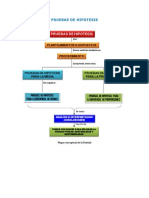
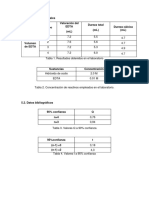
Das könnte Ihnen auch gefallen
- Estadística InferencialDokument8 SeitenEstadística InferencialEDISON ALEXANDER PALOMO ALLAUCANoch keine Bewertungen
- ProbabilidadDokument77 SeitenProbabilidadLuciano LimaNoch keine Bewertungen
- Estadística I - Control de Lectura 3Dokument7 SeitenEstadística I - Control de Lectura 3gilgameshNoch keine Bewertungen
- Distribución Probabilidad BinomialDokument3 SeitenDistribución Probabilidad BinomialnavNoch keine Bewertungen
- Inferencia Estadística y Prueba Chi-cuadradoDokument13 SeitenInferencia Estadística y Prueba Chi-cuadradoElias Jose Albis PachecoNoch keine Bewertungen
- Resumen de Distribuciones de ProbabilidadDokument11 SeitenResumen de Distribuciones de Probabilidadruben torresNoch keine Bewertungen
- Distribucion de ProbabilidadesDokument18 SeitenDistribucion de ProbabilidadesDaniel HernandezNoch keine Bewertungen
- Portafolio Unidad 3Dokument26 SeitenPortafolio Unidad 3Reyna MontoyaNoch keine Bewertungen
- Tarea de Estadistica 1Dokument14 SeitenTarea de Estadistica 1Ninel ReyesNoch keine Bewertungen
- Esta Di SticaDokument25 SeitenEsta Di SticaSergio QuiñonesNoch keine Bewertungen
- Guía 10A PDFDokument9 SeitenGuía 10A PDFSebas Alias PapichurroNoch keine Bewertungen
- Sesion 6 ModifiDokument45 SeitenSesion 6 ModifiJorge ShawNoch keine Bewertungen
- Resumen DEL Segundo Parcial EstadisticaDokument10 SeitenResumen DEL Segundo Parcial EstadisticaMagdalena EchavarriaNoch keine Bewertungen
- Econometria - IDokument16 SeitenEconometria - IAlejandro S Figueroa AriasNoch keine Bewertungen
- Unidad 5Dokument11 SeitenUnidad 5Micaaa ANoch keine Bewertungen
- S07.s7-DISTRIBUCIÓN DE PROBABILIDAD CONTINUADokument20 SeitenS07.s7-DISTRIBUCIÓN DE PROBABILIDAD CONTINUAgermanNoch keine Bewertungen
- Semana 6 InformeDokument5 SeitenSemana 6 InformeElianne Alexandra Diaz SaldañaNoch keine Bewertungen
- Distribuciones de ProbabilidadDokument21 SeitenDistribuciones de ProbabilidadAzeret Seahorse ArriagaNoch keine Bewertungen
- Variables aleatorias y distribucionesDokument26 SeitenVariables aleatorias y distribucionesRogers Eduardo Cabrera SandovalNoch keine Bewertungen
- Clase02 - Distribuciones de ProbabilidadDokument69 SeitenClase02 - Distribuciones de ProbabilidadFernanda AltamiranoNoch keine Bewertungen
- Practica EstadisticaDokument19 SeitenPractica EstadisticaLuck Kal DavidNoch keine Bewertungen
- Prueba de Hipótesis para La Media de Una y Dos PoblacionesDokument6 SeitenPrueba de Hipótesis para La Media de Una y Dos PoblacionesAlex Tafur Gallardo100% (1)
- Modelos de ProbabilidadDokument11 SeitenModelos de ProbabilidadMichelle CurielNoch keine Bewertungen
- Distribuciones de ProbabilidadDokument7 SeitenDistribuciones de ProbabilidadOmar Percy RomeroNoch keine Bewertungen
- Repaso de EstadisticaDokument29 SeitenRepaso de EstadisticaDarwin UberuagaNoch keine Bewertungen
- Tema 9Dokument19 SeitenTema 9jorgeluis ramos maqueraNoch keine Bewertungen
- Resumen Modelos DiscretosDokument2 SeitenResumen Modelos DiscretosfabianNoch keine Bewertungen
- Resumen GeneralDokument4 SeitenResumen GeneralM Sol FiloniNoch keine Bewertungen
- Prueba de Hipotesis para La Diferencia de Dos MediasDokument28 SeitenPrueba de Hipotesis para La Diferencia de Dos MediasANDRES DURAN TORRESNoch keine Bewertungen
- Estimación Estadística: Intervalos de Confianza para Parámetros PoblacionalesDokument16 SeitenEstimación Estadística: Intervalos de Confianza para Parámetros PoblacionalesleoastorsNoch keine Bewertungen
- Distribución ProbabilidadDokument41 SeitenDistribución ProbabilidadYENY PAOLA LIZARAZO MUÑOZNoch keine Bewertungen
- Resumen Pep IIIDokument5 SeitenResumen Pep IIIMichelle Varela CáceresNoch keine Bewertungen
- Trbajo Colabortivo 2 ProbabilidadDokument25 SeitenTrbajo Colabortivo 2 Probabilidadcindy katherineNoch keine Bewertungen
- Esp U1 A1 MascDokument6 SeitenEsp U1 A1 MascEnrique FoyoNoch keine Bewertungen
- ESA - Modulo 3Dokument14 SeitenESA - Modulo 3Josè Vegar0% (1)
- Resumen Distribuciones ProbaDokument10 SeitenResumen Distribuciones ProbaWillmer AguileraNoch keine Bewertungen
- Distribuciones TeoricasDokument8 SeitenDistribuciones TeoricasMauro GomezNoch keine Bewertungen
- Distribuciones de ProbabilidadDokument69 SeitenDistribuciones de ProbabilidadEDSON LUIS MEDRANO HUANCANoch keine Bewertungen
- Distribución HipergeométricaDokument2 SeitenDistribución HipergeométricaDaniel AvilaNoch keine Bewertungen
- Distribuciones de probabilidad y ejercicios de aplicaciónDokument3 SeitenDistribuciones de probabilidad y ejercicios de aplicaciónDayry GonzálezNoch keine Bewertungen
- Prueba de HipótesisDokument35 SeitenPrueba de HipótesisPetronila MedHerrNoch keine Bewertungen
- Estimación de La PoblaciónDokument4 SeitenEstimación de La PoblaciónDIEGO AUGUSTO MAR PÉREZNoch keine Bewertungen
- Distribuciones de probabilidad y ejercicios resueltosDokument5 SeitenDistribuciones de probabilidad y ejercicios resueltosdania yarizuelNoch keine Bewertungen
- Unidad IIIDokument26 SeitenUnidad IIIfranco reynosoNoch keine Bewertungen
- Distribución BinomialDokument8 SeitenDistribución BinomialJose Jose FernandezNoch keine Bewertungen
- Trabajo Capitulo 2Dokument9 SeitenTrabajo Capitulo 2Jav AbbNoch keine Bewertungen
- Apuntes de Probabilidad y Estadistica - IIDokument25 SeitenApuntes de Probabilidad y Estadistica - IInelson gabriel cachi vargasNoch keine Bewertungen
- Unidad 5Dokument3 SeitenUnidad 5Micaaa ANoch keine Bewertungen
- Analisis de Varianza ANOVA2Dokument38 SeitenAnalisis de Varianza ANOVA2Pablo Lopez IINoch keine Bewertungen
- Distribuciones de Probabilidad DiscretasDokument31 SeitenDistribuciones de Probabilidad DiscretasKaren Dayana TautivaNoch keine Bewertungen
- Actividad 5Dokument3 SeitenActividad 5Zaidel Flores RayaNoch keine Bewertungen
- S12.s1 - APLI - DIST - PROBDokument20 SeitenS12.s1 - APLI - DIST - PROBAngela Pamela CHIROQUE SosaNoch keine Bewertungen
- Pruebas de Hipótesis ParametricasDokument14 SeitenPruebas de Hipótesis ParametricasyeihardNoch keine Bewertungen
- Contrastes FrecuenciasDokument53 SeitenContrastes FrecuenciaspabloNoch keine Bewertungen
- Distribuciones de ProbabilidadDokument25 SeitenDistribuciones de ProbabilidadYissel OdalisNoch keine Bewertungen
- Distribución de probabilidad guíaDokument57 SeitenDistribución de probabilidad guíaMona VegaoliNoch keine Bewertungen
- UNIDAD I - LLDokument33 SeitenUNIDAD I - LLMeryNoch keine Bewertungen
- Linux BasicoDokument4 SeitenLinux BasicobeaNoch keine Bewertungen
- Tema 2 PDFDokument67 SeitenTema 2 PDFbeaNoch keine Bewertungen
- Análisis de varianza de dos factores (IIDokument10 SeitenAnálisis de varianza de dos factores (IIbeaNoch keine Bewertungen
- TCT y Tipos TestDokument7 SeitenTCT y Tipos TestbeaNoch keine Bewertungen
- SEM Estadisticos de Ajuste GlobalDokument8 SeitenSEM Estadisticos de Ajuste GlobalbeaNoch keine Bewertungen
- Psicometría: medición de variables psicológicasDokument7 SeitenPsicometría: medición de variables psicológicasbeaNoch keine Bewertungen
- AFC vs AFE: factores y variablesDokument10 SeitenAFC vs AFE: factores y variablesbeaNoch keine Bewertungen
- Sem AfcDokument7 SeitenSem AfcbeaNoch keine Bewertungen
- Modelos Lineales MixtosDokument8 SeitenModelos Lineales MixtosbeaNoch keine Bewertungen
- Distribucion de Frecuencias para Datos No Agrupados ModificadoDokument26 SeitenDistribucion de Frecuencias para Datos No Agrupados ModificadoLeticiaNoch keine Bewertungen
- Graficos de ControlDokument6 SeitenGraficos de ControlMarco AguilarNoch keine Bewertungen
- S09.s1 - Material - Presentación 1 - Semana 9Dokument33 SeitenS09.s1 - Material - Presentación 1 - Semana 9Jorge AnayaNoch keine Bewertungen
- s9 Taller 2 EpidemiologíaDokument8 Seitens9 Taller 2 Epidemiologíabrian condoNoch keine Bewertungen
- UCV Especializacion - Investigación de OperacionesDokument2 SeitenUCV Especializacion - Investigación de OperacionesCarlos Luis Esquerdo MarcanoNoch keine Bewertungen
- Ingenieria de SoftwareDokument87 SeitenIngenieria de Softwaregeneller100% (2)
- Herramientas AdministrativasDokument3 SeitenHerramientas AdministrativasSkylar LobosNoch keine Bewertungen
- Determinación de La Dureza Del AguaDokument9 SeitenDeterminación de La Dureza Del AguaAnonymous 28dbytNoch keine Bewertungen
- Cómo Generar Ideas para Una Investigación PDFDokument9 SeitenCómo Generar Ideas para Una Investigación PDFAndrea SanchezNoch keine Bewertungen
- FodaDokument49 SeitenFodaLuicito PachiñoNoch keine Bewertungen
- Informe EstadisticaDokument6 SeitenInforme EstadisticaMiguel SANoch keine Bewertungen
- Cómo Elaborar Monografias, Artículos Científicos y Otros Textos Expositivos - Ezequiel Ander-Egg y Pablo ValleDokument92 SeitenCómo Elaborar Monografias, Artículos Científicos y Otros Textos Expositivos - Ezequiel Ander-Egg y Pablo ValleSergio Segovia100% (2)
- Base Alien en Las Piramides Chinas.Dokument14 SeitenBase Alien en Las Piramides Chinas.Diego LanconNoch keine Bewertungen
- Validación instrumentos investigaciónDokument22 SeitenValidación instrumentos investigaciónAlesita UENoch keine Bewertungen
- Tavara Alm ProyectoDokument44 SeitenTavara Alm ProyectoSHAIRNoch keine Bewertungen
- Transiciones ofensivas en el fútbolDokument319 SeitenTransiciones ofensivas en el fútbolBeatriz GalánNoch keine Bewertungen
- Trabajo FinalDokument15 SeitenTrabajo FinalÃshlëy Çôrtëgãńâ GålląrdõNoch keine Bewertungen
- PRACTICA 3 Pa EnviarDokument9 SeitenPRACTICA 3 Pa EnviarvictorNoch keine Bewertungen
- Actividad3 EstadisticayprobabilidadDokument8 SeitenActividad3 EstadisticayprobabilidadMartha ParraNoch keine Bewertungen
- Método Delphi: cómo aplicar esta técnica de prospección cualitativa con expertosDokument12 SeitenMétodo Delphi: cómo aplicar esta técnica de prospección cualitativa con expertosLaura TabordaNoch keine Bewertungen
- Sesion Sobre Sismo - MatematicaDokument7 SeitenSesion Sobre Sismo - MatematicaJM Muñoz ChuquirunaNoch keine Bewertungen
- Diseño Experimental Reproduccion Animal 29-06-2019 PDFDokument204 SeitenDiseño Experimental Reproduccion Animal 29-06-2019 PDFCarolina RamosNoch keine Bewertungen
- Informe Final Plan de Marketing de Celeste PijamasDokument87 SeitenInforme Final Plan de Marketing de Celeste PijamasJuan SebastianNoch keine Bewertungen
- Bolivia ModeloEconomicoDesarrollo PDFDokument443 SeitenBolivia ModeloEconomicoDesarrollo PDFJose Manuel Vidal Saucedo50% (2)
- Libro de Calidad TotalDokument114 SeitenLibro de Calidad Totalangie7502Noch keine Bewertungen
- Trabajo Social y Justicia Juvenil.Dokument108 SeitenTrabajo Social y Justicia Juvenil.Chiza Card CháNoch keine Bewertungen
- Metodo AvanzadaDokument27 SeitenMetodo AvanzadaFatimaGuadalupePalmaJacintoNoch keine Bewertungen
- Estadística de Probabilidades - Eje 2Dokument25 SeitenEstadística de Probabilidades - Eje 2Santiago BarbosaNoch keine Bewertungen
- Ponencia INNABYDokument13 SeitenPonencia INNABYinnabyNoch keine Bewertungen