Das könnte Ihnen auch gefallen
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (890)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (587)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (119)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2219)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (265)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (73)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- Business Plan - Docx 3-Star Hospitality and Tourism Devt Centre in Mbarara - UgandaDokument49 SeitenBusiness Plan - Docx 3-Star Hospitality and Tourism Devt Centre in Mbarara - UgandaInfiniteKnowledge100% (9)
- ETP48300-C6D2 Embedded Power User Manual PDFDokument94 SeitenETP48300-C6D2 Embedded Power User Manual PDFjose benedito f. pereira100% (1)
- CIS2103-202220-Group Project - FinalDokument13 SeitenCIS2103-202220-Group Project - FinalMd. HedaitullahNoch keine Bewertungen
- Coupled DrivesDokument17 SeitenCoupled DrivesFouad TachiNoch keine Bewertungen
- Embedded CoderDokument8 SeitenEmbedded Coderجمال طيبيNoch keine Bewertungen
- Construction of Dormitory & Housing compounds in NorochcholaiDokument33 SeitenConstruction of Dormitory & Housing compounds in Norochcholaisaranga100% (1)
- Finesse Service ManualDokument34 SeitenFinesse Service ManualLuis Sivira100% (1)
- Practical Problem Solving: A Beginner'S Guide: Jonathan G. Koomey, Ph. DDokument4 SeitenPractical Problem Solving: A Beginner'S Guide: Jonathan G. Koomey, Ph. DFouad TachiNoch keine Bewertungen
- Wade BasicAdvRegCont 3rd ExcerptDokument48 SeitenWade BasicAdvRegCont 3rd ExcerptGregory AnthonyNoch keine Bewertungen
- PGEOTTTDokument14 SeitenPGEOTTTdevborahNoch keine Bewertungen
- Psycho-Geometrics: Personality ShapesDokument6 SeitenPsycho-Geometrics: Personality ShapesGhostNoch keine Bewertungen
- Introduction Into Bayesian Networks: Mgr. Libor VaněkDokument19 SeitenIntroduction Into Bayesian Networks: Mgr. Libor VaněkFouad TachiNoch keine Bewertungen
- Idiap: Martigny - Valais - SuisseDokument31 SeitenIdiap: Martigny - Valais - SuisseFouad TachiNoch keine Bewertungen
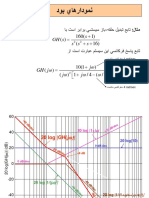
- S Ghs Ss S: تسكش سناكرف= 1 Rad/SecDokument19 SeitenS Ghs Ss S: تسكش سناكرف= 1 Rad/SecFouad TachiNoch keine Bewertungen
- Intercooler, Aftercooler and Antisurge Control: 1. One CasingDokument3 SeitenIntercooler, Aftercooler and Antisurge Control: 1. One CasingFouad TachiNoch keine Bewertungen
- Practical Bayesian Optimization of Machine Learning AlgorithmsDokument9 SeitenPractical Bayesian Optimization of Machine Learning AlgorithmsvsuryadNoch keine Bewertungen
- Fungus Key ProDokument124 SeitenFungus Key ProFouad Tachi100% (1)
- ESA 7.6 Configuration GuideDokument460 SeitenESA 7.6 Configuration GuideaitelNoch keine Bewertungen
- Manual Mue Home RGBDokument8 SeitenManual Mue Home RGBJason OrtizNoch keine Bewertungen
- CS221 - Artificial Intelligence - Machine Learning - 3 Linear ClassificationDokument28 SeitenCS221 - Artificial Intelligence - Machine Learning - 3 Linear ClassificationArdiansyah Mochamad NugrahaNoch keine Bewertungen
- Offer Letter For Marketing ExecutivesDokument2 SeitenOffer Letter For Marketing ExecutivesRahul SinghNoch keine Bewertungen
- CCW Armored Composite OMNICABLEDokument2 SeitenCCW Armored Composite OMNICABLELuis DGNoch keine Bewertungen
- Reason Document 0n Rev.3Dokument58 SeitenReason Document 0n Rev.3d bhNoch keine Bewertungen
- Medhat CVDokument2 SeitenMedhat CVSemsem MakNoch keine Bewertungen
- Restore a Disk Image with ClonezillaDokument16 SeitenRestore a Disk Image with ClonezillaVictor SantosNoch keine Bewertungen
- Distribution Requirements PlanningDokument8 SeitenDistribution Requirements PlanningnishantchopraNoch keine Bewertungen
- Power Efficiency Diagnostics ReportDokument16 SeitenPower Efficiency Diagnostics Reportranscrib300Noch keine Bewertungen
- Computer Application in Business NOTES PDFDokument78 SeitenComputer Application in Business NOTES PDFGhulam Sarwar SoomroNoch keine Bewertungen
- My Con Pds Sikafloor 161 HCDokument5 SeitenMy Con Pds Sikafloor 161 HClaurenjiaNoch keine Bewertungen
- Cambridge IGCSE: GEOGRAPHY 0460/13Dokument32 SeitenCambridge IGCSE: GEOGRAPHY 0460/13Desire KandawasvikaNoch keine Bewertungen
- RAMA - 54201 - 05011381320003 - 0025065101 - 0040225403 - 01 - Front - RefDokument26 SeitenRAMA - 54201 - 05011381320003 - 0025065101 - 0040225403 - 01 - Front - RefMardiana MardianaNoch keine Bewertungen
- Daftar Pustaka Marketing ResearchDokument2 SeitenDaftar Pustaka Marketing ResearchRiyan SaputraNoch keine Bewertungen
- Chrysler Corporation: Service Manual Supplement 1998 Grand CherokeeDokument4 SeitenChrysler Corporation: Service Manual Supplement 1998 Grand CherokeeDalton WiseNoch keine Bewertungen
- RIE 2013 Dumping and AD DutiesDokument21 SeitenRIE 2013 Dumping and AD Dutiessm jahedNoch keine Bewertungen
- Presenting India's Biggest NYE 2023 Destination PartyDokument14 SeitenPresenting India's Biggest NYE 2023 Destination PartyJadhav RamakanthNoch keine Bewertungen
- Converted File d7206cc0Dokument15 SeitenConverted File d7206cc0warzarwNoch keine Bewertungen
- Csit 101 Assignment1Dokument3 SeitenCsit 101 Assignment1api-266677293Noch keine Bewertungen
- COA (Odoo Egypt)Dokument8 SeitenCOA (Odoo Egypt)menams2010Noch keine Bewertungen
- A Study of Factors Influencing The Consumer Behavior Towards Direct Selling Companies With Special Reference To RCM Products1Dokument79 SeitenA Study of Factors Influencing The Consumer Behavior Towards Direct Selling Companies With Special Reference To RCM Products1Chandan SrivastavaNoch keine Bewertungen
- Manual Centrifugadora - Jouan B4i - 2Dokument6 SeitenManual Centrifugadora - Jouan B4i - 2Rita RosadoNoch keine Bewertungen
- Group 1 RRLDokument19 SeitenGroup 1 RRLAngelo BolgarNoch keine Bewertungen