Das könnte Ihnen auch gefallen
- Medical Device Reporting System A Complete Guide - 2020 EditionVon EverandMedical Device Reporting System A Complete Guide - 2020 EditionNoch keine Bewertungen
- SDTM aCRF Guideline: Guideline For SDTM Annotations in Case Report FormsDokument46 SeitenSDTM aCRF Guideline: Guideline For SDTM Annotations in Case Report Formspathuri rangaNoch keine Bewertungen
- ML SasDokument17 SeitenML SasmartdiazNoch keine Bewertungen
- RSTUDIODokument44 SeitenRSTUDIOsamarth agarwalNoch keine Bewertungen
- Exploring Sas ViyaDokument78 SeitenExploring Sas ViyaAlexandre AlvesNoch keine Bewertungen
- STATS LAB Basics of R PDFDokument77 SeitenSTATS LAB Basics of R PDFAnanthu SajithNoch keine Bewertungen
- Dplyr TutorialDokument22 SeitenDplyr TutorialDamini KapoorNoch keine Bewertungen
- 9B BMGT 220 THEORY of ESTIMATION 2Dokument4 Seiten9B BMGT 220 THEORY of ESTIMATION 2Pamela ChimwaniNoch keine Bewertungen
- Advanced SAS 9 ExamPrep SritejGuntaDokument60 SeitenAdvanced SAS 9 ExamPrep SritejGuntasriteja100% (3)
- Sas Clinical Data Integration Fact SheetDokument4 SeitenSas Clinical Data Integration Fact SheetChandrasekhar KothamasuNoch keine Bewertungen
- Advanced StatisticsDokument6 SeitenAdvanced StatisticsParakokwaNoch keine Bewertungen
- Question and Answers For PyplotsDokument11 SeitenQuestion and Answers For PyplotsPrakhar KumarNoch keine Bewertungen
- A Beginner's Notes On Bayesian Econometrics (Art)Dokument21 SeitenA Beginner's Notes On Bayesian Econometrics (Art)amerdNoch keine Bewertungen
- Exploratory Data Analysis Using PythonDokument10 SeitenExploratory Data Analysis Using Pythonmy pcNoch keine Bewertungen
- SAS PresentationDokument49 SeitenSAS PresentationVarun JainNoch keine Bewertungen
- Questions and Answers: SAS Institute A00-240Dokument5 SeitenQuestions and Answers: SAS Institute A00-240jitswankhede3066Noch keine Bewertungen
- R Language 1st Unit DeepDokument61 SeitenR Language 1st Unit DeepIt's Me100% (1)
- JMPDokument8 SeitenJMPgtmangozhoNoch keine Bewertungen
- Propensity Score Methods Using SASDokument37 SeitenPropensity Score Methods Using SASravigupta82Noch keine Bewertungen
- Linear Regression PDFDokument16 SeitenLinear Regression PDFapi-540582672100% (1)
- MTCARS Regression AnalysisDokument5 SeitenMTCARS Regression AnalysisErick Costa de FariasNoch keine Bewertungen
- Job - Opening in Accenture For Clinical SAS-Mumbai - Mumbai - Accenture - 2-To-7 Years of Experience - Jobs IndiaDokument3 SeitenJob - Opening in Accenture For Clinical SAS-Mumbai - Mumbai - Accenture - 2-To-7 Years of Experience - Jobs IndiaAlok YadavNoch keine Bewertungen
- Notes On ARIMA: ND RDDokument4 SeitenNotes On ARIMA: ND RDSri NeogiNoch keine Bewertungen
- SAS Cluster Project ReportDokument24 SeitenSAS Cluster Project ReportBiazi100% (1)
- AI Using PythonDokument9 SeitenAI Using Pythonscode networkNoch keine Bewertungen
- Minitab-2003-Software ValidationDokument11 SeitenMinitab-2003-Software ValidationGonzalo_Rojas_VerenzNoch keine Bewertungen
- PAT For TabletingDokument8 SeitenPAT For Tabletingmanthan212Noch keine Bewertungen
- Logistic RegressionDokument21 SeitenLogistic Regressioncvrpraveen100% (1)
- BookSlides 5B Similarity Based LearningDokument69 SeitenBookSlides 5B Similarity Based LearningMba NaniNoch keine Bewertungen
- CDISC Guidelines For Annotating CRFDokument32 SeitenCDISC Guidelines For Annotating CRFSatthi BandaruNoch keine Bewertungen
- SAS Macros Questions: Srikanth Potukuchi January 19, 2015Dokument16 SeitenSAS Macros Questions: Srikanth Potukuchi January 19, 2015srikanthNoch keine Bewertungen
- Health Insurance Cost Prediction Using IBM WatsonDokument27 SeitenHealth Insurance Cost Prediction Using IBM WatsonRayapati NagamaniNoch keine Bewertungen
- A00 212Dokument3 SeitenA00 212Ketaki KulkarniNoch keine Bewertungen
- SAS Dumps For Base SAS 9 ExamDokument10 SeitenSAS Dumps For Base SAS 9 Examvikrants1306Noch keine Bewertungen
- Sas Stat DumpsDokument39 SeitenSas Stat Dumpsakash100% (1)
- Data Validation, Processing, and Reporting Data ValidationDokument8 SeitenData Validation, Processing, and Reporting Data ValidationNaga Ajay Kumar DintakurthiNoch keine Bewertungen
- 2019 Migration GuideDokument20 Seiten2019 Migration GuidesuprabhattNoch keine Bewertungen
- Handleiding Spss Multinomial Logit RegressionDokument35 SeitenHandleiding Spss Multinomial Logit RegressionbartvansantenNoch keine Bewertungen
- SAS MacrosDokument6 SeitenSAS MacroshimaNoch keine Bewertungen
- 11g SQL Fundamentals D49988GC20 1080544 USDokument5 Seiten11g SQL Fundamentals D49988GC20 1080544 USNirnay SharmaNoch keine Bewertungen
- Ensemble Techniques ProjectDokument28 SeitenEnsemble Techniques ProjectVishweshRaviShrimali100% (2)
- My ML Lab ManualDokument21 SeitenMy ML Lab ManualAnonymous qZP5Zyb2Noch keine Bewertungen
- Praxis CSV BasicsDokument17 SeitenPraxis CSV BasicsNitin KashyapNoch keine Bewertungen
- Multiple RegressionDokument12 SeitenMultiple Regressionkuashask2Noch keine Bewertungen
- MYCINDokument5 SeitenMYCINsaurabh3112vermaNoch keine Bewertungen
- Problem: # PartitionDokument5 SeitenProblem: # Partitionpavan adapalaNoch keine Bewertungen
- Research Methods & Reporting: STARD 2015: An Updated List of Essential Items For Reporting Diagnostic Accuracy StudiesDokument9 SeitenResearch Methods & Reporting: STARD 2015: An Updated List of Essential Items For Reporting Diagnostic Accuracy StudiesJorge Villoslada Terrones100% (1)
- Sas Sentiment Analysis 104357Dokument4 SeitenSas Sentiment Analysis 104357Rocío VázquezNoch keine Bewertungen
- Data Visualization Using RDokument26 SeitenData Visualization Using Rshiva shangariNoch keine Bewertungen
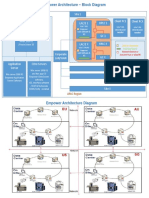
- Empower ArchitectureDokument2 SeitenEmpower ArchitecturePinaki ChakrabortyNoch keine Bewertungen
- R LnaguagerDokument38 SeitenR LnaguagerdwrreNoch keine Bewertungen
- 3604sas Base & Advanced Course ContentDokument14 Seiten3604sas Base & Advanced Course Contentクマー ヴィーンNoch keine Bewertungen
- 2 Probability and StatisticsDokument3 Seiten2 Probability and StatisticsJoy Dacuan100% (1)
- CSV WebinarDokument22 SeitenCSV WebinarNeusa RavarotoNoch keine Bewertungen
- C Disc ExpressDokument31 SeitenC Disc ExpressupendernathiNoch keine Bewertungen
- MappingDokument34 SeitenMappingboggalaNoch keine Bewertungen
- Wayahead System ValidationDokument41 SeitenWayahead System Validationpate malabananNoch keine Bewertungen
- Rmarkdown Cheatsheet 2.0 PDFDokument2 SeitenRmarkdown Cheatsheet 2.0 PDFAnto PadaunanNoch keine Bewertungen
- Unit1 ML ProgramsDokument5 SeitenUnit1 ML Programsdiroja5648Noch keine Bewertungen
- Statistical Learning in RDokument31 SeitenStatistical Learning in RAngela IvanovaNoch keine Bewertungen
- Guesstimate SDokument2 SeitenGuesstimate SArvind NANDAN SINGHNoch keine Bewertungen
- Important Guesstimates PDFDokument15 SeitenImportant Guesstimates PDFnakulsehgal08Noch keine Bewertungen
- Mergers & Acquisitions: FINC 446 Financial Decision Making Dr. Olgun Fuat SahinDokument29 SeitenMergers & Acquisitions: FINC 446 Financial Decision Making Dr. Olgun Fuat SahinArvind NANDAN SINGHNoch keine Bewertungen
- Mergers & Acquisitions: FINC 446 Financial Decision Making Dr. Olgun Fuat SahinDokument29 SeitenMergers & Acquisitions: FINC 446 Financial Decision Making Dr. Olgun Fuat SahinArvind NANDAN SINGHNoch keine Bewertungen
- Review of Literature: DOI: 10.4236/tel.2018.85052 Theoretical Economics LettersDokument13 SeitenReview of Literature: DOI: 10.4236/tel.2018.85052 Theoretical Economics LettersArvind NANDAN SINGHNoch keine Bewertungen
- Patagonia: Group 11 Saksham - Arvind - Lakshya - Aniket - GouravDokument12 SeitenPatagonia: Group 11 Saksham - Arvind - Lakshya - Aniket - GouravArvind NANDAN SINGHNoch keine Bewertungen
- Detection of Stored-Grain Insects Using Deep LearningDokument7 SeitenDetection of Stored-Grain Insects Using Deep LearningtrevNoch keine Bewertungen
- Linear Regression For Machine LearningDokument17 SeitenLinear Regression For Machine LearningJohn GreenNoch keine Bewertungen
- Python Tutorial For Students Machine Learning Course HolzingerDokument46 SeitenPython Tutorial For Students Machine Learning Course HolzingerAnonymous LBE9B7q9tU100% (1)
- Image Generation From CaptionDokument10 SeitenImage Generation From CaptionijscaiNoch keine Bewertungen
- Thesis Svanwouw FinalDokument86 SeitenThesis Svanwouw Finalthak123Noch keine Bewertungen
- Physics-Based Learning Models For Ship HydrodynamicsDokument22 SeitenPhysics-Based Learning Models For Ship HydrodynamicssintiaNoch keine Bewertungen
- Gluon Tutorials: Deep Learning - The Straight DopeDokument403 SeitenGluon Tutorials: Deep Learning - The Straight Dopedoosik71Noch keine Bewertungen
- Neurl 231 NetDokument219 SeitenNeurl 231 NetIamINNoch keine Bewertungen
- MLDokument8 SeitenMLankitNoch keine Bewertungen
- Sample Final AIDokument9 SeitenSample Final AIDavid LeNoch keine Bewertungen
- LTSM ModelDokument5 SeitenLTSM ModelIshan SaneNoch keine Bewertungen
- Research PaperDokument12 SeitenResearch Papervinayaka1728Noch keine Bewertungen
- Crime Hotspot Prediction Using Machine Learning v4Dokument20 SeitenCrime Hotspot Prediction Using Machine Learning v4api-431963966Noch keine Bewertungen
- Strategy LearnerDokument5 SeitenStrategy LearnertonyNoch keine Bewertungen
- cs229 2Dokument275 Seitencs229 2Andi GengNoch keine Bewertungen
- User GuideDokument29 SeitenUser GuideAdi DanuNoch keine Bewertungen
- Fake News DetectionDokument71 SeitenFake News DetectionHassan Sultan40% (10)
- Cs 229, Autumn 2016 Problem Set #2: Naive Bayes, SVMS, and TheoryDokument20 SeitenCs 229, Autumn 2016 Problem Set #2: Naive Bayes, SVMS, and TheoryZeeshan Ali SayyedNoch keine Bewertungen
- 6036 Lecture NotesDokument56 Seiten6036 Lecture NotesMatt StapleNoch keine Bewertungen
- Ensemble Based Learning With Stacking, Boosting and Bagging For Unimodal Biometric Identification SystemDokument6 SeitenEnsemble Based Learning With Stacking, Boosting and Bagging For Unimodal Biometric Identification SystemsuppiNoch keine Bewertungen
- How To Use Batch Normalization With TensorFlow and TF - Keras To Train Deep Neural Networks FasterDokument11 SeitenHow To Use Batch Normalization With TensorFlow and TF - Keras To Train Deep Neural Networks FastersusanNoch keine Bewertungen
- Random Forest 2001Dokument16 SeitenRandom Forest 2001Chaitanya BhargavNoch keine Bewertungen
- Fisher Ratio EEGDokument4 SeitenFisher Ratio EEGBudi SetyawanNoch keine Bewertungen
- Data Mining - Weka 3.6.0Dokument5 SeitenData Mining - Weka 3.6.0Navee JayakodyNoch keine Bewertungen
- Analytical LearningDokument42 SeitenAnalytical LearningLikhitah GottipatiNoch keine Bewertungen
- Character Recognition: Handwritten Character Recognition: Training A Simple NN For Classification Using MATLABDokument12 SeitenCharacter Recognition: Handwritten Character Recognition: Training A Simple NN For Classification Using MATLABAman BhardwajNoch keine Bewertungen
- Fast Ai PDFDokument11 SeitenFast Ai PDFfolioxNoch keine Bewertungen
- ML GlossaryDokument44 SeitenML GlossaryLakshya PriyadarshiNoch keine Bewertungen
- UPB HES SO at PlantCLEF 2017 Automatic Plant Image Identification Using Transfer Learning Via Convolutional Neural NetworksDokument9 SeitenUPB HES SO at PlantCLEF 2017 Automatic Plant Image Identification Using Transfer Learning Via Convolutional Neural NetworksAnonymous ntIcRwM55RNoch keine Bewertungen
- 100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziVon Everand100M Offers Made Easy: Create Your Own Irresistible Offers by Turning ChatGPT into Alex HormoziNoch keine Bewertungen
- ChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveVon EverandChatGPT Side Hustles 2024 - Unlock the Digital Goldmine and Get AI Working for You Fast with More Than 85 Side Hustle Ideas to Boost Passive Income, Create New Cash Flow, and Get Ahead of the CurveNoch keine Bewertungen
- Generative AI: The Insights You Need from Harvard Business ReviewVon EverandGenerative AI: The Insights You Need from Harvard Business ReviewBewertung: 4.5 von 5 Sternen4.5/5 (2)
- Scary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldVon EverandScary Smart: The Future of Artificial Intelligence and How You Can Save Our WorldBewertung: 4.5 von 5 Sternen4.5/5 (55)
- HBR's 10 Must Reads on AI, Analytics, and the New Machine AgeVon EverandHBR's 10 Must Reads on AI, Analytics, and the New Machine AgeBewertung: 4.5 von 5 Sternen4.5/5 (69)
- ChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindVon EverandChatGPT Money Machine 2024 - The Ultimate Chatbot Cheat Sheet to Go From Clueless Noob to Prompt Prodigy Fast! Complete AI Beginner’s Course to Catch the GPT Gold Rush Before It Leaves You BehindNoch keine Bewertungen
- Mastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)Von EverandMastering Large Language Models: Advanced techniques, applications, cutting-edge methods, and top LLMs (English Edition)Noch keine Bewertungen
- Four Battlegrounds: Power in the Age of Artificial IntelligenceVon EverandFour Battlegrounds: Power in the Age of Artificial IntelligenceBewertung: 5 von 5 Sternen5/5 (5)
- The Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldVon EverandThe Master Algorithm: How the Quest for the Ultimate Learning Machine Will Remake Our WorldBewertung: 4.5 von 5 Sternen4.5/5 (107)
- Artificial Intelligence: The Insights You Need from Harvard Business ReviewVon EverandArtificial Intelligence: The Insights You Need from Harvard Business ReviewBewertung: 4.5 von 5 Sternen4.5/5 (104)
- Working with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)Von EverandWorking with AI: Real Stories of Human-Machine Collaboration (Management on the Cutting Edge)Bewertung: 5 von 5 Sternen5/5 (5)
- ChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessVon EverandChatGPT Millionaire 2024 - Bot-Driven Side Hustles, Prompt Engineering Shortcut Secrets, and Automated Income Streams that Print Money While You Sleep. The Ultimate Beginner’s Guide for AI BusinessNoch keine Bewertungen
- Who's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesVon EverandWho's Afraid of AI?: Fear and Promise in the Age of Thinking MachinesBewertung: 4.5 von 5 Sternen4.5/5 (13)
- Artificial Intelligence: A Guide for Thinking HumansVon EverandArtificial Intelligence: A Guide for Thinking HumansBewertung: 4.5 von 5 Sternen4.5/5 (30)
- Python Machine Learning - Third Edition: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2, 3rd EditionVon EverandPython Machine Learning - Third Edition: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow 2, 3rd EditionBewertung: 5 von 5 Sternen5/5 (2)
- Your AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsVon EverandYour AI Survival Guide: Scraped Knees, Bruised Elbows, and Lessons Learned from Real-World AI DeploymentsNoch keine Bewertungen
- Make Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryVon EverandMake Money with ChatGPT: Your Guide to Making Passive Income Online with Ease using AI: AI Wealth MasteryNoch keine Bewertungen
- A Brief History of Artificial Intelligence: What It Is, Where We Are, and Where We Are GoingVon EverandA Brief History of Artificial Intelligence: What It Is, Where We Are, and Where We Are GoingBewertung: 4.5 von 5 Sternen4.5/5 (3)
- T-Minus AI: Humanity's Countdown to Artificial Intelligence and the New Pursuit of Global PowerVon EverandT-Minus AI: Humanity's Countdown to Artificial Intelligence and the New Pursuit of Global PowerBewertung: 4 von 5 Sternen4/5 (4)
- The AI Advantage: How to Put the Artificial Intelligence Revolution to WorkVon EverandThe AI Advantage: How to Put the Artificial Intelligence Revolution to WorkBewertung: 4 von 5 Sternen4/5 (7)
- The Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsVon EverandThe Roadmap to AI Mastery: A Guide to Building and Scaling ProjectsNoch keine Bewertungen
- Hands-On System Design: Learn System Design, Scaling Applications, Software Development Design Patterns with Real Use-CasesVon EverandHands-On System Design: Learn System Design, Scaling Applications, Software Development Design Patterns with Real Use-CasesNoch keine Bewertungen
- System Design Interview: 300 Questions And Answers: Prepare And PassVon EverandSystem Design Interview: 300 Questions And Answers: Prepare And PassNoch keine Bewertungen
- Architects of Intelligence: The truth about AI from the people building itVon EverandArchitects of Intelligence: The truth about AI from the people building itBewertung: 4.5 von 5 Sternen4.5/5 (21)