Das könnte Ihnen auch gefallen
- Équations différentielles: Les Grands Articles d'UniversalisVon EverandÉquations différentielles: Les Grands Articles d'UniversalisNoch keine Bewertungen
- Estimateur Ponctuel Et Qualités DestimateursDokument26 SeitenEstimateur Ponctuel Et Qualités DestimateursAnis DjemelNoch keine Bewertungen
- Chapitre 4 Partie IDokument10 SeitenChapitre 4 Partie INissou MegNoch keine Bewertungen
- Cours Statistiques InfDokument18 SeitenCours Statistiques InfDimokrati HoussamNoch keine Bewertungen
- Balisage de ESTIMATEURDokument23 SeitenBalisage de ESTIMATEUR123456789Noch keine Bewertungen
- Cour 2 L 3Dokument5 SeitenCour 2 L 3NinineNoch keine Bewertungen
- UntitledDokument10 SeitenUntitledZ CoulNoch keine Bewertungen
- Projet Becem-Houssem253Dokument35 SeitenProjet Becem-Houssem253Houssem AjiliNoch keine Bewertungen
- E Non P de La DensitéDokument23 SeitenE Non P de La DensitéHoussem AjiliNoch keine Bewertungen
- FicheTDINFO308 2020Dokument3 SeitenFicheTDINFO308 2020LaneNoch keine Bewertungen
- TEI Chap2 Estimation Ponctuelle Version CoursDokument16 SeitenTEI Chap2 Estimation Ponctuelle Version CoursedelgardrayNoch keine Bewertungen
- Cours Statistique Parametrique Chap 1Dokument14 SeitenCours Statistique Parametrique Chap 1mahaseddiki2003Noch keine Bewertungen
- Acp 2018Dokument56 SeitenAcp 2018ALI AIT SIDI LKHIRNoch keine Bewertungen
- Cours 1Dokument29 SeitenCours 1SAFONoch keine Bewertungen
- L3 STAT Corrige 2009 12 03 PDFDokument3 SeitenL3 STAT Corrige 2009 12 03 PDFGilbert ADJASSOUNoch keine Bewertungen
- Stat Non para 2020Dokument31 SeitenStat Non para 2020Ndeye Nafissatou Thiaw ThiawNoch keine Bewertungen
- Cour 3Dokument8 SeitenCour 3NinineNoch keine Bewertungen
- TD3 Stat InfDokument4 SeitenTD3 Stat InfOthnel EffiNoch keine Bewertungen
- Peg EstimationDokument7 SeitenPeg EstimationMohamed MAHJOUBNoch keine Bewertungen
- TD Test With SolutionDokument16 SeitenTD Test With Solutionwarriormind001Noch keine Bewertungen
- Chapitre4 Proba Stats Estim Ponc 2021 2022Dokument7 SeitenChapitre4 Proba Stats Estim Ponc 2021 2022Nourane BougharriouNoch keine Bewertungen
- Bon CourDokument51 SeitenBon CourSali IssaNoch keine Bewertungen
- TD StatDokument11 SeitenTD StatZozo Zozo DiagneNoch keine Bewertungen
- Chap 2 StatDokument125 SeitenChap 2 Statrami ouerghiNoch keine Bewertungen
- Mathf 207 Seance 3Dokument3 SeitenMathf 207 Seance 3soulaimane lafhalNoch keine Bewertungen
- EstimationDokument5 SeitenEstimationHakem TahaNoch keine Bewertungen
- TD3Est Ponct2020Dokument4 SeitenTD3Est Ponct2020Wael KhemakhemNoch keine Bewertungen
- PDF M1 CC1 2007Dokument1 SeitePDF M1 CC1 2007api-3773410Noch keine Bewertungen
- Chapitre 1 Partie 2Dokument18 SeitenChapitre 1 Partie 2ヤス ミンNoch keine Bewertungen
- Corrigedm 1Dokument5 SeitenCorrigedm 1Lamine KonatéNoch keine Bewertungen
- Exos Chap 14Dokument3 SeitenExos Chap 14mathurinkopelgaNoch keine Bewertungen
- Chapitre IIIDokument12 SeitenChapitre IIImohamed lamine hamritNoch keine Bewertungen
- Psycho Slides Stat L3 S6Dokument76 SeitenPsycho Slides Stat L3 S6Bvictor Boni100% (1)
- Analyses Factorielles M1 EA p1Dokument39 SeitenAnalyses Factorielles M1 EA p1Bintou RassoulNoch keine Bewertungen
- Lecon2 - Estimation StatistiqueDokument22 SeitenLecon2 - Estimation StatistiqueMamadou TouréNoch keine Bewertungen
- PC 9: Intervalles de ConfianceDokument5 SeitenPC 9: Intervalles de ConfianceMer YemNoch keine Bewertungen
- Chapitre 5 EstimastionDokument44 SeitenChapitre 5 EstimastionsimoNoch keine Bewertungen
- Proba5 PDFDokument8 SeitenProba5 PDFjrachek21490% (1)
- TD 06 07Dokument11 SeitenTD 06 07zenonibrahimNoch keine Bewertungen
- Cours Inférence Chapitre 3 - Ouazza - 22-23Dokument21 SeitenCours Inférence Chapitre 3 - Ouazza - 22-23Aymane SguigaaNoch keine Bewertungen
- Stat Proba 2Dokument20 SeitenStat Proba 2Kouamé kouassi JosephNoch keine Bewertungen
- Tests D'hypothèses ParamétriquesDokument16 SeitenTests D'hypothèses ParamétriquesSouheil BéjiNoch keine Bewertungen
- td10 11!!!!!!!!!!!Dokument20 Seitentd10 11!!!!!!!!!!!taikyousseflogfrNoch keine Bewertungen
- T2 CorrectionsDokument9 SeitenT2 CorrectionsJonathan AmatuNoch keine Bewertungen
- TD02Dokument3 SeitenTD02zenonibrahimNoch keine Bewertungen
- CourS602 - 2013Dokument32 SeitenCourS602 - 2013ChamseddineKarafiNoch keine Bewertungen
- Statistique InductifDokument8 SeitenStatistique Inductifmariama doucoureNoch keine Bewertungen
- AgregTP3Scilab2017 2018Dokument8 SeitenAgregTP3Scilab2017 2018dfeNoch keine Bewertungen
- Exercices L12Dokument19 SeitenExercices L12Alassane SowNoch keine Bewertungen
- Talay 1Dokument8 SeitenTalay 1Mohamed CHARIFNoch keine Bewertungen
- T.D. SMC-Serie 4 - CorrigésDokument12 SeitenT.D. SMC-Serie 4 - CorrigésaaaaaaaaaaaNoch keine Bewertungen
- Chapitre1 - Rappels StatistiquesDokument11 SeitenChapitre1 - Rappels StatistiquesGislain KandaNoch keine Bewertungen
- Correction TD2Dokument18 SeitenCorrection TD2mathurinkopelgaNoch keine Bewertungen
- Analyse Factorielles M1 EADokument129 SeitenAnalyse Factorielles M1 EABintou RassoulNoch keine Bewertungen
- Chap Stat 3Dokument49 SeitenChap Stat 3Amira GhazouaniNoch keine Bewertungen
- Chapitre 2-MathDokument11 SeitenChapitre 2-MathAsmaa KhhNoch keine Bewertungen
- Correction Stat 20102011Dokument9 SeitenCorrection Stat 20102011Dony KravitzNoch keine Bewertungen
- Estimation Ponctuelle Et Par Intervalle de Confiance: Feuille de TP N 6Dokument5 SeitenEstimation Ponctuelle Et Par Intervalle de Confiance: Feuille de TP N 6Abdelhamid JenzriNoch keine Bewertungen
- Devoir 2019Dokument14 SeitenDevoir 2019arsene-perelmanNoch keine Bewertungen
- Chapitre 4-Théorèmes Limites Et EstimationDokument13 SeitenChapitre 4-Théorèmes Limites Et EstimationademNoch keine Bewertungen
- 2 Définissez Un Positionnement de MarchéDokument14 Seiten2 Définissez Un Positionnement de MarchéJean LotusNoch keine Bewertungen
- Assurez L'équité en Individualisant Les Décisions de RémunérationDokument12 SeitenAssurez L'équité en Individualisant Les Décisions de RémunérationJean LotusNoch keine Bewertungen
- Appréhendez La Complexité Du Concept de Rémunération - Élaborez Une Politique de Rémunération - OpenClassroomsDokument12 SeitenAppréhendez La Complexité Du Concept de Rémunération - Élaborez Une Politique de Rémunération - OpenClassroomsJean LotusNoch keine Bewertungen
- Inventaire Passation 2Dokument2 SeitenInventaire Passation 2Jean LotusNoch keine Bewertungen
- 3 Soutenez La Stratégie de Votre EntrepriseDokument10 Seiten3 Soutenez La Stratégie de Votre EntrepriseJean LotusNoch keine Bewertungen
- Identifiez Les Acteurs D'une Politique de RémunérationDokument11 SeitenIdentifiez Les Acteurs D'une Politique de RémunérationJean LotusNoch keine Bewertungen
- 2 Identifiez Les Incitations Financières Les Plus AdaptéesDokument12 Seiten2 Identifiez Les Incitations Financières Les Plus AdaptéesJean LotusNoch keine Bewertungen
- Combinatoire - Calcul de Dénombrements 2Dokument5 SeitenCombinatoire - Calcul de Dénombrements 2Jean LotusNoch keine Bewertungen
- Combinatoire - Calcul de Dénombrements 1Dokument2 SeitenCombinatoire - Calcul de Dénombrements 1Jean LotusNoch keine Bewertungen
- 1 Arbitrez Entre Les Grands Systèmes de Rémunération Selon Votre StratégieDokument12 Seiten1 Arbitrez Entre Les Grands Systèmes de Rémunération Selon Votre StratégieJean LotusNoch keine Bewertungen
- Corrigé de L'exercice 4 de Statistique DescriptiveDokument2 SeitenCorrigé de L'exercice 4 de Statistique DescriptiveJean Lotus100% (1)
- 3 Offrez Des Avantages AttractifsDokument13 Seiten3 Offrez Des Avantages AttractifsJean LotusNoch keine Bewertungen
- Eurécia - Modèle Tableau de Bord RH SimpleDokument74 SeitenEurécia - Modèle Tableau de Bord RH SimpleJean Lotus100% (1)
- Corrigé de L'exercice 9 de Statistique DescriptiveDokument2 SeitenCorrigé de L'exercice 9 de Statistique DescriptiveJean LotusNoch keine Bewertungen
- STT 1920 Loi NormaleDokument2 SeitenSTT 1920 Loi NormaleJean LotusNoch keine Bewertungen
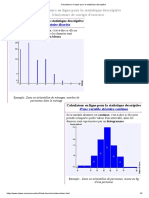
- Calculateurs en Ligne Pour La Statistique DescriptiveDokument2 SeitenCalculateurs en Ligne Pour La Statistique DescriptiveJean LotusNoch keine Bewertungen
- Corrigé de L'exercice 3 de Statistique DescriptiveDokument4 SeitenCorrigé de L'exercice 3 de Statistique DescriptiveJean LotusNoch keine Bewertungen
- Id 8349 PDFDokument36 SeitenId 8349 PDFJean LotusNoch keine Bewertungen
- Corrigé de L'exercice 1 de Statistique DescriptiveDokument2 SeitenCorrigé de L'exercice 1 de Statistique DescriptiveJean Lotus0% (1)
- Corrigé de L'exercice 6 de Statistique DescriptiveDokument2 SeitenCorrigé de L'exercice 6 de Statistique DescriptiveJean LotusNoch keine Bewertungen
- Corrigé de L'exercice 8 de Statistique DescriptiveDokument4 SeitenCorrigé de L'exercice 8 de Statistique DescriptiveJean LotusNoch keine Bewertungen
- Corrigé de L'exercice 2 de Statistique DescriptiveDokument2 SeitenCorrigé de L'exercice 2 de Statistique DescriptiveJean LotusNoch keine Bewertungen
- Resume Modele IS-LMDokument4 SeitenResume Modele IS-LMJean LotusNoch keine Bewertungen
- Corrigé de L'exercice 9 de Statistique DescriptiveDokument2 SeitenCorrigé de L'exercice 9 de Statistique DescriptiveJean LotusNoch keine Bewertungen
- Corrigé de L'exercice 10 de Statistique DescriptiveDokument4 SeitenCorrigé de L'exercice 10 de Statistique DescriptiveJean LotusNoch keine Bewertungen
- 3g Chimie TousDokument6 Seiten3g Chimie Tousapi-502752268Noch keine Bewertungen
- 3 As - Projet 2 - Le Débat DidéesDokument37 Seiten3 As - Projet 2 - Le Débat Didéesryad133192% (171)
- Physiopathologie NeuroscienceDokument46 SeitenPhysiopathologie NeuroscienceYas MiiinaaNoch keine Bewertungen
- Animaux ExercicesDokument5 SeitenAnimaux Exercicesmansouri100% (1)
- Alphabetically: InstructionsDokument3 SeitenAlphabetically: InstructionsquentinfollinaNoch keine Bewertungen
- Cours 2 - Principales Caractéristiques Des VégétauxDokument29 SeitenCours 2 - Principales Caractéristiques Des VégétauxMouhamadou DiopNoch keine Bewertungen
- Lenovo-Pc20200624145014 PDFDokument3 SeitenLenovo-Pc20200624145014 PDFMOUMOUNoch keine Bewertungen
- Ca 203 FR 1501 - LRDokument4 SeitenCa 203 FR 1501 - LRjlopezNoch keine Bewertungen
- Whirlpool ADG 676 NBDokument12 SeitenWhirlpool ADG 676 NBChristian AlbertiniNoch keine Bewertungen
- Sujets de Théorie 1Dokument7 SeitenSujets de Théorie 1titounanoNoch keine Bewertungen
- Contentieux Du TravailDokument37 SeitenContentieux Du Travailmarc soubeigaNoch keine Bewertungen
- Are 2Dokument28 SeitenAre 2Ndoumbe BaNoch keine Bewertungen
- Esquema ElectricoDokument67 SeitenEsquema ElectricoGonçalo Filipe SousaNoch keine Bewertungen
- PEF Zizou Corriger - GENERAL - Khouloud Nchalla NejhaDokument56 SeitenPEF Zizou Corriger - GENERAL - Khouloud Nchalla Nejhakhouloud rouissiNoch keine Bewertungen
- KOUMENDokument73 SeitenKOUMENSerigne WadeNoch keine Bewertungen
- PRAL Des Aliments Alcalinisants Et Acidifiants - InternetDokument10 SeitenPRAL Des Aliments Alcalinisants Et Acidifiants - InternetsauvageNoch keine Bewertungen
- Genie Civil Questions WatermarkDokument11 SeitenGenie Civil Questions WatermarkBenhmaida HananNoch keine Bewertungen
- Appareil LocomoteurDokument2 SeitenAppareil LocomoteurTASMINE HAMZANoch keine Bewertungen
- Camera Infrarouge PDFDokument11 SeitenCamera Infrarouge PDFsensaadNoch keine Bewertungen
- Préparation MentaleDokument19 SeitenPréparation Mentaleardis murejNoch keine Bewertungen
- Disjoncteur C60H-DC - A9N61522Dokument2 SeitenDisjoncteur C60H-DC - A9N61522Paul DayNoch keine Bewertungen
- Conception de Moule-2Dokument3 SeitenConception de Moule-2elking gingstarsNoch keine Bewertungen
- ProcrastinationDokument2 SeitenProcrastinationBRAKNESSNoch keine Bewertungen
- The Very Hungry CaterpillarDokument3 SeitenThe Very Hungry Caterpillarkinito kNoch keine Bewertungen
- Carte Tiers Payant Thomas MoulignerDokument2 SeitenCarte Tiers Payant Thomas MoulignerGUIARDENoch keine Bewertungen
- TP JarDokument4 SeitenTP JarAY YàNoch keine Bewertungen
- Vicia Faba (La Féve)Dokument85 SeitenVicia Faba (La Féve)Martine FatouNoch keine Bewertungen