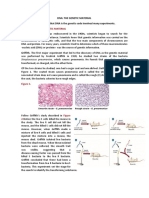
Das könnte Ihnen auch gefallen
- Am S Dna TopologyDokument33 SeitenAm S Dna TopologyParijat BanerjeeNoch keine Bewertungen
- Introduction To How DNA WorksDokument15 SeitenIntroduction To How DNA WorksYomi BrainNoch keine Bewertungen
- DNA as the Genetic Blueprint of LifeDokument26 SeitenDNA as the Genetic Blueprint of LifeFernanda NúñezNoch keine Bewertungen
- Xeroderma Pigmentosum Is Inherited Human Skin Diseases That Causes A Variety of Phenotype Change in Skin Cell Exposed To SunlighDokument1 SeiteXeroderma Pigmentosum Is Inherited Human Skin Diseases That Causes A Variety of Phenotype Change in Skin Cell Exposed To Sunlighסנאבל מוסאNoch keine Bewertungen
- Combinatorics in molecular biologyDokument18 SeitenCombinatorics in molecular biologyMarcos Valero TorresNoch keine Bewertungen
- Molecular Basis of InheritanceDokument61 SeitenMolecular Basis of InheritanceGovind Mani Bhatt100% (1)
- Dogma Genetic and Molecular GeneticDokument11 SeitenDogma Genetic and Molecular GeneticMarina Ivana MumpelNoch keine Bewertungen
- La Souris, La Mouche Et L'Homme A. Human Genome Project: B. DNA Computers/DNA Nanorobots: C. PhylogenomicsDokument12 SeitenLa Souris, La Mouche Et L'Homme A. Human Genome Project: B. DNA Computers/DNA Nanorobots: C. PhylogenomicsFadhili DungaNoch keine Bewertungen
- 3.3 & 7.1 DNA Structure HL Caitlin WORDDokument4 Seiten3.3 & 7.1 DNA Structure HL Caitlin WORDCaitlin BarrettNoch keine Bewertungen
- Inside our cells: A journey from DNA to proteinsDokument9 SeitenInside our cells: A journey from DNA to proteinsshamu081Noch keine Bewertungen
- Unit 5.1 DNA ReplicationDokument7 SeitenUnit 5.1 DNA ReplicationDaniel SinyangweNoch keine Bewertungen
- PCR Used to Generate DNA Fingerprints from Blood EvidenceDokument12 SeitenPCR Used to Generate DNA Fingerprints from Blood EvidenceTAUZIAH SUFINoch keine Bewertungen
- DNA Structure and FunctionDokument42 SeitenDNA Structure and FunctionMohak KumarNoch keine Bewertungen
- BTG 343 Molecular Genetics NoteDokument10 SeitenBTG 343 Molecular Genetics NoteEdith ChinazaNoch keine Bewertungen
- The Role of Dna Profiling in Criminal InvestigationDokument8 SeitenThe Role of Dna Profiling in Criminal InvestigationrahulNoch keine Bewertungen
- 12 2 PWPT PDFDokument24 Seiten12 2 PWPT PDFapi-262378640Noch keine Bewertungen
- Genetics & DnaDokument14 SeitenGenetics & DnaSyahira HozamiNoch keine Bewertungen
- PresentationDokument3 SeitenPresentationlilyNoch keine Bewertungen
- Dna ANDYDokument12 SeitenDna ANDYAndy Morales100% (1)
- SodapdfDokument49 SeitenSodapdffaheem.ashrafNoch keine Bewertungen
- of 18 September 2013Dokument17 Seitenof 18 September 2013Jean-claude PerezNoch keine Bewertungen
- Chapter 3.2 MB DNA StruDokument62 SeitenChapter 3.2 MB DNA StruMustee TeferaNoch keine Bewertungen
- MC Simulation of Radiation-Induced DNA Double Strand BreaksDokument12 SeitenMC Simulation of Radiation-Induced DNA Double Strand BreaksChloe FanningNoch keine Bewertungen
- Dna Replication in ProkaryotesDokument10 SeitenDna Replication in ProkaryotesLekshmyNoch keine Bewertungen
- DNA Topology Supercoiling and Linking PDFDokument5 SeitenDNA Topology Supercoiling and Linking PDFmanoj_rkl_07Noch keine Bewertungen
- Sliced PDF CompressedDokument49 SeitenSliced PDF Compressedfaheem.ashrafNoch keine Bewertungen
- SLG Chem 3 LG 5.7 Review of Nucleic Acids Structure and Functions (Part II)Dokument8 SeitenSLG Chem 3 LG 5.7 Review of Nucleic Acids Structure and Functions (Part II)franzachilleslindayagNoch keine Bewertungen
- 12BioCh6 Revision NoteDokument6 Seiten12BioCh6 Revision NoteAnsh SahuNoch keine Bewertungen
- Molecular BiologyDokument20 SeitenMolecular BiologyDaphne CuaresmaNoch keine Bewertungen
- Nucleic Acids ChemistryDokument68 SeitenNucleic Acids ChemistryAlok DhelditNoch keine Bewertungen
- The Mathematics of DNA Sturcture Mechanics and DynDokument29 SeitenThe Mathematics of DNA Sturcture Mechanics and Dynnero daunaxilNoch keine Bewertungen
- Unit-Ii Asm 2022-23Dokument33 SeitenUnit-Ii Asm 2022-23AnshnuNoch keine Bewertungen
- DNA and RNA Worksheet GuideDokument4 SeitenDNA and RNA Worksheet GuideH DNoch keine Bewertungen
- Nucleic AcidsDokument3 SeitenNucleic AcidsBio Sciences100% (2)
- Watson and Crick Model of DNADokument22 SeitenWatson and Crick Model of DNAGanesh V Gaonkar100% (1)
- Notes - Dna Protein Synthesis - Student 2000Dokument14 SeitenNotes - Dna Protein Synthesis - Student 2000api-270403367Noch keine Bewertungen
- SR - No Topic Page No.: Dna Computer 1 IndexDokument30 SeitenSR - No Topic Page No.: Dna Computer 1 Indexaanad003Noch keine Bewertungen
- Nucleic Acids.Dokument18 SeitenNucleic Acids.kasingabalyaandrewNoch keine Bewertungen
- Biology Canadian Canadian 2nd Edition Brooker Solutions Manual DownloadDokument7 SeitenBiology Canadian Canadian 2nd Edition Brooker Solutions Manual DownloadLanelle Leland100% (23)
- Epigenetics Topic GuideDokument16 SeitenEpigenetics Topic GuideRidwan AbrarNoch keine Bewertungen
- The New Central Dogma of Molecular Biology: March 2020Dokument33 SeitenThe New Central Dogma of Molecular Biology: March 2020Angelina KobanNoch keine Bewertungen
- Quantum Algorithms Explain Genetic Code NumbersDokument11 SeitenQuantum Algorithms Explain Genetic Code NumbersTarun SharmaNoch keine Bewertungen
- Dna ReplicationDokument37 SeitenDna ReplicationSyamala Natarajan100% (1)
- ReplicationDokument16 SeitenReplicationRakshit SharmaNoch keine Bewertungen
- Background of GeneticsDokument23 SeitenBackground of GeneticsvubioNoch keine Bewertungen
- Chapter Summary: Chapter 4: The Structure and Function of GenesDokument26 SeitenChapter Summary: Chapter 4: The Structure and Function of GenesmongguNoch keine Bewertungen
- DNA ReplicationDokument16 SeitenDNA ReplicationAbhishek AryaNoch keine Bewertungen
- DNA ReplicationDokument6 SeitenDNA ReplicationGeorge TarraNoch keine Bewertungen
- Study Guide BiologyDokument8 SeitenStudy Guide BiologyBayron SaucedaNoch keine Bewertungen
- DNA Fractal Golden RatioDokument13 SeitenDNA Fractal Golden RatioNoospherenautNoch keine Bewertungen
- DNA FingerprintingDokument33 SeitenDNA FingerprintingTaha Hussain Alasadi25% (4)
- Chapter 7: Nucleic Acids: 7.1: DNA Structure and ReplicationDokument5 SeitenChapter 7: Nucleic Acids: 7.1: DNA Structure and ReplicationMariamNoch keine Bewertungen
- 1 - Introduction of GenomeDokument4 Seiten1 - Introduction of GenomeALNAKINoch keine Bewertungen
- MIT Computational Biology course covers gene finding, alignment, assemblyDokument201 SeitenMIT Computational Biology course covers gene finding, alignment, assemblyBruno MartinsNoch keine Bewertungen
- Molecular BiologyDokument113 SeitenMolecular Biologytummalapalli venkateswara rao80% (10)
- How Genes WorkDokument47 SeitenHow Genes WorkJelly Joy CampomayorNoch keine Bewertungen
- Bioinformatics—the meaning and essential conceptsDokument11 SeitenBioinformatics—the meaning and essential conceptshesham12345Noch keine Bewertungen
- Lesson-3 Protein-Synthesis WorksheetDokument10 SeitenLesson-3 Protein-Synthesis WorksheetEnriquez, Hannah Roniella R.Noch keine Bewertungen
- Introduction to Bioinformatics, Sequence and Genome AnalysisVon EverandIntroduction to Bioinformatics, Sequence and Genome AnalysisNoch keine Bewertungen
- Vol1Iss207 - 5.keaney (p.28-36)Dokument9 SeitenVol1Iss207 - 5.keaney (p.28-36)supervenienceNoch keine Bewertungen
- Why Every Theory of Luck is WrongDokument19 SeitenWhy Every Theory of Luck is WrongsupervenienceNoch keine Bewertungen
- Duguid GraphThepryAndTheIdentityOfIndiscerniblesDokument11 SeitenDuguid GraphThepryAndTheIdentityOfIndiscerniblessupervenienceNoch keine Bewertungen
- Englebretsen DoWeNeedRelativeIdentity?Dokument3 SeitenEnglebretsen DoWeNeedRelativeIdentity?supervenienceNoch keine Bewertungen
- Jacquette TuringDokument24 SeitenJacquette TuringsupervenienceNoch keine Bewertungen
- Intro: 1.1 Simple Java ApplicationDokument6 SeitenIntro: 1.1 Simple Java ApplicationJosep Vañó ChicNoch keine Bewertungen
- Frege's Theory of Sense and Reference: Some Exegetical NotesDokument38 SeitenFrege's Theory of Sense and Reference: Some Exegetical NotessupervenienceNoch keine Bewertungen
- Symmetrical Universes and The Identity of IndiscerniblesDokument15 SeitenSymmetrical Universes and The Identity of IndiscerniblessupervenienceNoch keine Bewertungen
- Della Rocca - TwoSphereTwentyPheresAndTheIdentityOfIndiscerniblesDokument13 SeitenDella Rocca - TwoSphereTwentyPheresAndTheIdentityOfIndiscerniblessupervenienceNoch keine Bewertungen
- Preface 2003 JavaDokument2 SeitenPreface 2003 JavasupervenienceNoch keine Bewertungen
- Béziau WhatIsThePrincipleOfIdentity?Dokument10 SeitenBéziau WhatIsThePrincipleOfIdentity?supervenienceNoch keine Bewertungen
- Fine'S Mctaggart: Reloaded: Roberto LossDokument31 SeitenFine'S Mctaggart: Reloaded: Roberto LosssupervenienceNoch keine Bewertungen
- W F W I R T - V ?: by Jean-Yves BéziauDokument8 SeitenW F W I R T - V ?: by Jean-Yves BéziausupervenienceNoch keine Bewertungen
- Mind Association explores puzzles of identityDokument23 SeitenMind Association explores puzzles of identitysupervenienceNoch keine Bewertungen
- Which Quantifiers are Truly LogicalDokument17 SeitenWhich Quantifiers are Truly LogicalsupervenienceNoch keine Bewertungen
- The Real World Regained? Searle'S External Realism Examined: Douglas McdermidDokument9 SeitenThe Real World Regained? Searle'S External Realism Examined: Douglas McdermidsupervenienceNoch keine Bewertungen
- Artificial LanguageDokument23 SeitenArtificial LanguagesupervenienceNoch keine Bewertungen
- Paradoxes and DiagonalizationDokument15 SeitenParadoxes and DiagonalizationsupervenienceNoch keine Bewertungen
- What Do WeDokument22 SeitenWhat Do WesupervenienceNoch keine Bewertungen
- KayeDokument15 SeitenKayesupervenienceNoch keine Bewertungen
- Blameless WrongdoingDokument21 SeitenBlameless WrongdoingsupervenienceNoch keine Bewertungen
- RP 1 4Dokument10 SeitenRP 1 4supervenienceNoch keine Bewertungen
- Mind AssociationDokument19 SeitenMind AssociationsupervenienceNoch keine Bewertungen
- On Proving Functional Incompleteness in Symbolic Logic ClassesDokument14 SeitenOn Proving Functional Incompleteness in Symbolic Logic ClassessupervenienceNoch keine Bewertungen
- On Proving Functional Incompleteness in Symbolic Logic ClassesDokument14 SeitenOn Proving Functional Incompleteness in Symbolic Logic ClassessupervenienceNoch keine Bewertungen
- MetaDokument11 SeitenMetasupervenienceNoch keine Bewertungen
- On Proving Functional Incompleteness in Symbolic Logic ClassesDokument14 SeitenOn Proving Functional Incompleteness in Symbolic Logic ClassessupervenienceNoch keine Bewertungen
- Making Time: A Study in The Epistemology of Measurement: Eran TalDokument39 SeitenMaking Time: A Study in The Epistemology of Measurement: Eran TalsupervenienceNoch keine Bewertungen
- Wittgenstein Logical FormDokument6 SeitenWittgenstein Logical FormsupervenienceNoch keine Bewertungen
- Logica2007 Schroeder-Heister EsslliDokument12 SeitenLogica2007 Schroeder-Heister EssllisupervenienceNoch keine Bewertungen
- Acl Data Analytics EbookDokument14 SeitenAcl Data Analytics Ebookcassiemanok01Noch keine Bewertungen
- Adjustment and Impulse Control DisordersDokument19 SeitenAdjustment and Impulse Control DisordersArchana50% (4)
- Bimbo Marketing ResearchDokument27 SeitenBimbo Marketing Researcheman.konsouhNoch keine Bewertungen
- Peptan - All About Collagen Booklet-1Dokument10 SeitenPeptan - All About Collagen Booklet-1Danu AhmadNoch keine Bewertungen
- CHECK LIST FOR HIGH RISE BUILDING NOCDokument15 SeitenCHECK LIST FOR HIGH RISE BUILDING NOCNedunuri.Madhav Murthy100% (2)
- Stress-Busting Plan for Life's ChallengesDokument3 SeitenStress-Busting Plan for Life's Challengesliera sicadNoch keine Bewertungen
- EAPP Module 5Dokument10 SeitenEAPP Module 5Ma. Khulyn AlvarezNoch keine Bewertungen
- Etoposide JurnalDokument6 SeitenEtoposide JurnalShalie VhiantyNoch keine Bewertungen
- Modul English For Study SkillsDokument9 SeitenModul English For Study SkillsRazan Nuhad Dzulfaqor razannuhad.2020Noch keine Bewertungen
- Pyrolysis ProjectDokument122 SeitenPyrolysis ProjectSohel Bangi100% (1)
- Thesis PromptsDokument7 SeitenThesis Promptsauroratuckernewyork100% (2)
- Film set safety rules for COVIDDokument12 SeitenFilm set safety rules for COVIDTanveer HossainNoch keine Bewertungen
- Range of Muscle Work.Dokument54 SeitenRange of Muscle Work.Salman KhanNoch keine Bewertungen
- 11.trouble Shooting For TMDokument9 Seiten11.trouble Shooting For TMfrezgi birhanuNoch keine Bewertungen
- NCERT Solutions For Class 12 Flamingo English Lost SpringDokument20 SeitenNCERT Solutions For Class 12 Flamingo English Lost SpringHarsh solutions100% (1)
- Mapúa Welding Shop PracticeDokument7 SeitenMapúa Welding Shop PracticeJay EmNoch keine Bewertungen
- Eco 301 Final Exam ReviewDokument14 SeitenEco 301 Final Exam ReviewCảnh DươngNoch keine Bewertungen
- X TensoqaDokument2 SeitenX TensoqaLeo CabelosNoch keine Bewertungen
- The Seasons of Life by Jim RohnDokument111 SeitenThe Seasons of Life by Jim RohnChristine Mwaura97% (29)
- LSAP 423 Tech Data 25kVA-40KVA - 3PH 400VDokument1 SeiteLSAP 423 Tech Data 25kVA-40KVA - 3PH 400Vrooies13Noch keine Bewertungen
- Master of Advanced Nursing Practice degreeDokument2 SeitenMaster of Advanced Nursing Practice degreeAgusfian Trima PutraNoch keine Bewertungen
- SPH3U Formula SheetDokument2 SeitenSPH3U Formula SheetJSNoch keine Bewertungen
- Encrypt and decrypt a file using AESDokument5 SeitenEncrypt and decrypt a file using AESShaunak bagadeNoch keine Bewertungen
- Health Benefits of Kidney BeansDokument17 SeitenHealth Benefits of Kidney BeansShyneAneeshNoch keine Bewertungen
- Family Culture and Traditions PaperDokument7 SeitenFamily Culture and Traditions PaperAmit JindalNoch keine Bewertungen
- Mechanics of Materials: Combined StressesDokument3 SeitenMechanics of Materials: Combined StressesUmut Enes SürücüNoch keine Bewertungen
- Theories of Translation12345Dokument22 SeitenTheories of Translation12345Ishrat FatimaNoch keine Bewertungen
- JASA SREVIS LAPTOP Dan KOMPUTERDokument2 SeitenJASA SREVIS LAPTOP Dan KOMPUTERindimideaNoch keine Bewertungen
- Inbound 8511313797200267098Dokument10 SeitenInbound 8511313797200267098phan42Noch keine Bewertungen
- RRC Igc1Dokument6 SeitenRRC Igc1kabirNoch keine Bewertungen