Das könnte Ihnen auch gefallen
- Calibration TablesDokument32 SeitenCalibration TablesDanielle BarkerNoch keine Bewertungen
- 5G in Bullets1 - 300 - COLORDokument300 Seiten5G in Bullets1 - 300 - COLORDark Horse67% (3)
- Play Guitar: Exploration and Analysis of Harmonic PossibilitiesVon EverandPlay Guitar: Exploration and Analysis of Harmonic PossibilitiesNoch keine Bewertungen
- A Course of Mathematics for Engineerings and Scientists: Volume 5Von EverandA Course of Mathematics for Engineerings and Scientists: Volume 5Noch keine Bewertungen
- Satellite Comm.Dokument156 SeitenSatellite Comm.Akshay KarveNoch keine Bewertungen
- Expt 1 - Setting Up of A Fiber Optic Analog LinkDokument4 SeitenExpt 1 - Setting Up of A Fiber Optic Analog Linksamarth50% (2)
- T3-Fourier SeriesDokument10 SeitenT3-Fourier SeriesmaryamNoch keine Bewertungen
- 11 Fourier Analysis IDokument32 Seiten11 Fourier Analysis IAshu KumarNoch keine Bewertungen
- Review of Signals and Systems:: Gaurav S. Kasbekar Dept. of Electrical Engineering IIT BombayDokument8 SeitenReview of Signals and Systems:: Gaurav S. Kasbekar Dept. of Electrical Engineering IIT Bombayvishal kumarNoch keine Bewertungen
- T4-Fourier TransformsDokument8 SeitenT4-Fourier TransformsmaryamNoch keine Bewertungen
- Week 11 12 - Fourier TransformDokument47 SeitenWeek 11 12 - Fourier Transformbang lubisNoch keine Bewertungen
- L29: Fourier AnalysisDokument29 SeitenL29: Fourier AnalysisHarshNoch keine Bewertungen
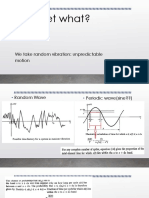
- Wavelet What?: We Take Random Vibration: Unpredictable MotionDokument18 SeitenWavelet What?: We Take Random Vibration: Unpredictable Motionsujayan2005Noch keine Bewertungen
- Signals and Systems: DR Tania StathakiDokument20 SeitenSignals and Systems: DR Tania StathakikentNoch keine Bewertungen
- Fourier SeriesDokument7 SeitenFourier SeriesAfif HaziqNoch keine Bewertungen
- Unit 1 Introduction To Fourier TransformDokument53 SeitenUnit 1 Introduction To Fourier TransformDivyansh UmareNoch keine Bewertungen
- Signals and Systems Notes (Midterm)Dokument20 SeitenSignals and Systems Notes (Midterm)abdhatemshNoch keine Bewertungen
- Complex Exponential Fourier SeriesDokument7 SeitenComplex Exponential Fourier SeriessaurabhNoch keine Bewertungen
- Mod 8 - Lecture 1Dokument24 SeitenMod 8 - Lecture 1lvrevathiNoch keine Bewertungen
- Lecture 3Dokument42 SeitenLecture 3Zamshed FormanNoch keine Bewertungen
- DSP Sp23 Wk14 230524Dokument27 SeitenDSP Sp23 Wk14 230524Qaiser AbbasNoch keine Bewertungen
- Lecture 1Dokument33 SeitenLecture 1Farooq GhaziNoch keine Bewertungen
- Review of Signals and Systems: Gaurav S. Kasbekar Dept. of Electrical Engineering IIT BombayDokument32 SeitenReview of Signals and Systems: Gaurav S. Kasbekar Dept. of Electrical Engineering IIT BombayParth ShettiwarNoch keine Bewertungen
- Review of Signals and Systems: Gaurav S. Kasbekar Dept. of Electrical Engineering IIT BombayDokument32 SeitenReview of Signals and Systems: Gaurav S. Kasbekar Dept. of Electrical Engineering IIT BombayRANJEET PATELNoch keine Bewertungen
- Week 10Dokument32 SeitenWeek 10onuraktas1923Noch keine Bewertungen
- Lecture 3Dokument27 SeitenLecture 3khaddamoazNoch keine Bewertungen
- EEE221 Lec3 PDFDokument61 SeitenEEE221 Lec3 PDFMd. Nazmul Huda 1610805643Noch keine Bewertungen
- ELT2035 Signals: & SystemsDokument30 SeitenELT2035 Signals: & Systemshm.quy.9223Noch keine Bewertungen
- PDF PPT Fourier Dr. RajeshDokument41 SeitenPDF PPT Fourier Dr. RajeshSakshi ShuklaNoch keine Bewertungen
- Gogte Institute of Technology: (An Autonomous Institution Under Visveswaraya Technological University, Belagavi)Dokument13 SeitenGogte Institute of Technology: (An Autonomous Institution Under Visveswaraya Technological University, Belagavi)manjunath koraddiNoch keine Bewertungen
- S&S - Week 11Dokument25 SeitenS&S - Week 11machasong98Noch keine Bewertungen
- Lecture Slides - Week-03 Fourier Series and Fourier Transform PDFDokument31 SeitenLecture Slides - Week-03 Fourier Series and Fourier Transform PDFRakhmeen gulNoch keine Bewertungen
- Digital Representation Sept 4-5-11 12Dokument33 SeitenDigital Representation Sept 4-5-11 12Shravani KodeNoch keine Bewertungen
- Mod 3 - 1Dokument57 SeitenMod 3 - 1anuNoch keine Bewertungen
- ME360: Signal Processing: Lecture 04: Operations On SignalsDokument26 SeitenME360: Signal Processing: Lecture 04: Operations On Signals陈炯帆Noch keine Bewertungen
- 10 - Acceleration and Vibration Measurement - SensorsDokument28 Seiten10 - Acceleration and Vibration Measurement - SensorsKARTHIK S SNoch keine Bewertungen
- Lec 2,3 Signal ClassificationDokument26 SeitenLec 2,3 Signal Classification7.bharani12Noch keine Bewertungen
- Lecture 8 Fourier Series CT SignalsDokument16 SeitenLecture 8 Fourier Series CT SignalsPray PlayNoch keine Bewertungen
- Lecturer 3 Signals & SystemsDokument33 SeitenLecturer 3 Signals & SystemsTony StarkNoch keine Bewertungen
- Lecture 2Dokument25 SeitenLecture 2khaddamoazNoch keine Bewertungen
- Signal ProcessingDokument40 SeitenSignal ProcessingSamson MumbaNoch keine Bewertungen
- Fourier Series Representation of Periodic SignalsDokument62 SeitenFourier Series Representation of Periodic SignalsNibasamNoch keine Bewertungen
- Digital Signal Processing Represents Signals by A Sequence of Numbers Like Sampling or Analog-To-Digital Conversions. TheyDokument7 SeitenDigital Signal Processing Represents Signals by A Sequence of Numbers Like Sampling or Analog-To-Digital Conversions. Theydanimar baculotNoch keine Bewertungen
- Amplifier Frequency Response: 1. General ConceptsDokument15 SeitenAmplifier Frequency Response: 1. General ConceptsAmr Ayman awad ali 1179Noch keine Bewertungen
- Signals and Systems: Lecture 13 Wednesday 6 December 2017Dokument34 SeitenSignals and Systems: Lecture 13 Wednesday 6 December 2017aniNoch keine Bewertungen
- Signal & Systems - EDUSATDokument87 SeitenSignal & Systems - EDUSATNaresh MundraNoch keine Bewertungen
- Introduction ECE 102Dokument33 SeitenIntroduction ECE 102Marven YusonNoch keine Bewertungen
- Fourier Series of Periodic SignalDokument8 SeitenFourier Series of Periodic Signaldarpanporwal4Noch keine Bewertungen
- 1 SignalsDokument17 Seiten1 SignalsTingyang YUNoch keine Bewertungen
- Advanced Digital Signal Processing Ch2Dokument65 SeitenAdvanced Digital Signal Processing Ch2Saif ShubbarNoch keine Bewertungen
- Lecture1 PDFDokument40 SeitenLecture1 PDFmslectNoch keine Bewertungen
- Correlation Spectral Density AM Aug 10Dokument8 SeitenCorrelation Spectral Density AM Aug 10vishal kumarNoch keine Bewertungen
- Final Report MAT565Dokument7 SeitenFinal Report MAT565Shahmi FarhanNoch keine Bewertungen
- Lecture 3 (Incomplete)Dokument16 SeitenLecture 3 (Incomplete)Zamshed FormanNoch keine Bewertungen
- Ue20ec203 20211021140641Dokument55 SeitenUe20ec203 20211021140641Devesh BhaskaranNoch keine Bewertungen
- SS01 - 2022S1 - New Signal and SystemDokument21 SeitenSS01 - 2022S1 - New Signal and SystemThúy Nguyễn ThịNoch keine Bewertungen
- Mod 4 - 2Dokument83 SeitenMod 4 - 2anuNoch keine Bewertungen
- Signals and Systems: Dr. Mohamed Bingabr University of Central OklahomaDokument44 SeitenSignals and Systems: Dr. Mohamed Bingabr University of Central OklahomaadhomeworkNoch keine Bewertungen
- Communication System Presentation: Behzad Shaukat 2k16-Ele-056 Ahsan Ammar 2k16-Ele-051Dokument53 SeitenCommunication System Presentation: Behzad Shaukat 2k16-Ele-056 Ahsan Ammar 2k16-Ele-051Behzad ShaukatNoch keine Bewertungen
- L4 Random Signals and Noise PDFDokument55 SeitenL4 Random Signals and Noise PDFcriscab12345Noch keine Bewertungen
- Radically Elementary Probability Theory. (AM-117), Volume 117Von EverandRadically Elementary Probability Theory. (AM-117), Volume 117Bewertung: 4 von 5 Sternen4/5 (2)
- Screenplay Template Word PDFDokument3 SeitenScreenplay Template Word PDFevagabor37Noch keine Bewertungen
- stm32f103c8 956229 PDFDokument118 Seitenstm32f103c8 956229 PDFMuhammad Sultan NaufalNoch keine Bewertungen
- Assg 1Dokument3 SeitenAssg 1PradeepNoch keine Bewertungen
- Pradeep Tidke Microwave Assignment 1Dokument3 SeitenPradeep Tidke Microwave Assignment 1PradeepNoch keine Bewertungen
- SC PresentationDokument17 SeitenSC PresentationPradeepNoch keine Bewertungen
- DiffDokument5 SeitenDiffPradeepNoch keine Bewertungen
- Hgxyt Jcxys Jgcyktxbn NGCTF FlufDokument1 SeiteHgxyt Jcxys Jgcyktxbn NGCTF FlufPradeepNoch keine Bewertungen
- ETI 220 - Lab Seminar: Presentation ObjectivesDokument12 SeitenETI 220 - Lab Seminar: Presentation ObjectivespceinsteinNoch keine Bewertungen
- Lecture 2Dokument38 SeitenLecture 2Haisham AliNoch keine Bewertungen
- DSP - Using Matlab - Chap2Dokument37 SeitenDSP - Using Matlab - Chap2nguyencraft01Noch keine Bewertungen
- SeminarDokument200 SeitenSeminarMudassarNoch keine Bewertungen
- Title Journal 3 PDFDokument8 SeitenTitle Journal 3 PDFSAMENoch keine Bewertungen
- 1157 DatasheetDokument6 Seiten1157 DatasheetTuppari Mohanlenin100% (1)
- User Manual of Smart AMI Meter HXE110 1 Phase 2 WireDokument99 SeitenUser Manual of Smart AMI Meter HXE110 1 Phase 2 WireNiko KosmosNoch keine Bewertungen
- Manual ITP16Dokument12 SeitenManual ITP16Thang VuNoch keine Bewertungen
- Course Name CO Number With Code Co Statement BT LevelDokument43 SeitenCourse Name CO Number With Code Co Statement BT LevelPolkam SrinidhiNoch keine Bewertungen
- Impedance and Impedance MatchingDokument4 SeitenImpedance and Impedance MatchingvedaNoch keine Bewertungen
- Annex II AMC 20-136Dokument23 SeitenAnnex II AMC 20-136philip00165Noch keine Bewertungen
- 40 TwinCAT NC PLC TCMC2 ENDokument39 Seiten40 TwinCAT NC PLC TCMC2 ENShubham PatilNoch keine Bewertungen
- HV Power Cable ThermalDokument8 SeitenHV Power Cable ThermalmazzoffaNoch keine Bewertungen
- Blueprint For Control EngineringDokument23 SeitenBlueprint For Control Engineringyisakabera123Noch keine Bewertungen
- Ecu CodesDokument4 SeitenEcu CodesMIANoch keine Bewertungen
- Apple Computer Inc. v. Burst - Com, Inc. - Document No. 78Dokument30 SeitenApple Computer Inc. v. Burst - Com, Inc. - Document No. 78Justia.comNoch keine Bewertungen
- Semestre 3Dokument138 SeitenSemestre 3Marta MoratillaNoch keine Bewertungen
- Lecture+10-12 (Sampling and Reconstruction) PDFDokument72 SeitenLecture+10-12 (Sampling and Reconstruction) PDFTalha MazharNoch keine Bewertungen
- DSP Lab 1 TaskDokument18 SeitenDSP Lab 1 TaskMuhammad AnasNoch keine Bewertungen
- AFCI Technical White PaperDokument16 SeitenAFCI Technical White PaperSon NguyenNoch keine Bewertungen
- SiemensDokument1.174 SeitenSiemensnickcoptilNoch keine Bewertungen
- 004 1 EE 232 Signals and SystemsDokument2 Seiten004 1 EE 232 Signals and SystemsShaharyar WaliullahNoch keine Bewertungen
- SH-XP Instruction ManualDokument10 SeitenSH-XP Instruction ManualEdson RamosNoch keine Bewertungen
- Chapter 1Dokument41 SeitenChapter 1Naman JainNoch keine Bewertungen
- EE-232: Signals and Systems Lab 3: Signal TransformationsDokument8 SeitenEE-232: Signals and Systems Lab 3: Signal TransformationsMuhammad Uzair KhanNoch keine Bewertungen
- SSS 1 Week 6 Digitalization of DataDokument3 SeitenSSS 1 Week 6 Digitalization of DataOnoseNoch keine Bewertungen
- FSMD PressDokument29 SeitenFSMD PressshoaibkhaliqNoch keine Bewertungen