhanNoch keine Bewertungen
- Introduction To Statistics and Data AnalysisDokument108 SeitenIntroduction To Statistics and Data AnalysisVINCENT PAOLO RAMOSNoch keine Bewertungen
- Selection of A Representative SampleDokument15 SeitenSelection of A Representative SampleEben EzerNoch keine Bewertungen
- A Large Scale Benchmark For Individual Treatment Effect Prediction and UpliftDokument28 SeitenA Large Scale Benchmark For Individual Treatment Effect Prediction and Uplifthai wangNoch keine Bewertungen
- Electronics Lab EEC-4215Dokument138 SeitenElectronics Lab EEC-4215Virendra KumarNoch keine Bewertungen
- Project 2021Dokument12 SeitenProject 2021Melvin EstolanoNoch keine Bewertungen
- Bias, Precision and AccuracyDokument15 SeitenBias, Precision and Accuracyadrian0149Noch keine Bewertungen
- Increasing Statistical Power in Mediational Model Without Increasing Sample SizeDokument24 SeitenIncreasing Statistical Power in Mediational Model Without Increasing Sample SizeezazpsychologistNoch keine Bewertungen
- Statistics in Medicine - 2019 - Morris - Using Simulation Studies To Evaluate Statistical MethodsDokument29 SeitenStatistics in Medicine - 2019 - Morris - Using Simulation Studies To Evaluate Statistical MethodsDipro MondalNoch keine Bewertungen
- Chapter 4Dokument90 SeitenChapter 4gebreslassie gereziherNoch keine Bewertungen
- Practical StatisticsDokument26 SeitenPractical Statisticssunilverma2010Noch keine Bewertungen
- Effect Size Calculation in Power Estimation For The Chi-Square Test of Preliminary Data in Different StudiesDokument13 SeitenEffect Size Calculation in Power Estimation For The Chi-Square Test of Preliminary Data in Different StudiesSEP-PublisherNoch keine Bewertungen
- Li Lan (2010)Dokument12 SeitenLi Lan (2010)MUC kediriNoch keine Bewertungen
- Use of Statistical Process Control (SPC) Versus Traditional Statistical Methods in Personal Care ApplicationsDokument6 SeitenUse of Statistical Process Control (SPC) Versus Traditional Statistical Methods in Personal Care Applicationsusdcck25Noch keine Bewertungen
- Cochran 1947 Some Consequences When The Assumptions For The Analysis of Variance Are Not SatisfiedDokument18 SeitenCochran 1947 Some Consequences When The Assumptions For The Analysis of Variance Are Not SatisfiedlhjkpNoch keine Bewertungen
- G - Power GuideDokument86 SeitenG - Power GuidebigkexNoch keine Bewertungen
- Wolkite University College of Computing and Informatics Department of Information SystemsDokument11 SeitenWolkite University College of Computing and Informatics Department of Information SystemsAmanuel KebedeNoch keine Bewertungen
- 1995 Practical Experiments in StatisticsDokument7 Seiten1995 Practical Experiments in StatisticsMiguel AlvaradoNoch keine Bewertungen
- Topic 1 TheRoleofStatisticsinEngineering JayraldB - Acera BSME2A PDFDokument36 SeitenTopic 1 TheRoleofStatisticsinEngineering JayraldB - Acera BSME2A PDFRuel Japhet BitoyNoch keine Bewertungen
- Six Sigma Mission: Statistical Sample Population ParameterDokument4 SeitenSix Sigma Mission: Statistical Sample Population ParameterFaheem HussainNoch keine Bewertungen
- The Engineering Method and Statistical 2Dokument3 SeitenThe Engineering Method and Statistical 2Veil ShitNoch keine Bewertungen
- Tuo and Wu 2014 Kennedy and O'Hagan 2001: Submitted To The Annals of StatisticsDokument24 SeitenTuo and Wu 2014 Kennedy and O'Hagan 2001: Submitted To The Annals of Statisticsjuan cota maodNoch keine Bewertungen
- Cosc2753 A1 MCDokument8 SeitenCosc2753 A1 MCHuy NguyenNoch keine Bewertungen
- Siu L. Chow Keywords: Associated Probability, Conditional Probability, Confidence-Interval EstimateDokument20 SeitenSiu L. Chow Keywords: Associated Probability, Conditional Probability, Confidence-Interval EstimateTammie Jo WalkerNoch keine Bewertungen
- Item Response Theory and Classical Test Theory: An Empirical Comparison of Their Item/person StatisticsDokument17 SeitenItem Response Theory and Classical Test Theory: An Empirical Comparison of Their Item/person StatisticsIlham FalaniNoch keine Bewertungen
- Chapter 1Dokument24 SeitenChapter 1hahoang33322Noch keine Bewertungen
- Statistical Model ValidationDokument3 SeitenStatistical Model ValidationRicardo AqpNoch keine Bewertungen
- Clear2024 MainDokument23 SeitenClear2024 MainTam T. LeNoch keine Bewertungen
- Bechhofer y Tamhane 1983 Design of Experiments For Comparing Treatments With A Control Tables of Optimal Allocations of ObservationsDokument10 SeitenBechhofer y Tamhane 1983 Design of Experiments For Comparing Treatments With A Control Tables of Optimal Allocations of ObservationsCarlos AndradeNoch keine Bewertungen
- ANOVA: A Paradigm For Low Power and Misleading Measures of Effect Size?stDokument28 SeitenANOVA: A Paradigm For Low Power and Misleading Measures of Effect Size?stGilmer Solis SánchezNoch keine Bewertungen
- Robust Individuals Control Chart For Exploratory AnalysisDokument16 SeitenRobust Individuals Control Chart For Exploratory AnalysisWong Chiong LiongNoch keine Bewertungen
- The International Journal of Biostatistics: An Introduction To Causal InferenceDokument62 SeitenThe International Journal of Biostatistics: An Introduction To Causal InferenceViswas ChhapolaNoch keine Bewertungen
- Some Practical Guidelines For Effective Sample Size DeterminationDokument7 SeitenSome Practical Guidelines For Effective Sample Size DeterminationhackenbergerNoch keine Bewertungen
- Final Ices 2 PaperDokument13 SeitenFinal Ices 2 PaperPrince RyanNoch keine Bewertungen
- Masaya Book StatisticsDokument460 SeitenMasaya Book StatisticsPanasheNoch keine Bewertungen
- Does Model-Free Forecasting Really Outperform The True Model?Dokument5 SeitenDoes Model-Free Forecasting Really Outperform The True Model?Peer TerNoch keine Bewertungen
- Sample Size Computations and Power Analysis With The SAS SystemDokument8 SeitenSample Size Computations and Power Analysis With The SAS SystemAhmad Abdullah Najjar100% (2)
- Chapter 1 Sta404Dokument13 SeitenChapter 1 Sta404ALISHA NYUWAN ENCHANANoch keine Bewertungen
- Analysis of VarianceDokument7 SeitenAnalysis of VarianceAYU SARASWATINoch keine Bewertungen
- ReportPractice1 Ayala, Hidalgo, VillarealDokument14 SeitenReportPractice1 Ayala, Hidalgo, VillarealPatricio VillarrealNoch keine Bewertungen
- Wiemer 2004Dokument6 SeitenWiemer 2004texto.sarlNoch keine Bewertungen
- Reed 2011Dokument17 SeitenReed 2011Uttam GolderNoch keine Bewertungen
- CHAPTER 1 TheoremDokument20 SeitenCHAPTER 1 Theoremhahoang33322Noch keine Bewertungen
- IBM SPSS Statistics 18 Part 2: Test of Significance: C S U, L ADokument19 SeitenIBM SPSS Statistics 18 Part 2: Test of Significance: C S U, L AAnand NilewarNoch keine Bewertungen
- Stat20023.Week 1 - Basic ConceptsDokument31 SeitenStat20023.Week 1 - Basic ConceptsRyan CortesNoch keine Bewertungen
- Hypothesis Tests For Principal Component Analysis When Variables Are StandardizedDokument20 SeitenHypothesis Tests For Principal Component Analysis When Variables Are StandardizedNikhilNoch keine Bewertungen
- MoffatDokument15 SeitenMoffatlucasf2606Noch keine Bewertungen
- Fuzzy Statistics PDFDokument41 SeitenFuzzy Statistics PDFS.GayathriNoch keine Bewertungen
- An Introduction To Robust Estimation With R FunctiDokument58 SeitenAn Introduction To Robust Estimation With R FunctiСелена СтанковићNoch keine Bewertungen
- 2017 Effective Statistical Methods For Big Data AnalyticsDokument20 Seiten2017 Effective Statistical Methods For Big Data AnalyticsnatskaNoch keine Bewertungen
- Random Math 1Dokument63 SeitenRandom Math 1Mert SEPETOĞLUNoch keine Bewertungen
- Chapter 1 Data and StatisticsDokument10 SeitenChapter 1 Data and Statisticslla096416Noch keine Bewertungen
- Validations ModelsDokument8 SeitenValidations ModelszaratechacanaNoch keine Bewertungen
- A Tour of Unsupervised Deep Learning For Medical Image AnalysisDokument29 SeitenA Tour of Unsupervised Deep Learning For Medical Image AnalysisLandon GrayNoch keine Bewertungen
- Norm Assum STARTDokument6 SeitenNorm Assum STARTLuis Eduardo Chávez SánchezNoch keine Bewertungen
- BA 06015 e Hybrid PDFDokument12 SeitenBA 06015 e Hybrid PDFomid123123123Noch keine Bewertungen
- Propeller Blade Shape Optimization For Efficiency ImprovementDokument13 SeitenPropeller Blade Shape Optimization For Efficiency ImprovementNurhayyan Halim RosidNoch keine Bewertungen
- Hydrodynamic Efficiency Improvement of The High Skew Propeller For The Underwater Vehicle Under Surface and Submerged ConditionsDokument2 SeitenHydrodynamic Efficiency Improvement of The High Skew Propeller For The Underwater Vehicle Under Surface and Submerged Conditionsomid123123123Noch keine Bewertungen
- Shipflow Tutorials - MotionsDokument6 SeitenShipflow Tutorials - Motionsomid123123123Noch keine Bewertungen
- Tech RoadmapDokument12 SeitenTech Roadmapomid123123123Noch keine Bewertungen
- Cheng2017 Critikal ThinkingDokument41 SeitenCheng2017 Critikal ThinkingAUNX CAMPUR-CAMPURNoch keine Bewertungen
- The Open Budget IndexDokument12 SeitenThe Open Budget IndexInternational Consortium on Governmental Financial ManagementNoch keine Bewertungen
- MARKETING RESEARCH THEORIES AND CONCEPTS - OutlineDokument104 SeitenMARKETING RESEARCH THEORIES AND CONCEPTS - Outlinemarielboongaling23Noch keine Bewertungen
- FRP Guidelines 2020-21Dokument13 SeitenFRP Guidelines 2020-21Shreshth SharmaNoch keine Bewertungen
- Jaw LashDokument16 SeitenJaw LashSven BivalNoch keine Bewertungen
- Learning Modules: Writing Review of Related LiteratureDokument4 SeitenLearning Modules: Writing Review of Related LiteratureJohn Nino DoligolNoch keine Bewertungen
- Midterm Exam in Research MethodologyDokument3 SeitenMidterm Exam in Research MethodologyJohn Carter91% (11)
- Structures For Architects II: ARC 460 ARC 460Dokument18 SeitenStructures For Architects II: ARC 460 ARC 460Omar NajmNoch keine Bewertungen
- Motivation, Pay SatisfactionDokument20 SeitenMotivation, Pay SatisfactionDaeli servvoNoch keine Bewertungen
- Impact of Training and Job Involvement On Job Performance: N. Thevanes and T. DirojanDokument10 SeitenImpact of Training and Job Involvement On Job Performance: N. Thevanes and T. Dirojanhendrik silalahiNoch keine Bewertungen
- WorksheetDokument6 SeitenWorksheetMinilik DersehNoch keine Bewertungen
- Safety Management and ISRSDokument33 SeitenSafety Management and ISRSNinkung07100% (1)
- Pca IcaDokument34 SeitenPca Icasachin121083Noch keine Bewertungen
- GPM CW3 - Summative BriefDokument8 SeitenGPM CW3 - Summative Briefumer munirNoch keine Bewertungen
- Making Pain Visible - An Audit and Review of Documentation To Improve The Use of Pain Assessment by Implementing Pain As The Fifth Vital SignDokument6 SeitenMaking Pain Visible - An Audit and Review of Documentation To Improve The Use of Pain Assessment by Implementing Pain As The Fifth Vital SignWahyu WidiyantoNoch keine Bewertungen
- QABDDokument4 SeitenQABDprakash borahNoch keine Bewertungen
- Lind 18e Chap006Dokument32 SeitenLind 18e Chap006MELLYANA JIENoch keine Bewertungen
- This Content Downloaded From 132.174.253.20 On Fri, 03 Jun 2022 15:37:17 UTCDokument29 SeitenThis Content Downloaded From 132.174.253.20 On Fri, 03 Jun 2022 15:37:17 UTCJerry MastersNoch keine Bewertungen
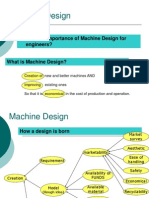
- Machine Design - IntroductionDokument9 SeitenMachine Design - IntroductionluffydmonNoch keine Bewertungen
- ProbStat Tutor 01Dokument3 SeitenProbStat Tutor 01Nam KhanhNoch keine Bewertungen
- PR2 Module 2 Importance of Quantitative ResearchDokument7 SeitenPR2 Module 2 Importance of Quantitative ResearchJohn Francis O. TañamorNoch keine Bewertungen
- Name: - Maveriex Zon S. Lingco - Year & Section: - Date: - I. Multiple Choice. (10 POINTS)Dokument2 SeitenName: - Maveriex Zon S. Lingco - Year & Section: - Date: - I. Multiple Choice. (10 POINTS)Maveriex Zon LingcoNoch keine Bewertungen
- MainDokument45 SeitenMainravirajpu_43Noch keine Bewertungen
- Sample Repertory GridDokument16 SeitenSample Repertory GridApril J. RiveraNoch keine Bewertungen
- 2.1 Transformational LeadershipDokument8 Seiten2.1 Transformational Leadershipaffan kurniawanNoch keine Bewertungen
- Esempi Di Literature ReviewDokument7 SeitenEsempi Di Literature Reviewfihum1hadej2100% (1)
- 4 Machiavellianism, Perfectionistic Self-Presentation and Decision-Making in LeadersDokument16 Seiten4 Machiavellianism, Perfectionistic Self-Presentation and Decision-Making in LeadersApplied Psychology Review (APR)Noch keine Bewertungen
- Cat-Calls and Culpability Investigating The FrequencyDokument12 SeitenCat-Calls and Culpability Investigating The Frequencykirana dwiNoch keine Bewertungen
- Lind17e Chapter04 TBDokument9 SeitenLind17e Chapter04 TBdockmom4Noch keine Bewertungen