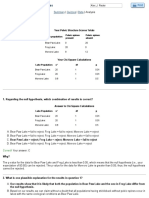
Das könnte Ihnen auch gefallen
- 2016 NASPSPA Abstract Supplement 6-15-16Dokument276 Seiten2016 NASPSPA Abstract Supplement 6-15-16Rakesh ThakurNoch keine Bewertungen
- Openness To Experience PDFDokument19 SeitenOpenness To Experience PDFandirjafcbNoch keine Bewertungen
- Are All Psychotherapies Created Equal - Scientific AmericanDokument4 SeitenAre All Psychotherapies Created Equal - Scientific AmericanPietro De SantisNoch keine Bewertungen
- Thesis OsteopathyDokument6 SeitenThesis Osteopathygbv8rcfq100% (1)
- Systematic Reviews and Meta-Analyses in The Orthopedic Literature: Assessment of The Current State of Quality and Proposal of A New Rating StrategyDokument7 SeitenSystematic Reviews and Meta-Analyses in The Orthopedic Literature: Assessment of The Current State of Quality and Proposal of A New Rating StrategyasclepiuspdfsNoch keine Bewertungen
- 2ND321 Educational StatisticsDokument19 Seiten2ND321 Educational StatisticsMary Rose GonzalesNoch keine Bewertungen
- Pearson - S RDokument39 SeitenPearson - S RRDNoch keine Bewertungen
- Eight Things You Need To Know About Interpreting CorrelationsDokument9 SeitenEight Things You Need To Know About Interpreting Correlationsprinz107Noch keine Bewertungen
- 1ststeps in Hyphothesis TestingDokument17 Seiten1ststeps in Hyphothesis TestingJhomar LatNoch keine Bewertungen
- Linear RegressionDokument28 SeitenLinear RegressionHajraNoch keine Bewertungen
- Correlation and RegressionDokument11 SeitenCorrelation and RegressiongdayanandamNoch keine Bewertungen
- Correlation and Regression: Predicting The UnknownDokument5 SeitenCorrelation and Regression: Predicting The Unknownzahoor80Noch keine Bewertungen
- Datasets - Bodyfat2 Fitness Newfitness Abdomenpred: Saseg 8B - Correlation AnalysisDokument34 SeitenDatasets - Bodyfat2 Fitness Newfitness Abdomenpred: Saseg 8B - Correlation AnalysisShreyansh SethNoch keine Bewertungen
- Chapter9 PDFDokument28 SeitenChapter9 PDFnmukherjee20Noch keine Bewertungen
- Chapter 9Dokument28 SeitenChapter 9Aniket BatraNoch keine Bewertungen
- The Pattern of Data Is Indicative of The Type of Relationship Between Your Two VariablesDokument4 SeitenThe Pattern of Data Is Indicative of The Type of Relationship Between Your Two VariablesJenny PadillaNoch keine Bewertungen
- Module 6 RM: Advanced Data Analysis TechniquesDokument23 SeitenModule 6 RM: Advanced Data Analysis TechniquesEm JayNoch keine Bewertungen
- Quantitative Methods VocabularyDokument5 SeitenQuantitative Methods VocabularyRuxandra MănicaNoch keine Bewertungen
- Measures of RelationshipDokument17 SeitenMeasures of RelationshipJoffrey UrianNoch keine Bewertungen
- Statistics Regression Final ProjectDokument12 SeitenStatistics Regression Final ProjectHenry Pinolla100% (1)
- CH5.Correlational and Quasi-Experimental DesignsDokument43 SeitenCH5.Correlational and Quasi-Experimental DesignsNiel Ryan HizoleNoch keine Bewertungen
- Correlation CoefficientDokument11 SeitenCorrelation Coefficientdhiyaafr2000Noch keine Bewertungen
- SRMDokument6 SeitenSRMsidharthNoch keine Bewertungen
- Softstat Analysis BasicDokument10 SeitenSoftstat Analysis BasicDr See Kin HaiNoch keine Bewertungen
- Lab 4 InstructionsDokument11 SeitenLab 4 Instructionsapi-405320544Noch keine Bewertungen
- Module 010 - Correlation AnalysisDokument11 SeitenModule 010 - Correlation AnalysisIlovedocumintNoch keine Bewertungen
- CorregDokument19 SeitenCorregAna Fee TeringteringNoch keine Bewertungen
- Correlation Rev 1.0Dokument5 SeitenCorrelation Rev 1.0Ahmed M. HashimNoch keine Bewertungen
- Errors and Residuals: Correlation Vs RegressionDokument2 SeitenErrors and Residuals: Correlation Vs RegressionABIGAEL SURAFELNoch keine Bewertungen
- Correlation and Regression Feb2014Dokument50 SeitenCorrelation and Regression Feb2014Zeinab Goda100% (1)
- Statistical TestsDokument9 SeitenStatistical Testsalbao.elaine21Noch keine Bewertungen
- Correlation Research Design - PRESENTASIDokument62 SeitenCorrelation Research Design - PRESENTASIDiah Retno Widowati100% (1)
- Basic StatisticsDokument31 SeitenBasic Statisticsss_oo_nnNoch keine Bewertungen
- Correlation of StatisticsDokument6 SeitenCorrelation of StatisticsHans Christer RiveraNoch keine Bewertungen
- Pearson Correlation CoefficientDokument4 SeitenPearson Correlation CoefficientCheyenne CerenoNoch keine Bewertungen
- StatisticsDokument743 SeitenStatisticsmunish_tiwari2007100% (1)
- Predective Analytics or Inferential StatisticsDokument27 SeitenPredective Analytics or Inferential StatisticsMichaella PurgananNoch keine Bewertungen
- Chapter 9Dokument28 SeitenChapter 9Lombe MutonoNoch keine Bewertungen
- Chapter9 StatDokument28 SeitenChapter9 Statosama hasanNoch keine Bewertungen
- Dissertation BoxplotDokument8 SeitenDissertation BoxplotPaySomeoneToWriteMyPaperCanada100% (1)
- Sas ProcsDokument8 SeitenSas ProcsPrasad TvsnvNoch keine Bewertungen
- Econometrics Fianl Exam 2020 FahmiDokument4 SeitenEconometrics Fianl Exam 2020 FahmiNebiyu WoldesenbetNoch keine Bewertungen
- Af Notes by Midhila)Dokument60 SeitenAf Notes by Midhila)MIDHILA MANOJNoch keine Bewertungen
- Introduction: Hypothesis Testing Is A Formal Procedure For Investigating Our IdeasDokument7 SeitenIntroduction: Hypothesis Testing Is A Formal Procedure For Investigating Our IdeasRaven SlanderNoch keine Bewertungen
- TinuDokument5 SeitenTinutinsae kebedeNoch keine Bewertungen
- Factor AnalysisDokument14 SeitenFactor AnalysissamiratNoch keine Bewertungen
- Introduction To Correlation and Regression AnalysisDokument23 SeitenIntroduction To Correlation and Regression AnalysisshoaibNoch keine Bewertungen
- Beginner’s Guide to Correlation Analysis: Bite-Size Stats, #4Von EverandBeginner’s Guide to Correlation Analysis: Bite-Size Stats, #4Noch keine Bewertungen
- CorrelationDokument2 SeitenCorrelationRamadhan AbdullahNoch keine Bewertungen
- Report Statistical Technique in Decision Making (GROUP BPT) - Correlation & Linear Regression123Dokument20 SeitenReport Statistical Technique in Decision Making (GROUP BPT) - Correlation & Linear Regression123AlieffiacNoch keine Bewertungen
- Biostatistics (Correlation and Regression)Dokument29 SeitenBiostatistics (Correlation and Regression)Devyani Marathe100% (1)
- Kendall TauDokument8 SeitenKendall TauZenzen MiclatNoch keine Bewertungen
- CorrelationDokument12 SeitenCorrelationisabella343Noch keine Bewertungen
- Interpreting CorrelationDokument13 SeitenInterpreting CorrelationAnonymous AQ9cNmNoch keine Bewertungen
- What Is The Difference Between Correlation and Linear RegressionDokument6 SeitenWhat Is The Difference Between Correlation and Linear RegressionSandra DeeNoch keine Bewertungen
- Examine Correlation in DataDokument3 SeitenExamine Correlation in DataGowtham ThalluriNoch keine Bewertungen
- 11 Regression JASPDokument35 Seiten11 Regression JASPHeru Wiryanto100% (1)
- Pearsons PDFDokument8 SeitenPearsons PDFmekelewengNoch keine Bewertungen
- The Problem and Its BackgroundDokument46 SeitenThe Problem and Its BackgroundJane Sandoval100% (1)
- Test Bank For A First Course in Statistics 11 e 11th Edition 0321891929Dokument36 SeitenTest Bank For A First Course in Statistics 11 e 11th Edition 0321891929susangonzaleznmfkcitdwg100% (33)
- Data Science Training On Statistical Techniques For AnalyticsDokument154 SeitenData Science Training On Statistical Techniques For AnalyticsArun Kumar GNoch keine Bewertungen
- Statistics & Probability: Hypothesis Testing Z-TestDokument63 SeitenStatistics & Probability: Hypothesis Testing Z-TestKyla Aragon BersalonaNoch keine Bewertungen
- Community MCQDokument271 SeitenCommunity MCQمحسن حدوان عليخان0% (1)
- Large Sample Tests of HypothesisDokument44 SeitenLarge Sample Tests of HypothesistfuribeNoch keine Bewertungen
- Binomial DistributionDokument8 SeitenBinomial Distributionchandana19926290% (1)
- Nelson Plosser 1982Dokument24 SeitenNelson Plosser 1982patrullero1100% (1)
- IGNOU MBA Note On Statistics For ManagementDokument23 SeitenIGNOU MBA Note On Statistics For Managementravvig100% (2)
- Stickleback AnalysisDokument5 SeitenStickleback AnalysisAlec RederNoch keine Bewertungen
- Dr. Rabi N. Subudhi Professor, School of Management KIIT University BhubaneswarDokument20 SeitenDr. Rabi N. Subudhi Professor, School of Management KIIT University Bhubaneswarrajivaaf28Noch keine Bewertungen
- Science Investigatory ProjectDokument13 SeitenScience Investigatory ProjectImman Ray Loriezo AguilarNoch keine Bewertungen
- Module 4 Post TaskDokument9 SeitenModule 4 Post TaskTHEA BEATRICE GARCIA100% (1)
- FMOLS ModelDokument8 SeitenFMOLS Modelsaeed meoNoch keine Bewertungen
- Detailed Lesson Plan-Test of HypothesisDokument6 SeitenDetailed Lesson Plan-Test of HypothesisPatricia Marie100% (2)
- IE2152 Statistics For Industrial Engineers Problem Solving SessionsDokument57 SeitenIE2152 Statistics For Industrial Engineers Problem Solving SessionsKutay ArslanNoch keine Bewertungen
- StatProb11 Q4 Mod1 Tests-Of-Hypothesis Version2Dokument80 SeitenStatProb11 Q4 Mod1 Tests-Of-Hypothesis Version2aiza100% (9)
- STAT100 Fall19 Test 2 ANSWERS Practice Problems PDFDokument23 SeitenSTAT100 Fall19 Test 2 ANSWERS Practice Problems PDFabutiNoch keine Bewertungen
- Notes & Notes: Biostatistics & EBMDokument35 SeitenNotes & Notes: Biostatistics & EBMamhhospital0Noch keine Bewertungen
- Statand Prob Q4 M5Dokument16 SeitenStatand Prob Q4 M5Jessa Banawan EdulanNoch keine Bewertungen
- Statistics q4 Mod6 Computing Test Statistic On Population MeanDokument28 SeitenStatistics q4 Mod6 Computing Test Statistic On Population Meanmanuel aquinoNoch keine Bewertungen
- Mathematics in Modern WorldDokument30 SeitenMathematics in Modern WorldKim Nini100% (1)
- Statistics Analytics Hypothesis Testing Z Test T TestDokument14 SeitenStatistics Analytics Hypothesis Testing Z Test T TestMas Mentox'sNoch keine Bewertungen
- Chap2Lesson 1Dokument5 SeitenChap2Lesson 1Audrey Burato LopezNoch keine Bewertungen
- 3.2 - Hypothesis Testing (P-Value Approach)Dokument3 Seiten3.2 - Hypothesis Testing (P-Value Approach)Habib MradNoch keine Bewertungen
- Biostatistics 22003Dokument35 SeitenBiostatistics 22003god4alllNoch keine Bewertungen
- A Simplified Guide To Determination of Sample SizeDokument11 SeitenA Simplified Guide To Determination of Sample SizegaiktianNoch keine Bewertungen
- Hypothesis TestingDokument19 SeitenHypothesis TestingNei chimNoch keine Bewertungen
- Unit-4 Hypothesis - TestingDokument17 SeitenUnit-4 Hypothesis - TestingA2 MotivationNoch keine Bewertungen
- T-Test ProblemsDokument2 SeitenT-Test ProblemspunyasNoch keine Bewertungen