Das könnte Ihnen auch gefallen
- Recurrent Neural Networks: Fundamentals and Applications from Simple to Gated ArchitecturesVon EverandRecurrent Neural Networks: Fundamentals and Applications from Simple to Gated ArchitecturesNoch keine Bewertungen
- Pattern Recognition and Machine Learning Errata and Additional CommentsDokument7 SeitenPattern Recognition and Machine Learning Errata and Additional Commentslavender20180% (1)
- Reinforcement Learning Sutton BookDokument172 SeitenReinforcement Learning Sutton BookDom DeSicilia100% (1)
- Generating a New Reality: From Autoencoders and Adversarial Networks to DeepfakesVon EverandGenerating a New Reality: From Autoencoders and Adversarial Networks to DeepfakesNoch keine Bewertungen
- Ascend AI Processor Architecture and Programming: Principles and Applications of CANNVon EverandAscend AI Processor Architecture and Programming: Principles and Applications of CANNNoch keine Bewertungen
- Introduction to Deep Learning and Neural Networks with Python™: A Practical GuideVon EverandIntroduction to Deep Learning and Neural Networks with Python™: A Practical GuideNoch keine Bewertungen
- Mta - 98-385Dokument65 SeitenMta - 98-385Jackson Ferreira Crispin100% (1)
- Large Scale Deep LearningDokument170 SeitenLarge Scale Deep Learningpavancreative81Noch keine Bewertungen
- Introduction to Machine Learning in the Cloud with Python: Concepts and PracticesVon EverandIntroduction to Machine Learning in the Cloud with Python: Concepts and PracticesNoch keine Bewertungen
- ANN Mini Project on Artificial Neural Networks (40Dokument16 SeitenANN Mini Project on Artificial Neural Networks (40amithbalu100% (1)
- Statistical MechanicsDokument41 SeitenStatistical MechanicsFrazNoch keine Bewertungen
- Quantum Measurement 2016Dokument544 SeitenQuantum Measurement 2016Michael LaugierNoch keine Bewertungen
- Data Mining Algorithms in C++: Data Patterns and Algorithms for Modern ApplicationsVon EverandData Mining Algorithms in C++: Data Patterns and Algorithms for Modern ApplicationsNoch keine Bewertungen
- Arduino Wearable Projects - Sample ChapterDokument24 SeitenArduino Wearable Projects - Sample ChapterPackt PublishingNoch keine Bewertungen
- Google Cloud Big Data Solutions OverviewDokument17 SeitenGoogle Cloud Big Data Solutions OverviewSouvik PratiherNoch keine Bewertungen
- Perceptron Learning RulesDokument38 SeitenPerceptron Learning RulesVivek Goyal50% (2)
- Unlocking the Power of Vulkan: A Journey into AI and Machine LearningVon EverandUnlocking the Power of Vulkan: A Journey into AI and Machine LearningNoch keine Bewertungen
- Deep Belief Nets in C++ and CUDA C: Volume 2: Autoencoding in the Complex DomainVon EverandDeep Belief Nets in C++ and CUDA C: Volume 2: Autoencoding in the Complex DomainNoch keine Bewertungen
- Classification of Mushroom Fungi Using Machine LeaDokument8 SeitenClassification of Mushroom Fungi Using Machine Leadhruvi kapadiaNoch keine Bewertungen
- Artificial Neural Networks in Finance and ManufacturingDokument299 SeitenArtificial Neural Networks in Finance and ManufacturingVijay GadakhNoch keine Bewertungen
- Formalizing Common SenseDokument50 SeitenFormalizing Common SenseAlephNullNoch keine Bewertungen
- Art of Ss Filestream PDFDokument487 SeitenArt of Ss Filestream PDFArtur PietrzykNoch keine Bewertungen
- JMP User's Guide PDFDokument291 SeitenJMP User's Guide PDFAmare GirmaNoch keine Bewertungen
- The Big Table of Quantum AIDokument7 SeitenThe Big Table of Quantum AIAbu Mohammad Omar Shehab Uddin AyubNoch keine Bewertungen
- Outlier Detection: Techniques and Applications: N. N. R. Ranga Suri Narasimha Murty M G. AthithanDokument227 SeitenOutlier Detection: Techniques and Applications: N. N. R. Ranga Suri Narasimha Murty M G. Athithanميلاد نوروزي رهبرNoch keine Bewertungen
- 31-34 - Artificial Neural NetworkDokument36 Seiten31-34 - Artificial Neural NetworkZalak RakholiyaNoch keine Bewertungen
- Combinatorial Mathematics, Optimal Designs, and Their ApplicationsVon EverandCombinatorial Mathematics, Optimal Designs, and Their ApplicationsNoch keine Bewertungen
- Understanding Neural Networks From Scratch in Python and RDokument12 SeitenUnderstanding Neural Networks From Scratch in Python and RKhương NguyễnNoch keine Bewertungen
- AI Native Enterprise: The Leader's Guide to AI-Powered Business TransformationVon EverandAI Native Enterprise: The Leader's Guide to AI-Powered Business TransformationNoch keine Bewertungen
- Artificial Intelligence-Book ChapterDokument585 SeitenArtificial Intelligence-Book Chaptersatheesh kumarNoch keine Bewertungen
- Multi Level Agent Based ModelingDokument27 SeitenMulti Level Agent Based ModelingDiego Urrutia OlaecheaNoch keine Bewertungen
- Python Programming With The Java Class Libraries - A TutoriaDokument557 SeitenPython Programming With The Java Class Libraries - A Tutoriaacytra23Noch keine Bewertungen
- Field+Guide+to+NetLogo+v14-netlogoExtension-index - 02 NuevoDokument198 SeitenField+Guide+to+NetLogo+v14-netlogoExtension-index - 02 Nuevourbam zarateNoch keine Bewertungen
- The AI Artificial Intelligence Course From Beginner to ExpertVon EverandThe AI Artificial Intelligence Course From Beginner to ExpertNoch keine Bewertungen
- DeepLearningWithMATLABSeminar 1hrDokument93 SeitenDeepLearningWithMATLABSeminar 1hrKristian TorresNoch keine Bewertungen
- Introduction To ML Partial 2 PDFDokument54 SeitenIntroduction To ML Partial 2 PDFLesocrateNoch keine Bewertungen
- How To Create An Operating SystemDokument29 SeitenHow To Create An Operating Systemaicosi0% (1)
- Modeling Knowledge with Object-Process MethodologyDokument18 SeitenModeling Knowledge with Object-Process MethodologytarapacawarezNoch keine Bewertungen
- Generative Adversarial Networks (GANs) - Engine and Applications PDFDokument13 SeitenGenerative Adversarial Networks (GANs) - Engine and Applications PDFKhaja Riazuddin Nawaz MohammedNoch keine Bewertungen
- Exploring BeagleBone: Tools and Techniques for Building with Embedded LinuxVon EverandExploring BeagleBone: Tools and Techniques for Building with Embedded LinuxBewertung: 4 von 5 Sternen4/5 (2)
- Introduction to Deep Learning Business Applications for Developers: From Conversational Bots in Customer Service to Medical Image ProcessingVon EverandIntroduction to Deep Learning Business Applications for Developers: From Conversational Bots in Customer Service to Medical Image ProcessingNoch keine Bewertungen
- Deep Reinforcement Learning Complete Self-Assessment GuideVon EverandDeep Reinforcement Learning Complete Self-Assessment GuideNoch keine Bewertungen
- Keras For Beginners: Implementing A Recurrent Neural NetworkDokument13 SeitenKeras For Beginners: Implementing A Recurrent Neural NetworkRobert DEL POPOLONoch keine Bewertungen
- Machine Learning: Hands-On for Developers and Technical ProfessionalsVon EverandMachine Learning: Hands-On for Developers and Technical ProfessionalsNoch keine Bewertungen
- Hyperparameter Optimization in Machine Learning: Make Your Machine Learning and Deep Learning Models More EfficientVon EverandHyperparameter Optimization in Machine Learning: Make Your Machine Learning and Deep Learning Models More EfficientNoch keine Bewertungen
- Calculus Maple PDFDokument328 SeitenCalculus Maple PDFruslanagNoch keine Bewertungen
- Practical Scientific Computing in Python A WorkbookDokument43 SeitenPractical Scientific Computing in Python A WorkbookJeff PrattNoch keine Bewertungen
- Artificial Neural Networks Methodological Advances and Bio Medical Applications by Kenji SuzukiDokument374 SeitenArtificial Neural Networks Methodological Advances and Bio Medical Applications by Kenji Suzukizubairaw24Noch keine Bewertungen
- Neural NetworksDokument459 SeitenNeural NetworksemregncNoch keine Bewertungen
- CDokument212 SeitenCSanghamitra SanyalNoch keine Bewertungen
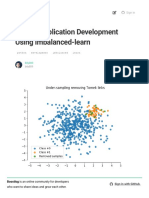
- Python Application Development Using Imbalanced-LearnDokument6 SeitenPython Application Development Using Imbalanced-Learnenghoss77Noch keine Bewertungen
- DEEP LEARNING TECHNIQUES: CLUSTER ANALYSIS and PATTERN RECOGNITION with NEURAL NETWORKS. Examples with MATLABVon EverandDEEP LEARNING TECHNIQUES: CLUSTER ANALYSIS and PATTERN RECOGNITION with NEURAL NETWORKS. Examples with MATLABNoch keine Bewertungen
- Learning PyTorch 2.0: Experiment deep learning from basics to complex models using every potential capability of Pythonic PyTorchVon EverandLearning PyTorch 2.0: Experiment deep learning from basics to complex models using every potential capability of Pythonic PyTorchNoch keine Bewertungen
- Ancient Egypt and Mesoamerica Compared: Regional Integration and Organization of PowerDokument1 SeiteAncient Egypt and Mesoamerica Compared: Regional Integration and Organization of PowerJoseph Affonso XaxoNoch keine Bewertungen
- Kojin Karatani - Transcritique On Kant and MarxDokument382 SeitenKojin Karatani - Transcritique On Kant and MarxGiordano Malta100% (1)
- Kojin Karatani The Structure of World History From Modes of Production To Modes of Exchange PDFDokument375 SeitenKojin Karatani The Structure of World History From Modes of Production To Modes of Exchange PDFManus O'DwyerNoch keine Bewertungen
- Diabetic Foot CareDokument50 SeitenDiabetic Foot CareaswiniNoch keine Bewertungen
- Kosta Dosen, Zoran Petric-Proof-Theoretical Coherence (2015)Dokument391 SeitenKosta Dosen, Zoran Petric-Proof-Theoretical Coherence (2015)Joseph Affonso Xaxo100% (1)
- Diabetic Foot CareDokument50 SeitenDiabetic Foot CareaswiniNoch keine Bewertungen
- Herbert H. Hyman-Political Socialization - A Study in The Psychology of Political Behavior-The Free Press (1959)Dokument87 SeitenHerbert H. Hyman-Political Socialization - A Study in The Psychology of Political Behavior-The Free Press (1959)Joseph Affonso Xaxo100% (1)
- Comment Gary M. Feinman On Political Eco PDFDokument2 SeitenComment Gary M. Feinman On Political Eco PDFJoseph Affonso XaxoNoch keine Bewertungen
- The Other Administration Patronage Syst PDFDokument41 SeitenThe Other Administration Patronage Syst PDFJoseph Affonso XaxoNoch keine Bewertungen
- Some Berber Etymologies X - Lingua Posnaniensis, Vol. LV (1) 2013Dokument12 SeitenSome Berber Etymologies X - Lingua Posnaniensis, Vol. LV (1) 2013Joseph Affonso XaxoNoch keine Bewertungen
- Procedures in Using Ge-Survey System PDFDokument54 SeitenProcedures in Using Ge-Survey System PDFJoel PAcs73% (11)
- MCQ InflationDokument6 SeitenMCQ Inflationashsalvi100% (4)
- Moral Agent - Developing Virtue As HabitDokument2 SeitenMoral Agent - Developing Virtue As HabitCesar Jr Ornedo OrillaNoch keine Bewertungen
- ChE 4110 Process Control HW 1Dokument6 SeitenChE 4110 Process Control HW 1MalloryNoch keine Bewertungen
- Effective Postoperative Pain Management StrategiesDokument10 SeitenEffective Postoperative Pain Management StrategiesvenkayammaNoch keine Bewertungen
- USB and ACPI Device IDsDokument10 SeitenUSB and ACPI Device IDsKortiyarshaBudiyantoNoch keine Bewertungen
- Final VeganDokument11 SeitenFinal Veganapi-314696134Noch keine Bewertungen
- Cylinder Liner W32Dokument1 SeiteCylinder Liner W32Poma100% (1)
- Grand Central Terminal Mep Handbook 180323Dokument84 SeitenGrand Central Terminal Mep Handbook 180323Pete A100% (1)
- Boosting BARMM Infrastructure for Socio-Economic GrowthDokument46 SeitenBoosting BARMM Infrastructure for Socio-Economic GrowthEduardo LongakitNoch keine Bewertungen
- Form 5420 5 General Food Defense PlanDokument11 SeitenForm 5420 5 General Food Defense PlanBenjamin AlecNoch keine Bewertungen
- Syllabus: Android Training Course: 1. JAVA ConceptsDokument6 SeitenSyllabus: Android Training Course: 1. JAVA ConceptsVenkata Rao GudeNoch keine Bewertungen
- C-Core-A3-Fold-Double-Side AMCC COREDokument2 SeitenC-Core-A3-Fold-Double-Side AMCC CORESandeep SNoch keine Bewertungen
- RA ELECTRONICSENGR DAVAO Apr2019 PDFDokument6 SeitenRA ELECTRONICSENGR DAVAO Apr2019 PDFPhilBoardResultsNoch keine Bewertungen
- Sustainability and Design EthicsDokument178 SeitenSustainability and Design EthicsAbby SmithNoch keine Bewertungen
- Non-Traditional Machining: Unit - 1Dokument48 SeitenNon-Traditional Machining: Unit - 1bunty231Noch keine Bewertungen
- High Performance, Low Cost Microprocessor (US Patent 5530890)Dokument49 SeitenHigh Performance, Low Cost Microprocessor (US Patent 5530890)PriorSmartNoch keine Bewertungen
- Css Recommended BooksDokument6 SeitenCss Recommended Booksaman khanNoch keine Bewertungen
- Chapter 2 (Teacher)Dokument19 SeitenChapter 2 (Teacher)ajakazNoch keine Bewertungen
- The Government-Created Subprime Mortgage Meltdown by Thomas DiLorenzoDokument3 SeitenThe Government-Created Subprime Mortgage Meltdown by Thomas DiLorenzodavid rockNoch keine Bewertungen
- Manual For Master Researchpproposal - ThesisDokument54 SeitenManual For Master Researchpproposal - ThesisTewfic Seid100% (3)
- Gas Turbine MaintenanceDokument146 SeitenGas Turbine MaintenanceMamoun1969100% (8)
- Corporations Defined and FormedDokument16 SeitenCorporations Defined and FormedSheryn Mae AlinNoch keine Bewertungen
- Word FormationDokument20 SeitenWord FormationMarijana Dragaš100% (1)
- Adverse Drug Reactions in A ComplementaryDokument8 SeitenAdverse Drug Reactions in A Complementaryrr48843Noch keine Bewertungen
- 3.1. Optical Sources - LED - FOC - PNP - February 2022 - NewDokument49 Seiten3.1. Optical Sources - LED - FOC - PNP - February 2022 - NewyashNoch keine Bewertungen
- Sujit Kumar Rout, Rupashree Ragini Sahoo, Soumya Ranjan Satapathy, Barada Prasad SethyDokument7 SeitenSujit Kumar Rout, Rupashree Ragini Sahoo, Soumya Ranjan Satapathy, Barada Prasad SethyPrabu ThannasiNoch keine Bewertungen
- PCM320 IDM320 NIM220 PMM310 Base Release Notes 1210Dokument48 SeitenPCM320 IDM320 NIM220 PMM310 Base Release Notes 1210Eduardo Lecaros CabelloNoch keine Bewertungen
- Chapter 3 Theoretical ConsiderationsDokument8 SeitenChapter 3 Theoretical Considerationsapi-3696675Noch keine Bewertungen
- Summary of Relief Scenarios: Contingency DataDokument3 SeitenSummary of Relief Scenarios: Contingency Dataimtinan mohsinNoch keine Bewertungen