Das könnte Ihnen auch gefallen
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- What Are The Differences Between SFP, SFP+, XFP, QSFP/QSFP+ and CFP?Dokument6 SeitenWhat Are The Differences Between SFP, SFP+, XFP, QSFP/QSFP+ and CFP?ishak8Noch keine Bewertungen
- Removing and Installing SFPsDokument1 SeiteRemoving and Installing SFPsishak8Noch keine Bewertungen
- Tellabs ECT PortsDokument1 SeiteTellabs ECT Portsishak8Noch keine Bewertungen
- Hardware KeyDokument1 SeiteHardware Keyishak8Noch keine Bewertungen
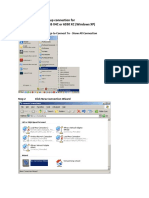
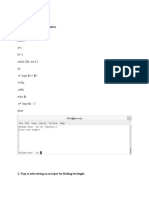
- Dial Up Networking Win XPDokument15 SeitenDial Up Networking Win XPishak8Noch keine Bewertungen
- 010 T8611 T8609 SW Upgrade To v1.1.215Dokument1 Seite010 T8611 T8609 SW Upgrade To v1.1.215ishak8Noch keine Bewertungen
- Integra Optics XFP Modules For 10 Gigabit Ethernet and Packet-Over-SONET ApplicationsDokument4 SeitenIntegra Optics XFP Modules For 10 Gigabit Ethernet and Packet-Over-SONET Applicationsishak8Noch keine Bewertungen
- Why Does My Router Lose Its ConfigurationDokument4 SeitenWhy Does My Router Lose Its Configurationishak8Noch keine Bewertungen
- ISIS TutorialDokument80 SeitenISIS Tutorialstefan_nikola100% (1)
- IS-IS ProtocolDokument52 SeitenIS-IS ProtocolNguyễn Mạnh ThếNoch keine Bewertungen
- Social Engineering: An Attack Vector Most Intricate To Handle!Dokument20 SeitenSocial Engineering: An Attack Vector Most Intricate To Handle!ishak8Noch keine Bewertungen
- Synchronization in Telecom NetworkDokument21 SeitenSynchronization in Telecom NetworkSanjay YadavNoch keine Bewertungen
- Etex LCT Cable: USB Mini To DB9-FemaleDokument1 SeiteEtex LCT Cable: USB Mini To DB9-Femaleishak8Noch keine Bewertungen
- Removing and Installing SFPsDokument1 SeiteRemoving and Installing SFPsishak8Noch keine Bewertungen
- Optical CharacteristicsDokument1 SeiteOptical Characteristicsishak8Noch keine Bewertungen
- 002A Tellabs8660 Single CDC Replacement ProcedureDokument7 Seiten002A Tellabs8660 Single CDC Replacement Procedureishak8Noch keine Bewertungen
- Removing and Installing SFPsDokument1 SeiteRemoving and Installing SFPsishak8Noch keine Bewertungen
- GBIC S CiscoDokument4 SeitenGBIC S Ciscopaulo_an7381Noch keine Bewertungen
- Removing and Installing SFPsDokument1 SeiteRemoving and Installing SFPsishak8Noch keine Bewertungen
- LenovoDokument1 SeiteLenovoishak8Noch keine Bewertungen
- Test UitmDokument8 SeitenTest Uitmishak8Noch keine Bewertungen
- Salm PTN2Dokument13 SeitenSalm PTN2ishak8Noch keine Bewertungen
- Cisco IconsDokument12 SeitenCisco Iconsab_laaroussi0% (1)
- PENARA2Dokument1 SeitePENARA2ishak8Noch keine Bewertungen
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (73)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (120)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Unix As SingDokument32 SeitenUnix As SingPritam SondhiyaNoch keine Bewertungen
- Chapter 1: Introduction To Shell Programming What Is Linux Shell ?Dokument54 SeitenChapter 1: Introduction To Shell Programming What Is Linux Shell ?italoyureNoch keine Bewertungen
- Commandlinefu AllDokument481 SeitenCommandlinefu AllMesut Taşçı100% (1)
- Unix MCQDokument43 SeitenUnix MCQKishan Kumar JhaNoch keine Bewertungen
- Moshell CommandsDokument80 SeitenMoshell Commandsazharz4u100% (2)
- Unix Course Material - Tata ElxsiDokument112 SeitenUnix Course Material - Tata ElxsiRajesh BejjenkiNoch keine Bewertungen
- Sed One LinersDokument8 SeitenSed One LinersBrijmohan SinghNoch keine Bewertungen
- SCI-LAB MANUAL-SLE201-SUSE Linux Enterprise Administration-V1.0.0Dokument152 SeitenSCI-LAB MANUAL-SLE201-SUSE Linux Enterprise Administration-V1.0.0Bharath Priya100% (3)
- OS Lab ManualDokument33 SeitenOS Lab ManualRam BhagwanNoch keine Bewertungen
- Unix CommandsDokument32 SeitenUnix CommandsmejjagiriNoch keine Bewertungen
- UNIX Question Bank - FinalDokument6 SeitenUNIX Question Bank - FinalramalalliNoch keine Bewertungen
- Linuxgym AnswersDokument2 SeitenLinuxgym AnswersthepaperkrainNoch keine Bewertungen
- Experiment No. 1: Aim: Hands On Basic Commands of Unix: LS, Who, More, CP, RM, MV, Mkdir, CDDokument12 SeitenExperiment No. 1: Aim: Hands On Basic Commands of Unix: LS, Who, More, CP, RM, MV, Mkdir, CDSunil SuryawanshiNoch keine Bewertungen
- Command Line Text ProcessingDokument363 SeitenCommand Line Text ProcessingThiago MonteiroNoch keine Bewertungen
- Qucik UnixDokument16 SeitenQucik UnixSazzad HossainNoch keine Bewertungen
- Unix Training by DhanabalDokument340 SeitenUnix Training by DhanabalLeo ThomasNoch keine Bewertungen
- MobatchDokument5 SeitenMobatchT T Raj Tinakar100% (2)
- Basicunix 090307112233 Phpapp02Dokument161 SeitenBasicunix 090307112233 Phpapp02Sumit GuptaNoch keine Bewertungen
- Assignment 1Dokument14 SeitenAssignment 1Birhaneselasie AbebeNoch keine Bewertungen
- Basic Linux Commands PDFDokument4 SeitenBasic Linux Commands PDFCholavendhanNoch keine Bewertungen
- Shell ScriptingDokument177 SeitenShell ScriptingFarhan Alam0% (1)
- Unix CommandsDokument14 SeitenUnix Commandsdharani633Noch keine Bewertungen
- Basic Linux Commands Explained With ExamplesDokument10 SeitenBasic Linux Commands Explained With ExamplesdineshNoch keine Bewertungen
- Basic Unix IDokument78 SeitenBasic Unix IChit HanNoch keine Bewertungen
- OS Assignment No. 3Dokument8 SeitenOS Assignment No. 3Usman ZafarNoch keine Bewertungen
- Linux NotesDokument0 SeitenLinux NotesSrinivas CherukuNoch keine Bewertungen
- Unix/Linux Commands and Shell Programming: Clemson University ParlDokument22 SeitenUnix/Linux Commands and Shell Programming: Clemson University ParlSandeep SinghNoch keine Bewertungen
- Lecture MatlabDokument73 SeitenLecture Matlabn4arjun123Noch keine Bewertungen
- OsDokument190 SeitenOsAkhilesh ChaudhryNoch keine Bewertungen
- Unix MCQDokument30 SeitenUnix MCQTarun KaneriaNoch keine Bewertungen