Das könnte Ihnen auch gefallen
- Unit+3.+M Ary+TransmissionDokument59 SeitenUnit+3.+M Ary+TransmissionTariq MatarNoch keine Bewertungen
- Opera FormulaDokument4 SeitenOpera FormulaWasyif AlshammariNoch keine Bewertungen
- Lecture 04Dokument24 SeitenLecture 04Muhammad Ali KhanNoch keine Bewertungen
- CE687A Lecture23Dokument32 SeitenCE687A Lecture23varunNoch keine Bewertungen
- Formulario MTBF Calcular La Probabilidad de Falla Estadística Por: . + .Dokument3 SeitenFormulario MTBF Calcular La Probabilidad de Falla Estadística Por: . + .Eduardo Torres PinoNoch keine Bewertungen
- Practical Research 2 Quantitative Research: Inferential Statistics Reference of Formulas Hypothesis-Testing ProcessDokument4 SeitenPractical Research 2 Quantitative Research: Inferential Statistics Reference of Formulas Hypothesis-Testing Processjessa barbosaNoch keine Bewertungen
- Razones Trigonométricas:: TrigonometriaDokument3 SeitenRazones Trigonométricas:: TrigonometriaIvan YanaNoch keine Bewertungen
- RD2 QuaternionsDokument19 SeitenRD2 QuaternionselmcadbuickNoch keine Bewertungen
- Machine Learning FoundamentalDokument10 SeitenMachine Learning Foundamentals_m_hosseini_ardaliNoch keine Bewertungen
- Pre Calculus Q2 - Week 5 Graph of CSC SEC TAN COTDokument49 SeitenPre Calculus Q2 - Week 5 Graph of CSC SEC TAN COTKinNoch keine Bewertungen
- Pattern Classification 11. Backpropagation & Time-Series ForecastingDokument78 SeitenPattern Classification 11. Backpropagation & Time-Series ForecastingMostafa MohamedNoch keine Bewertungen
- Ac Machinery FormulasDokument4 SeitenAc Machinery FormulasNhilNoch keine Bewertungen
- Robot Arm KINEMATICs and DynamicsDokument27 SeitenRobot Arm KINEMATICs and DynamicsTirth VyasNoch keine Bewertungen
- Deep Learning Basics Lecture 8 Autoencoder & DBMDokument28 SeitenDeep Learning Basics Lecture 8 Autoencoder & DBMbarisNoch keine Bewertungen
- DL Lecture8 AutoencoderDokument28 SeitenDL Lecture8 Autoencodergourav VermaNoch keine Bewertungen
- Steady State ErrorDokument4 SeitenSteady State ErrorAhmed KhaledNoch keine Bewertungen
- L11.2 Prob Models emDokument20 SeitenL11.2 Prob Models emVõ Bảo QuốcNoch keine Bewertungen
- 6j SymbolDokument30 Seiten6j SymbolZodinmawia TlauNoch keine Bewertungen
- Folmula SheetDokument6 SeitenFolmula SheetMariam MahmoudNoch keine Bewertungen
- Math ExamDokument9 SeitenMath ExamMalik AsadNoch keine Bewertungen
- Pattern Classification 10. Linear Perceptron, Least Squares & Multi-Layer NnsDokument38 SeitenPattern Classification 10. Linear Perceptron, Least Squares & Multi-Layer NnsMostafa MohamedNoch keine Bewertungen
- Lecture 19 and 20Dokument27 SeitenLecture 19 and 20shivna0809Noch keine Bewertungen
- Formulario de DerivadasDokument1 SeiteFormulario de DerivadasDiego HernandezNoch keine Bewertungen
- Topic 4 - Power Series - Q&A - Q1-Q6Dokument12 SeitenTopic 4 - Power Series - Q&A - Q1-Q6deivasigamaniNoch keine Bewertungen
- Quick Reference of Linear AlgebraDokument16 SeitenQuick Reference of Linear AlgebraDaniel YangNoch keine Bewertungen
- Lecture 3Dokument28 SeitenLecture 3tl xNoch keine Bewertungen
- Addedup FormulasDokument6 SeitenAddedup Formulas19-MCE-30 Usama manzoorNoch keine Bewertungen
- Laplace TransformDokument14 SeitenLaplace TransformJohn RedaNoch keine Bewertungen
- ANOVA (Analysis of Variance)Dokument9 SeitenANOVA (Analysis of Variance)Aniruddha PhalakNoch keine Bewertungen
- Theory of Structures 2 Chapter 1.3Dokument7 SeitenTheory of Structures 2 Chapter 1.3mikeNoch keine Bewertungen
- ES 91 Depreciation FormulasDokument1 SeiteES 91 Depreciation FormulasKarl Pepon AyalaNoch keine Bewertungen
- Big Data JPMDokument31 SeitenBig Data JPMmitch mastNoch keine Bewertungen
- Z - Transform: Digital Signal Processing - Lecture 6Dokument17 SeitenZ - Transform: Digital Signal Processing - Lecture 6lina hazemNoch keine Bewertungen
- RLS PresentationDokument29 SeitenRLS PresentationGidey LeulNoch keine Bewertungen
- Reynolds Transport TheoremDokument2 SeitenReynolds Transport TheoremNati FernandezNoch keine Bewertungen
- Describing Function Calculations For Some Common NonlinearitiesDokument25 SeitenDescribing Function Calculations For Some Common NonlinearitiesdesinamichaelNoch keine Bewertungen
- Simple Pendulum Modelling Simulation 1686477167Dokument12 SeitenSimple Pendulum Modelling Simulation 1686477167durssiNoch keine Bewertungen
- Week 5 Logarithmic FunctionsDokument18 SeitenWeek 5 Logarithmic FunctionsKim GonocruzNoch keine Bewertungen
- CalculusDokument16 SeitenCalculusapi-662361166Noch keine Bewertungen
- 215 Final Exam Formula SheetDokument2 Seiten215 Final Exam Formula SheetH.C. Z.Noch keine Bewertungen
- EE435 Chapter2 Lec2 PID+State-Space A.HaddadDokument9 SeitenEE435 Chapter2 Lec2 PID+State-Space A.HaddadIbrahim abdoNoch keine Bewertungen
- Integral Calculus NotesDokument43 SeitenIntegral Calculus NotesArjay S. Bazar100% (1)
- 03 LagrangianDynamics 1Dokument29 Seiten03 LagrangianDynamics 1Exequiel RemersaroNoch keine Bewertungen
- PPG MLRM Upto Autocorr PDFDokument20 SeitenPPG MLRM Upto Autocorr PDFReetom GhoshNoch keine Bewertungen
- AnalysisDokument11 SeitenAnalysisNISHANK KANSARANoch keine Bewertungen
- APFE Notes April6Dokument63 SeitenAPFE Notes April6Triet TruongNoch keine Bewertungen
- Dr. S. Vairachilai Department of CSE CVR College of Engineering Mangalpalli TelanganaDokument33 SeitenDr. S. Vairachilai Department of CSE CVR College of Engineering Mangalpalli TelanganaSavitha ElluruNoch keine Bewertungen
- Lecture2 v1Dokument36 SeitenLecture2 v1Kathérine JosephNoch keine Bewertungen
- APFE Notes April13 ModDokument67 SeitenAPFE Notes April13 ModTriet TruongNoch keine Bewertungen
- Back Propagation AlgorithmDokument12 SeitenBack Propagation AlgorithmJhumur SantraNoch keine Bewertungen
- L 03 - Ece 4217Dokument26 SeitenL 03 - Ece 4217কবুতর বাড়ি Pigeon HomeNoch keine Bewertungen
- Control in The Cartesian Space: Robotics 2Dokument13 SeitenControl in The Cartesian Space: Robotics 2zhaodong.liangNoch keine Bewertungen
- Lec 02-8 - Longitudinal DampingDokument12 SeitenLec 02-8 - Longitudinal DampingArslan MehmoodNoch keine Bewertungen
- UEE605 Lect 12 NR MethodDokument19 SeitenUEE605 Lect 12 NR MethodAditya AdityaNoch keine Bewertungen
- PMS Theory Chapter2Dokument42 SeitenPMS Theory Chapter2moulitechNoch keine Bewertungen
- 6 Differentiation Rules 2024Dokument23 Seiten6 Differentiation Rules 2024alliztairgabriellabartolome18Noch keine Bewertungen
- Analytical Solutions For Velocity Analysis: A BA BDokument1 SeiteAnalytical Solutions For Velocity Analysis: A BA BKhuzifa AfridiNoch keine Bewertungen
- Heat Design Problem 2Dokument21 SeitenHeat Design Problem 2Samir YehyaNoch keine Bewertungen
- Visualization and Understanding CnnsDokument27 SeitenVisualization and Understanding CnnsaliNoch keine Bewertungen
- RNN & LSTMDokument99 SeitenRNN & LSTMaliNoch keine Bewertungen
- Training Neural Networks - Practical IssuesDokument54 SeitenTraining Neural Networks - Practical IssuesaliNoch keine Bewertungen
- CNN Case StudiesDokument73 SeitenCNN Case StudiesaliNoch keine Bewertungen
- CNN Vision ApplicationsDokument63 SeitenCNN Vision ApplicationsaliNoch keine Bewertungen
- Convolutional Neural NetworksDokument55 SeitenConvolutional Neural NetworksaliNoch keine Bewertungen
- CS109/Stat121/AC209/E-109 Data Science: Statistical ModelsDokument26 SeitenCS109/Stat121/AC209/E-109 Data Science: Statistical Modelsgowtam_raviNoch keine Bewertungen
- Statistical Tables and ChartsDokument27 SeitenStatistical Tables and ChartsJeth LacuestaNoch keine Bewertungen
- A Turing Machine Is A Mathematical Model of Computation That Defines An Abstract Machine That Manipulates Symbols On A Strip of Tape According To A Table of RulesDokument3 SeitenA Turing Machine Is A Mathematical Model of Computation That Defines An Abstract Machine That Manipulates Symbols On A Strip of Tape According To A Table of Rulesmaki ababiNoch keine Bewertungen
- Unit 20 - Assignment 1 GuidanceDokument4 SeitenUnit 20 - Assignment 1 GuidanceBi SuNoch keine Bewertungen
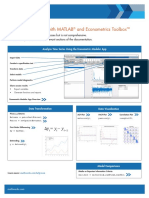
- Time Series Analysis With MATLAB and Econometrics ToolboxDokument2 SeitenTime Series Analysis With MATLAB and Econometrics ToolboxKamel RamtanNoch keine Bewertungen
- CIVL 2160 Tutorial T2 On Oct. 30 (Monday) Will Be Held in Rm2304 (Lift17/18) - HW2 Due Next Friday, 27 OctDokument14 SeitenCIVL 2160 Tutorial T2 On Oct. 30 (Monday) Will Be Held in Rm2304 (Lift17/18) - HW2 Due Next Friday, 27 OctTina ChenNoch keine Bewertungen
- UT Dallas Syllabus For Meco6315.501.07s Taught by John Wiorkowski (Wiorkow)Dokument4 SeitenUT Dallas Syllabus For Meco6315.501.07s Taught by John Wiorkowski (Wiorkow)UT Dallas Provost's Technology GroupNoch keine Bewertungen
- Ogata Control PDFDokument2 SeitenOgata Control PDFAdam0% (3)
- BackPropagation Through TimeDokument6 SeitenBackPropagation Through Timemilan gemerskyNoch keine Bewertungen
- Discrete Random Variables: 4.1 Definition, Mean and VarianceDokument15 SeitenDiscrete Random Variables: 4.1 Definition, Mean and VariancejordyswannNoch keine Bewertungen
- Week 4 OOPDokument16 SeitenWeek 4 OOPArslan Baloch AshuNoch keine Bewertungen
- Kelompok 4 Itapp-Wbs Sistem Kasir Minimarket-1Dokument2 SeitenKelompok 4 Itapp-Wbs Sistem Kasir Minimarket-1Muhammad fadliNoch keine Bewertungen
- Time SeriesDokument819 SeitenTime Seriescristian_masterNoch keine Bewertungen
- Creating Generalization/Specialization Relationships Using InheritanceDokument2 SeitenCreating Generalization/Specialization Relationships Using InheritanceJayaramsai PanchakarlaNoch keine Bewertungen
- Multivariate Time Series ModelingDokument7 SeitenMultivariate Time Series ModelingShehryar KhanNoch keine Bewertungen
- Ai20 - 03 - NNDokument32 SeitenAi20 - 03 - NNAshutosh BiswalNoch keine Bewertungen
- Lecture 6 - Multi-Layer Feedforward Neural Networks Using Matlab Part 2Dokument3 SeitenLecture 6 - Multi-Layer Feedforward Neural Networks Using Matlab Part 2Ammar AlkindyNoch keine Bewertungen
- hw4 CSCI6339Dokument3 Seitenhw4 CSCI6339rysul12Noch keine Bewertungen
- Use Case ModelDokument19 SeitenUse Case Modelkleyner farinangoNoch keine Bewertungen
- Probability DistributionsDokument198 SeitenProbability Distributionsgregoriopiccoli100% (4)
- ATC-Alat Berat Part 4Dokument18 SeitenATC-Alat Berat Part 4KABINET JALADARA NABDANoch keine Bewertungen
- Bayes' Rule and Law of Total Probability: C C C C C 1 2 3Dokument8 SeitenBayes' Rule and Law of Total Probability: C C C C C 1 2 3Adel NizamutdinovNoch keine Bewertungen
- Practical No.1Dokument2 SeitenPractical No.1Abhishek PandeyNoch keine Bewertungen
- Tabel PoisonDokument2 SeitenTabel PoisonTitin Efi IdayatiNoch keine Bewertungen
- BBAC 322 Module 2016 EdittedDokument150 SeitenBBAC 322 Module 2016 EdittedFranck IRADUKUNDANoch keine Bewertungen
- Department of Computer Science and Engineering Lesson Plan - Formal Languages and Automata TheoryDokument12 SeitenDepartment of Computer Science and Engineering Lesson Plan - Formal Languages and Automata Theoryshubh agrawalNoch keine Bewertungen
- Water: Development of A Deep Learning-Based Prediction Model For Water Consumption at The Household LevelDokument17 SeitenWater: Development of A Deep Learning-Based Prediction Model For Water Consumption at The Household Levelalemneh mihretieNoch keine Bewertungen
- ANN Most NotesDokument6 SeitenANN Most NotesUmesh KumarNoch keine Bewertungen
- Chapter 7 Binomial, Normal, and Poisson DistributionsDokument2 SeitenChapter 7 Binomial, Normal, and Poisson Distributionsdestu aryantoNoch keine Bewertungen
- Artificial Neural Network - ..Dokument15 SeitenArtificial Neural Network - ..Nidhish G100% (1)