Das könnte Ihnen auch gefallen
- AsdadDokument14 SeitenAsdadchrisNoch keine Bewertungen
- Additional Exercises for Vectors, Matrices, and Least SquaresDokument41 SeitenAdditional Exercises for Vectors, Matrices, and Least SquaresAlejandro Patiño RiveraNoch keine Bewertungen
- ECE120L - Activity 5Dokument5 SeitenECE120L - Activity 5Duper FuberNoch keine Bewertungen
- cs229 Notes EnsembleDokument7 Seitencs229 Notes EnsemblebobNoch keine Bewertungen
- The Lognormal Distribution: Univariate DistributionsDokument7 SeitenThe Lognormal Distribution: Univariate Distributionsbig clapNoch keine Bewertungen
- LIMITS OF MULTIVARIABLE FUNCTIONSDokument88 SeitenLIMITS OF MULTIVARIABLE FUNCTIONSAditya Kumar SinghNoch keine Bewertungen
- HKU MATH1853 - Brief Linear Algebra Notes: 1 Eigenvalues and EigenvectorsDokument6 SeitenHKU MATH1853 - Brief Linear Algebra Notes: 1 Eigenvalues and EigenvectorsfirelumiaNoch keine Bewertungen
- DT Notes 2020Dokument14 SeitenDT Notes 2020Ling Min HaoNoch keine Bewertungen
- CS168: The Modern Algorithmic Toolbox Lectures #11: Spectral Graph Theory, IDokument7 SeitenCS168: The Modern Algorithmic Toolbox Lectures #11: Spectral Graph Theory, IAndropov AjebuaNoch keine Bewertungen
- Lecture 3 PDFDokument66 SeitenLecture 3 PDFHà Anh Minh LêNoch keine Bewertungen
- Introduction to Two-Dimensional Random VariablesDokument23 SeitenIntroduction to Two-Dimensional Random VariablesOnetwothree TubeNoch keine Bewertungen
- ML for Data Science Lecture Notes: Spectral ClusteringDokument4 SeitenML for Data Science Lecture Notes: Spectral ClusteringkjuyhtvghbNoch keine Bewertungen
- October 26: 7.1 Quantum Hamiltonian ComplexityDokument5 SeitenOctober 26: 7.1 Quantum Hamiltonian ComplexityAustin ClarkNoch keine Bewertungen
- CS168 Spectral Graph Theory (Roughgarden & Valiant)Dokument11 SeitenCS168 Spectral Graph Theory (Roughgarden & Valiant)Noppawee ApichonpongpanNoch keine Bewertungen
- Solving Differential Equations With MatlabDokument20 SeitenSolving Differential Equations With MatlabYon Jairo MontoyaNoch keine Bewertungen
- MATLAB Intro TutorialDokument5 SeitenMATLAB Intro TutorialNoorLiana MahmudNoch keine Bewertungen
- 01 TransformationsDokument16 Seiten01 TransformationsAnonymous 9q5GEfm8INoch keine Bewertungen
- LineIntegrals PDFDokument11 SeitenLineIntegrals PDFJia ToorNoch keine Bewertungen
- Frequency Domain Analysis of Dynamic SystemsDokument26 SeitenFrequency Domain Analysis of Dynamic Systemsblister_xbladeNoch keine Bewertungen
- Task#1: Generate The Binomial Distribution With FollowingDokument6 SeitenTask#1: Generate The Binomial Distribution With FollowingMuhammad NaveedNoch keine Bewertungen
- Absolute Value FunctionsDokument8 SeitenAbsolute Value Functionsapi-357579360Noch keine Bewertungen
- Normal Statistics EstimationDokument8 SeitenNormal Statistics EstimationIonuț Cătălin SanduNoch keine Bewertungen
- Relativistic QMDokument21 SeitenRelativistic QMI m mortal Beast ytNoch keine Bewertungen
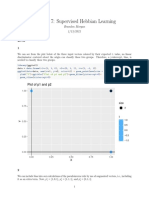
- Supervised Hebbian Learning ExplainedDokument3 SeitenSupervised Hebbian Learning Explainedsamaneh keshavarziNoch keine Bewertungen
- Assignment 02Dokument2 SeitenAssignment 02Muntaha Rahman MayazNoch keine Bewertungen
- Unit 5 Three Dimensional Transformations: Structure Page NoDokument21 SeitenUnit 5 Three Dimensional Transformations: Structure Page NoMuhammad SahilNoch keine Bewertungen
- QMC Lecture #12 - Quasi Monte Carlo IntegrationDokument20 SeitenQMC Lecture #12 - Quasi Monte Carlo IntegrationankiosaNoch keine Bewertungen
- Computational Methods in Electrical EngineeringDokument9 SeitenComputational Methods in Electrical EngineeringROMANCE FantasNoch keine Bewertungen
- Stat Mining 42Dokument1 SeiteStat Mining 42Adonis HuaytaNoch keine Bewertungen
- Mzumbe University Faculty of Science and Technology Qms 125:linear Algebra Tutorial Sheet 4Dokument3 SeitenMzumbe University Faculty of Science and Technology Qms 125:linear Algebra Tutorial Sheet 4Melchizedek MashamboNoch keine Bewertungen
- Matrices Represent Digital ImagesDokument5 SeitenMatrices Represent Digital ImagesSergio SanabriaNoch keine Bewertungen
- Vector Spaces ProblemsDokument2 SeitenVector Spaces Problemsal viewNoch keine Bewertungen
- Adc Lab 3Dokument6 SeitenAdc Lab 3ahad mushtaqNoch keine Bewertungen
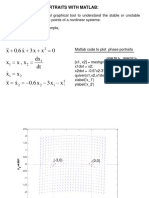
- 7phase Portraits Chaos FDDokument30 Seiten7phase Portraits Chaos FDSantiago Garrido BullónNoch keine Bewertungen
- Stat6201 ch3-2Dokument3 SeitenStat6201 ch3-2BowenYangNoch keine Bewertungen
- On The Classification of Sub-Riemannian StructuresDokument10 SeitenOn The Classification of Sub-Riemannian StructuresatuanaNoch keine Bewertungen
- Transelliptical Component Analysis: Johns Hopkins University Princeton UniversityDokument26 SeitenTranselliptical Component Analysis: Johns Hopkins University Princeton UniversitybobmezzNoch keine Bewertungen
- Mect4470 TH1Dokument4 SeitenMect4470 TH1Ercan DenizNoch keine Bewertungen
- Lecture 12Dokument24 SeitenLecture 12ankiosaNoch keine Bewertungen
- Nonlinear Systems: LaSalle's Invariant Set TheoremsDokument36 SeitenNonlinear Systems: LaSalle's Invariant Set TheoremsgiacomoNoch keine Bewertungen
- Quantum Mechanics - Concepts and Applications - 9780470026793 - Ejercicio 12 - QuizletDokument1 SeiteQuantum Mechanics - Concepts and Applications - 9780470026793 - Ejercicio 12 - QuizletCarlos AmbrosioNoch keine Bewertungen
- Practice 4 Exam 1Dokument6 SeitenPractice 4 Exam 1Himanshu YadavNoch keine Bewertungen
- Msc19key PDFDokument3 SeitenMsc19key PDFManjay PalNoch keine Bewertungen
- Exact Finite Differences The Derivative On Non-Uniformly Spaced Partitions - Armando Martínez-Pérez - 25 July 2017Dokument11 SeitenExact Finite Differences The Derivative On Non-Uniformly Spaced Partitions - Armando Martínez-Pérez - 25 July 2017RMolina65Noch keine Bewertungen
- Activity #5Dokument5 SeitenActivity #5Crishen VinzonNoch keine Bewertungen
- Linear Algebra Primer Breaks Down Key ConceptsDokument15 SeitenLinear Algebra Primer Breaks Down Key ConceptsMario PioNoch keine Bewertungen
- Finding the Inverse of a Matrix Using Elementary Row OperationsDokument10 SeitenFinding the Inverse of a Matrix Using Elementary Row OperationsAndy OrtizNoch keine Bewertungen
- Polynomial Regression: y A X + A X X XDokument5 SeitenPolynomial Regression: y A X + A X X XEmil TengwarNoch keine Bewertungen
- On-Line - Tutoriales (1, 2, 3, 4 y 5)Dokument22 SeitenOn-Line - Tutoriales (1, 2, 3, 4 y 5)Antonio LMNoch keine Bewertungen
- Optimization: Machine Learning Course - CS-433Dokument23 SeitenOptimization: Machine Learning Course - CS-433Diego Iriarte SainzNoch keine Bewertungen
- Quiz Feedback1 - CourseraDokument7 SeitenQuiz Feedback1 - Courserasudipta244703100% (1)
- Vmls - 103exercisesDokument50 SeitenVmls - 103exercisessalnasuNoch keine Bewertungen
- Math 1060 - Lecture 3Dokument5 SeitenMath 1060 - Lecture 3John LeeNoch keine Bewertungen
- Normal Distribution NotesDokument30 SeitenNormal Distribution NotesMya CNoch keine Bewertungen
- Financial Econometrics AssignmentDokument14 SeitenFinancial Econometrics AssignmentYuhan KENoch keine Bewertungen
- Lect2 03webDokument15 SeitenLect2 03webrathbabuli123Noch keine Bewertungen
- Lecture3 ConvexSetsFuns PDFDokument43 SeitenLecture3 ConvexSetsFuns PDFIbrahim Saiful MillahNoch keine Bewertungen
- 2 - DeterminantsDokument50 Seiten2 - DeterminantsnhưNoch keine Bewertungen
- Lecture Note 3 - Introduction To Vector and Matrix DifferentiationDokument6 SeitenLecture Note 3 - Introduction To Vector and Matrix DifferentiationFaizus Saquib ChowdhuryNoch keine Bewertungen
- A-level Maths Revision: Cheeky Revision ShortcutsVon EverandA-level Maths Revision: Cheeky Revision ShortcutsBewertung: 3.5 von 5 Sternen3.5/5 (8)
- CamScanner Scans PDFs from PhotosDokument5 SeitenCamScanner Scans PDFs from PhotosKetan DhakateNoch keine Bewertungen
- Naive Bayes PDFDokument5 SeitenNaive Bayes PDFKetan DhakateNoch keine Bewertungen
- Distracted Driver Detection Using Stacking Ensemble: Ketan DhakateDokument1 SeiteDistracted Driver Detection Using Stacking Ensemble: Ketan DhakateKetan DhakateNoch keine Bewertungen
- Energy Efficient Container Consolidation in CloudDokument55 SeitenEnergy Efficient Container Consolidation in CloudKetan DhakateNoch keine Bewertungen
- Scan App Review - CamScanner PDF ScannerDokument2 SeitenScan App Review - CamScanner PDF ScannerKetan DhakateNoch keine Bewertungen
- Recommendation Systems PDFDokument5 SeitenRecommendation Systems PDFKetan DhakateNoch keine Bewertungen
- Logistic Regression PDFDokument8 SeitenLogistic Regression PDFKetan DhakateNoch keine Bewertungen
- Feature Engineering PDFDokument5 SeitenFeature Engineering PDFKetan DhakateNoch keine Bewertungen
- Probability and Statistics PDFDokument10 SeitenProbability and Statistics PDFKetan DhakateNoch keine Bewertungen
- Deep Learning Intro PDFDokument11 SeitenDeep Learning Intro PDFKetan DhakateNoch keine Bewertungen
- Pseudo Residual Revisited PDFDokument2 SeitenPseudo Residual Revisited PDFKetan DhakateNoch keine Bewertungen
- Eda PDFDokument3 SeitenEda PDFKetan DhakateNoch keine Bewertungen
- Solving Optimisation Problems PDFDokument4 SeitenSolving Optimisation Problems PDFKetan DhakateNoch keine Bewertungen
- RNN PDFDokument4 SeitenRNN PDFKetan DhakateNoch keine Bewertungen
- CNN PDFDokument4 SeitenCNN PDFKetan DhakateNoch keine Bewertungen
- Performance Measurement of Models PDFDokument4 SeitenPerformance Measurement of Models PDFKetan DhakateNoch keine Bewertungen
- Classification Algo in Various Scenarios PDFDokument10 SeitenClassification Algo in Various Scenarios PDFKetan DhakateNoch keine Bewertungen
- Dimensionality Reduction PDFDokument6 SeitenDimensionality Reduction PDFKetan DhakateNoch keine Bewertungen
- Ensemble Models PDFDokument10 SeitenEnsemble Models PDFKetan DhakateNoch keine Bewertungen
- CS229 Lecture Notes: The K-Means Clustering AlgorithmDokument3 SeitenCS229 Lecture Notes: The K-Means Clustering AlgorithmSatheesh ChandranNoch keine Bewertungen
- KNN PDFDokument12 SeitenKNN PDFKetan DhakateNoch keine Bewertungen
- Decision Trees PDFDokument4 SeitenDecision Trees PDFKetan DhakateNoch keine Bewertungen
- EM Algorithm for Mixtures of GaussiansDokument4 SeitenEM Algorithm for Mixtures of GaussiansAndres Tuells JanssonNoch keine Bewertungen
- Support Vector Machines: CS229 Lecture NotesDokument25 SeitenSupport Vector Machines: CS229 Lecture NotesNiyas PNoch keine Bewertungen
- Cs229 Notes4.PsDokument11 SeitenCs229 Notes4.PsAnuj PatelNoch keine Bewertungen
- cs229 Notes1 PDFDokument30 Seitencs229 Notes1 PDFGuilherme GermanoNoch keine Bewertungen
- PerceptronDokument3 SeitenPerceptronapi-3814100Noch keine Bewertungen
- Computer Architecture by Kai Hwang Kai Hwang & F. A. Briggs, "Computer Architecture and Parallel Processing", McGraw HillDokument864 SeitenComputer Architecture by Kai Hwang Kai Hwang & F. A. Briggs, "Computer Architecture and Parallel Processing", McGraw Hillkulnix75% (8)
- cs229 Notes5Dokument8 Seitencs229 Notes5Arka MitraNoch keine Bewertungen
- G-Snack Evolution Rev05Dokument2 SeitenG-Snack Evolution Rev05whaleNoch keine Bewertungen
- 20220606-03 Bombilla de Referencia - Prueba #1 - Después Del ADokument11 Seiten20220606-03 Bombilla de Referencia - Prueba #1 - Después Del Ajesus sanchezNoch keine Bewertungen
- 2-d. Statically Indeterminate Members: Ans. 3330 KNDokument2 Seiten2-d. Statically Indeterminate Members: Ans. 3330 KNJasleneDimarananNoch keine Bewertungen
- CE 481 Solid Waste & Environmental PollutionDokument140 SeitenCE 481 Solid Waste & Environmental PollutionDamini ThakurNoch keine Bewertungen
- Salem Product CatalogueDokument6 SeitenSalem Product Cataloguedramilt0% (1)
- Universal temperature transmitter for HART protocolDokument16 SeitenUniversal temperature transmitter for HART protocolALI5034Noch keine Bewertungen
- Anupampriya@bhu Ac inDokument12 SeitenAnupampriya@bhu Ac inPrityyyNoch keine Bewertungen
- PLC Simulation ReportDokument62 SeitenPLC Simulation ReportAsraful Goni NirabNoch keine Bewertungen
- Carta Psicometrica - CarrierDokument1 SeiteCarta Psicometrica - CarrierJonathan Andres0% (1)
- Liquid Retaining Reinforced Concrete Section To BS 8007& BS 8110Dokument15 SeitenLiquid Retaining Reinforced Concrete Section To BS 8007& BS 8110tttmm100% (1)
- University Physics II - Thermodynamics, Electricity, MagnetismDokument924 SeitenUniversity Physics II - Thermodynamics, Electricity, MagnetismFeiFei SunNoch keine Bewertungen
- ControlExperiments - Precision Modular ServoDokument43 SeitenControlExperiments - Precision Modular ServoNachoSainzNoch keine Bewertungen
- Heating With Coils and JacketsDokument14 SeitenHeating With Coils and Jacketsibal_machine100% (1)
- The Philosophy of David Hume According to HumeDokument7 SeitenThe Philosophy of David Hume According to HumePaul Kallan100% (1)
- Soundness TestDokument4 SeitenSoundness TestC-one Goncalves100% (2)
- Lecture Notes On Mathematical Methods PH2130 - 2012/2013: Glen D. Cowan Physics DepartmentDokument8 SeitenLecture Notes On Mathematical Methods PH2130 - 2012/2013: Glen D. Cowan Physics DepartmentbbteenagerNoch keine Bewertungen
- 2-Mark Questions Anna University Signals and SystemsDokument11 Seiten2-Mark Questions Anna University Signals and SystemsSonu100% (2)
- Determine COP of a Heat Pump/Refrigeration MachineDokument2 SeitenDetermine COP of a Heat Pump/Refrigeration MachineJeremy Tay0% (2)
- Boiler Performance Guarantee R0Dokument3 SeitenBoiler Performance Guarantee R0Prafitri KurniawanNoch keine Bewertungen
- Extraction in Chemical Technology PrincipleDokument24 SeitenExtraction in Chemical Technology PrincipleFatima ZaharaNoch keine Bewertungen
- Photography March 2016Dokument32 SeitenPhotography March 2016ArtdataNoch keine Bewertungen
- ME304 HOMEWORK 3Dokument3 SeitenME304 HOMEWORK 3Steve KrodaNoch keine Bewertungen
- Reading List - Philosophy of Quantum MechanicsDokument13 SeitenReading List - Philosophy of Quantum MechanicsDinh Quy DuongNoch keine Bewertungen
- Biaxial Bending of SFRC Slabs Is Conventional Reinforcement NecessaryDokument15 SeitenBiaxial Bending of SFRC Slabs Is Conventional Reinforcement NecessaryDan MaceNoch keine Bewertungen
- Column C section and tie detailsDokument1 SeiteColumn C section and tie detailsبه شدار ازاد عبدالرحمن عليNoch keine Bewertungen
- Muhammad Imran YousufDokument1 SeiteMuhammad Imran YousufMuhammad Irfan YousufNoch keine Bewertungen
- GE6251 Basic Civil and Mechanical Engineering Regulation 2013 Lecture NotesDokument112 SeitenGE6251 Basic Civil and Mechanical Engineering Regulation 2013 Lecture NotesSasi Dharan100% (1)
- GC Methode Development RestekDokument71 SeitenGC Methode Development RestekbenyNoch keine Bewertungen
- Current Mode Pi ControllerDokument19 SeitenCurrent Mode Pi ControllersunitaNoch keine Bewertungen
- Gas Welding: Name: Muhammad Farulfitri Bin Abd Gafar Matrix No.: 14DEM19F1047Dokument11 SeitenGas Welding: Name: Muhammad Farulfitri Bin Abd Gafar Matrix No.: 14DEM19F1047Farul FitriNoch keine Bewertungen