Das könnte Ihnen auch gefallen
- The Detective Was Investiga At6 O'clock Yesterday: Ms. Jaquelin Lavado EspirituDokument23 SeitenThe Detective Was Investiga At6 O'clock Yesterday: Ms. Jaquelin Lavado Espiritu02-AS-HU-KEVIN EDUARDO SALVATIERRA AGUADONoch keine Bewertungen
- Unit 5 Short Test 2A: GrammarDokument2 SeitenUnit 5 Short Test 2A: GrammarShavayen Goedhart33% (3)
- T-Gsa: Transformer With Gaussian-Weighted Self-Attention For Speech EnhancementDokument5 SeitenT-Gsa: Transformer With Gaussian-Weighted Self-Attention For Speech Enhancementshivam khandelwalNoch keine Bewertungen
- Deep Biaffine Attention For Neural Dependency ParsingDokument8 SeitenDeep Biaffine Attention For Neural Dependency ParsingThomas MaoNoch keine Bewertungen
- Natural Language Parsing Using Finite-State CascadesDokument8 SeitenNatural Language Parsing Using Finite-State CascadesMarabatalha McNoch keine Bewertungen
- Incrementality in Deterministic Dependency ParsingDokument8 SeitenIncrementality in Deterministic Dependency ParsingprogisNoch keine Bewertungen
- A Robust Shallow Parser For Swedish: Ola Knutsson, Johnny Bigert, Viggo KannDokument9 SeitenA Robust Shallow Parser For Swedish: Ola Knutsson, Johnny Bigert, Viggo KannAhadul IslamNoch keine Bewertungen
- A Vector Quantization Approach To Speaker RecognitionDokument4 SeitenA Vector Quantization Approach To Speaker RecognitionManoj Kumar MauryaNoch keine Bewertungen
- Linear PredictDokument14 SeitenLinear PredictFlavio Solano OrdinolaNoch keine Bewertungen
- Span-Based LCFRS-2 ParsingDokument11 SeitenSpan-Based LCFRS-2 ParsingmiloshstanojevicNoch keine Bewertungen
- Deterministic Non Determinstic CompilerDokument8 SeitenDeterministic Non Determinstic Compilerbukhari sydaNoch keine Bewertungen
- Text classification on unbalanced, sparse and noisy dataDokument8 SeitenText classification on unbalanced, sparse and noisy dataAman AgnihotriNoch keine Bewertungen
- Department of Computer Science and Engineering: A Technical Seminar OnDokument15 SeitenDepartment of Computer Science and Engineering: A Technical Seminar OnRaam Sai BharadwajNoch keine Bewertungen
- Generative Adversarial Learning For Robust Text Classification With A Bunch of Labeled ExamplesDokument6 SeitenGenerative Adversarial Learning For Robust Text Classification With A Bunch of Labeled ExamplesLarissa FelicianaNoch keine Bewertungen
- Part-Of-Speech Tagging of Swedish Texts in The Neural EraDokument10 SeitenPart-Of-Speech Tagging of Swedish Texts in The Neural EraalexberdNoch keine Bewertungen
- Automated Methods For The Comparison of Natural LaDokument11 SeitenAutomated Methods For The Comparison of Natural LamhamadNoch keine Bewertungen
- Multi-Representational Treebank for Hindi/UrduDokument4 SeitenMulti-Representational Treebank for Hindi/UrduRaziAhmedNoch keine Bewertungen
- Tjong Kim Sang 2000Dokument6 SeitenTjong Kim Sang 2000dhaowoodsNoch keine Bewertungen
- Sequence Labelling Using Stochastic Final State Transducers (SFSTS)Dokument5 SeitenSequence Labelling Using Stochastic Final State Transducers (SFSTS)Federico MarinelliNoch keine Bewertungen
- PREDICTING INTONATIONAL PHRASING FROM TEXTDokument8 SeitenPREDICTING INTONATIONAL PHRASING FROM TEXTAnonymous xo7GDeQNoch keine Bewertungen
- Description of The Tangora SystemDokument5 SeitenDescription of The Tangora SystemPatrick MooreNoch keine Bewertungen
- Gupta Et Al 2019 - Character-Based NMT With TransformerDokument16 SeitenGupta Et Al 2019 - Character-Based NMT With TransformermccccccNoch keine Bewertungen
- Conversion of Regular Expression to Finite AutomataDokument4 SeitenConversion of Regular Expression to Finite AutomataSuparna SinhaNoch keine Bewertungen
- (Conll06 Fin) - (Rens)Dokument8 Seiten(Conll06 Fin) - (Rens)Anónimo AnónimoNoch keine Bewertungen
- Dependencies vs. Constituents For Tree-Based Alignment: Daniel GildeaDokument8 SeitenDependencies vs. Constituents For Tree-Based Alignment: Daniel GildeaArief BaskoroNoch keine Bewertungen
- 1710 10467 PDFDokument5 Seiten1710 10467 PDFshamim miahNoch keine Bewertungen
- Prefix-Tuning: Optimizing Continuous Prompts For GenerationDokument15 SeitenPrefix-Tuning: Optimizing Continuous Prompts For GenerationcloudsmgNoch keine Bewertungen
- Presentasi AsmaDokument8 SeitenPresentasi AsmaDaniel PratamaNoch keine Bewertungen
- ASMA: A System For Automatic Segmentation and Morpho-Syntactic Disambiguation of Modern Standard ArabicDokument8 SeitenASMA: A System For Automatic Segmentation and Morpho-Syntactic Disambiguation of Modern Standard ArabicDaniel PratamaNoch keine Bewertungen
- A Simple LPC Vocoder Bob Beauchaine EE586, Spring 2004: Vocal Tract ModelingDokument12 SeitenA Simple LPC Vocoder Bob Beauchaine EE586, Spring 2004: Vocal Tract Modeling5866215Noch keine Bewertungen
- 2021 Mirror-Bert EmnlpDokument18 Seiten2021 Mirror-Bert Emnlprajesh716Noch keine Bewertungen
- 2022 Utterance by Utterance Overlap Aware Neural Diarization With Graph PITDokument5 Seiten2022 Utterance by Utterance Overlap Aware Neural Diarization With Graph PITMohammed NabilNoch keine Bewertungen
- Combining Multiple Estimators of Speaking Rate: Nelson Morgan and Eric Fosler-LussierDokument4 SeitenCombining Multiple Estimators of Speaking Rate: Nelson Morgan and Eric Fosler-LussierJustin_McManus_3939Noch keine Bewertungen
- An" Integrated Parser For TFG With Explicit Tree Typing: 1. LntroductionDokument4 SeitenAn" Integrated Parser For TFG With Explicit Tree Typing: 1. Lntroductioncuriousexplorer1mNoch keine Bewertungen
- A Data Oriented Parsing Model ForDokument8 SeitenA Data Oriented Parsing Model ForLucas BorgesNoch keine Bewertungen
- CS60010 Spring 2023 - Transformer Part 3 Pretraining ObjectivesDokument38 SeitenCS60010 Spring 2023 - Transformer Part 3 Pretraining Objectivesarpan singhNoch keine Bewertungen
- Darwinised Data-Oriented Parsing - Statistical NLP With Added Sex and DeathDokument7 SeitenDarwinised Data-Oriented Parsing - Statistical NLP With Added Sex and DeathDave CochranNoch keine Bewertungen
- Bird 2009Dokument2 SeitenBird 2009kamran ashrafNoch keine Bewertungen
- Modeling The Intonation of DiscourseDokument10 SeitenModeling The Intonation of DiscourseNelson Sousa Jr.Noch keine Bewertungen
- Bag of Tricks For Text ClassificationDokument5 SeitenBag of Tricks For Text ClassificationRahul JainNoch keine Bewertungen
- Z-Forcing: Training Stochastic Recurrent NetworksDokument11 SeitenZ-Forcing: Training Stochastic Recurrent NetworksSaurabh KulshreshthaNoch keine Bewertungen
- Fast and Accurate Neural CRF Constituency ParsingDokument8 SeitenFast and Accurate Neural CRF Constituency Parsing23520053 I Putu Eka Surya AdityaNoch keine Bewertungen
- Partially Ordered Multiset Context-Free Grammars and ID/LP ParsingDokument13 SeitenPartially Ordered Multiset Context-Free Grammars and ID/LP ParsingPebri JoinkunNoch keine Bewertungen
- A Critical Analysis of Performance and Efficiency of Minimization Algorithms For Deterministic Finite AutomataDokument4 SeitenA Critical Analysis of Performance and Efficiency of Minimization Algorithms For Deterministic Finite AutomataInternational Journal of Innovative Science and Research TechnologyNoch keine Bewertungen
- Inter-Annotator Agreement For A German Newspaper Corpus: Thorsten BrantsDokument5 SeitenInter-Annotator Agreement For A German Newspaper Corpus: Thorsten Brantsوديع القباطيNoch keine Bewertungen
- The At&t German Text-To-Speech System: Realistic Linguistic DescriptionDokument4 SeitenThe At&t German Text-To-Speech System: Realistic Linguistic DescriptionViktor ZipenjukNoch keine Bewertungen
- Stability and Performance Analysis of Pitch Filters in Speech CodersDokument10 SeitenStability and Performance Analysis of Pitch Filters in Speech CodersSevy Tom ZoriuqNoch keine Bewertungen
- The Prague Bulletin of Mathematical Linguistics A Linguistic Evaluation of Rule Based Phrase Based and Neural MT EnginesDokument13 SeitenThe Prague Bulletin of Mathematical Linguistics A Linguistic Evaluation of Rule Based Phrase Based and Neural MT EnginesYunus Emre CoşkunNoch keine Bewertungen
- Paper 3 PDFDokument8 SeitenPaper 3 PDFivinayakNoch keine Bewertungen
- Making Sense of Collocations: Leo Wanner, Bernd Bohnet, Mark GierethDokument16 SeitenMaking Sense of Collocations: Leo Wanner, Bernd Bohnet, Mark GierethmanjuNoch keine Bewertungen
- Probabilistic Latent Semantic Analysis: Thomas HofmannDokument8 SeitenProbabilistic Latent Semantic Analysis: Thomas Hofmannykcir6Noch keine Bewertungen
- Lect 11Dokument7 SeitenLect 11Randika PereraNoch keine Bewertungen
- Evaluating GRU and LSTM With Regularization On Translating Different Language PairsDokument7 SeitenEvaluating GRU and LSTM With Regularization On Translating Different Language PairsMoya MeiteiNoch keine Bewertungen
- Monaural Audio Source Separation using Variational AutoencodersDokument5 SeitenMonaural Audio Source Separation using Variational AutoencodersRahul KumarNoch keine Bewertungen
- Attention-Based Models For Text-Dependent Speaker Verification MorenoDokument5 SeitenAttention-Based Models For Text-Dependent Speaker Verification MorenoBidhan BaraiNoch keine Bewertungen
- Fractal Patterns May Unravel The Intelligence in Next-Token PredictionDokument15 SeitenFractal Patterns May Unravel The Intelligence in Next-Token PredictionMichael KowalNoch keine Bewertungen
- Dependency Parser ComparisonDokument10 SeitenDependency Parser ComparisonWii JonlyNoch keine Bewertungen
- End-To-End Graph-Based TAG Parsing With Neural NetworksDokument14 SeitenEnd-To-End Graph-Based TAG Parsing With Neural NetworksDavid Riquelme ReynaNoch keine Bewertungen
- Evaluating Word Order Recursively Over Permutation-ForestsDokument10 SeitenEvaluating Word Order Recursively Over Permutation-ForestsmiloshstanojevicNoch keine Bewertungen
- On The Compensation Between Magnitude and Phase in Speech SeparationDokument5 SeitenOn The Compensation Between Magnitude and Phase in Speech SeparationeliasKKNoch keine Bewertungen
- Analyzing overlapping speech and disfluencies in political interviewsDokument7 SeitenAnalyzing overlapping speech and disfluencies in political interviewsdesi indah nyiur amdNoch keine Bewertungen
- Rumus Passive Voice Pada 16 TensesDokument3 SeitenRumus Passive Voice Pada 16 TensesKrisna Hermawan Anugrah FadjarNoch keine Bewertungen
- Reported Speech 2021 WH Questions by English With SimoDokument1 SeiteReported Speech 2021 WH Questions by English With Simoمحمد رائدNoch keine Bewertungen
- Progress Test Level A2Dokument5 SeitenProgress Test Level A2Dobre CarmenNoch keine Bewertungen
- Present Perfect TenseDokument2 SeitenPresent Perfect TenseAslıhan GüneşNoch keine Bewertungen
- INTERJECTION - Docx HardDokument4 SeitenINTERJECTION - Docx HardJez ELNoch keine Bewertungen
- Syllabus Semantics (2018)Dokument2 SeitenSyllabus Semantics (2018)Oanh Nguyễn100% (1)
- Towards a Typology of Clause Linkage StructuresDokument35 SeitenTowards a Typology of Clause Linkage StructuresPaulo ÂngeloNoch keine Bewertungen
- Task 2Dokument2 SeitenTask 2Meliana SitumorangNoch keine Bewertungen
- Gender of NounsDokument10 SeitenGender of Nounsapi-298162596Noch keine Bewertungen
- Skripsi Kip IngDokument46 SeitenSkripsi Kip IngSyahrulNoch keine Bewertungen
- Anchor Charts Cover The Following:: Parts of SpeechDokument5 SeitenAnchor Charts Cover The Following:: Parts of SpeechSaba FarooqNoch keine Bewertungen
- The Hebrew Verb: CategoryDokument40 SeitenThe Hebrew Verb: CategoryOrso RaggianteNoch keine Bewertungen
- Degree TransformationDokument4 SeitenDegree TransformationAbrar Hossain100% (1)
- Cara Menghafal 16 TensesDokument7 SeitenCara Menghafal 16 TensesLITBANGLC MATERISYLLABUSNoch keine Bewertungen
- Chapter 7 - Preposition (SJS) PDFDokument6 SeitenChapter 7 - Preposition (SJS) PDFAhmad FauzanNoch keine Bewertungen
- Verbs as Complement: Always, Sometimes, or Never Followed by the Infinitive or GerundDokument11 SeitenVerbs as Complement: Always, Sometimes, or Never Followed by the Infinitive or Gerundnaura tsabitaNoch keine Bewertungen
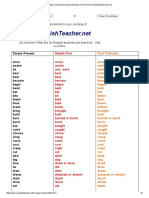
- Irregular Simple Past and Past Participle Verb Forms From MyEnglishTeacherDokument4 SeitenIrregular Simple Past and Past Participle Verb Forms From MyEnglishTeacherSarahandi Api AbdullahNoch keine Bewertungen
- Present Perfect Exercises OKDokument2 SeitenPresent Perfect Exercises OKquely83Noch keine Bewertungen
- Bahasa Inggeris Tahun 6: (Grammar)Dokument14 SeitenBahasa Inggeris Tahun 6: (Grammar)sarina1966Noch keine Bewertungen
- DM PRAGMATICS DISCOURSE MARKERSDokument5 SeitenDM PRAGMATICS DISCOURSE MARKERSMarcos RaballNoch keine Bewertungen
- Possibility: Can't or Cannot To Show That Something Is ImpossibleDokument25 SeitenPossibility: Can't or Cannot To Show That Something Is ImpossibleMeera1104Noch keine Bewertungen
- Adjectives: TSL 1024 Language DescriptionDokument19 SeitenAdjectives: TSL 1024 Language DescriptionTESL10620 Muhammad Zul Aiman Bin Abdul HalimNoch keine Bewertungen
- Chapter X-Noun and Noun Clause In...Dokument14 SeitenChapter X-Noun and Noun Clause In...Midori YuriNoch keine Bewertungen
- Meeting 10 B Adverb Clause and ConnectorDokument43 SeitenMeeting 10 B Adverb Clause and ConnectorDiddly dooNoch keine Bewertungen
- Marathi To English Sentence Translator For SimpleDokument5 SeitenMarathi To English Sentence Translator For Simplerohitkokani026Noch keine Bewertungen
- B.inggris Simple Past TenseDokument12 SeitenB.inggris Simple Past TenseSririzkii WahyuniNoch keine Bewertungen
- Most Common Prefixes: Prefix Meaning Key WordDokument2 SeitenMost Common Prefixes: Prefix Meaning Key Wordrec4554Noch keine Bewertungen