Das könnte Ihnen auch gefallen
- AWS Solutions Architect Certification Case Based Practice Questions Latest Edition 2023Von EverandAWS Solutions Architect Certification Case Based Practice Questions Latest Edition 2023Noch keine Bewertungen
- AWS Solution Architect Certification Exam Practice Paper 2019Von EverandAWS Solution Architect Certification Exam Practice Paper 2019Bewertung: 3.5 von 5 Sternen3.5/5 (3)
- Nire0510 Aws ServicesDokument3 SeitenNire0510 Aws ServiceswalidmoussaNoch keine Bewertungen
- Amazon Web Services (AWS) Interview Questions and AnswersVon EverandAmazon Web Services (AWS) Interview Questions and AnswersBewertung: 4.5 von 5 Sternen4.5/5 (3)
- AWS Certified Cloud Practitioner - Practice Paper 4: AWS Certified Cloud Practitioner, #4Von EverandAWS Certified Cloud Practitioner - Practice Paper 4: AWS Certified Cloud Practitioner, #4Noch keine Bewertungen
- AWS Certified Cloud Practitioner - Practice Paper 1: AWS Certified Cloud Practitioner, #1Von EverandAWS Certified Cloud Practitioner - Practice Paper 1: AWS Certified Cloud Practitioner, #1Bewertung: 4.5 von 5 Sternen4.5/5 (2)
- AWS Certified Cloud Practitioner - Practice Paper 2: AWS Certified Cloud Practitioner, #2Von EverandAWS Certified Cloud Practitioner - Practice Paper 2: AWS Certified Cloud Practitioner, #2Bewertung: 5 von 5 Sternen5/5 (2)
- AWS Administration – The Definitive GuideVon EverandAWS Administration – The Definitive GuideBewertung: 4.5 von 5 Sternen4.5/5 (3)
- Cloud Computing FundamentalsDokument17 SeitenCloud Computing FundamentalsAkash GandharNoch keine Bewertungen
- Cloud Migration Complete Self-Assessment GuideVon EverandCloud Migration Complete Self-Assessment GuideBewertung: 3 von 5 Sternen3/5 (1)
- Microsoft Workloads in AWSDokument250 SeitenMicrosoft Workloads in AWSmajd natour100% (1)
- Re-Architecting Application for Cloud: An Architect's reference guideVon EverandRe-Architecting Application for Cloud: An Architect's reference guideBewertung: 4 von 5 Sternen4/5 (1)
- Serverless Architectures on AWS Complete Self-Assessment GuideVon EverandServerless Architectures on AWS Complete Self-Assessment GuideNoch keine Bewertungen
- Cloud Computing Interview Questions You'll Most Likely Be Asked: Second EditionVon EverandCloud Computing Interview Questions You'll Most Likely Be Asked: Second EditionNoch keine Bewertungen
- AWS Certified Cloud Practitioner: Study Guide with Practice Questions and LabsVon EverandAWS Certified Cloud Practitioner: Study Guide with Practice Questions and LabsBewertung: 5 von 5 Sternen5/5 (1)
- Aws Interview Guide EbookDokument27 SeitenAws Interview Guide EbookDigambar S Tatkare100% (1)
- AWS Certified Advanced Networking - Specialty Exam Guide: Build your knowledge and technical expertise as an AWS-certified networking specialistVon EverandAWS Certified Advanced Networking - Specialty Exam Guide: Build your knowledge and technical expertise as an AWS-certified networking specialistNoch keine Bewertungen
- AWS Migration Competency: Consulting Partner Validation Checklist, v3.1Dokument22 SeitenAWS Migration Competency: Consulting Partner Validation Checklist, v3.1Harold PiragautaNoch keine Bewertungen
- Azure AD Domain Services A Complete Guide - 2020 EditionVon EverandAzure AD Domain Services A Complete Guide - 2020 EditionNoch keine Bewertungen
- Cloud Migration Handbook Vol. 1: A Practical Guide to Successful Cloud Adoption and MigrationVon EverandCloud Migration Handbook Vol. 1: A Practical Guide to Successful Cloud Adoption and MigrationBewertung: 1 von 5 Sternen1/5 (1)
- AWS Migration OverviewDokument24 SeitenAWS Migration OverviewVarsha50% (2)
- AWS Certified: Learn the secrets to passing the aws exams and getting all the certifications real and unique practice test includedVon EverandAWS Certified: Learn the secrets to passing the aws exams and getting all the certifications real and unique practice test includedBewertung: 1 von 5 Sternen1/5 (1)
- Expert AWS Cheat SheetDokument12 SeitenExpert AWS Cheat Sheetselva50% (2)
- Professional Cloud Architect – Google Cloud Certification Guide: A handy guide to designing, developing, and managing enterprise-grade GCP cloud solutionsVon EverandProfessional Cloud Architect – Google Cloud Certification Guide: A handy guide to designing, developing, and managing enterprise-grade GCP cloud solutionsNoch keine Bewertungen
- AWS Overview Part 1Dokument34 SeitenAWS Overview Part 1Vinu3012Noch keine Bewertungen
- Azure Cloud Migration PDFDokument1.284 SeitenAzure Cloud Migration PDFsabhazra67% (3)
- Cloud Computing Playbook: 10 In 1 Practical Cloud Design With Azure, Aws And TerraformVon EverandCloud Computing Playbook: 10 In 1 Practical Cloud Design With Azure, Aws And TerraformNoch keine Bewertungen
- AWS Landing Zone: Pravin MenghaniDokument16 SeitenAWS Landing Zone: Pravin MenghaniDRNoch keine Bewertungen
- AWS Practioner Study GuideDokument10 SeitenAWS Practioner Study GuidejackNoch keine Bewertungen
- A Practical Guide For Cloud Migration ReadinessDokument17 SeitenA Practical Guide For Cloud Migration Readinesssundeep_dubeyNoch keine Bewertungen
- AWS Certified Solutions Architect A Complete Guide - 2021 EditionVon EverandAWS Certified Solutions Architect A Complete Guide - 2021 EditionNoch keine Bewertungen
- Study GUIDE AWSDokument103 SeitenStudy GUIDE AWScarth100% (1)
- Aws Devops A Complete Guide - 2020 EditionVon EverandAws Devops A Complete Guide - 2020 EditionBewertung: 5 von 5 Sternen5/5 (1)
- Architecting the Cloud Complete Self-Assessment GuideVon EverandArchitecting the Cloud Complete Self-Assessment GuideNoch keine Bewertungen
- AWS White PaperDokument6 SeitenAWS White PaperJohann LeeNoch keine Bewertungen
- AmazonWebService Course ContentDokument16 SeitenAmazonWebService Course ContentVivek Reddy Devagudi100% (1)
- A Practical Guide To Cloud MigrationDokument13 SeitenA Practical Guide To Cloud MigrationRio Ardian100% (1)
- Azure Migration PlanDokument88 SeitenAzure Migration Plansaikumar Muktha100% (1)
- Aws Architecture GuideDokument76 SeitenAws Architecture GuideNapster King100% (2)
- AWS Certified Advanced Networking Official Study Guide: Specialty ExamVon EverandAWS Certified Advanced Networking Official Study Guide: Specialty ExamBewertung: 5 von 5 Sternen5/5 (1)
- AWS Certified Solutions Architect Professional Blueprint PDFDokument37 SeitenAWS Certified Solutions Architect Professional Blueprint PDFrajinikvNoch keine Bewertungen
- Hands-On Linux Administration on Azure - Second Edition: Develop, maintain, and automate applications on the Azure cloud platform, 2nd EditionVon EverandHands-On Linux Administration on Azure - Second Edition: Develop, maintain, and automate applications on the Azure cloud platform, 2nd EditionBewertung: 2 von 5 Sternen2/5 (1)
- Mastering Azure Kubernetes Service (AKS): Rapidly Build and Scale Your Containerized Applications with Microsoft Azure Kubernetes Service (English Edition)Von EverandMastering Azure Kubernetes Service (AKS): Rapidly Build and Scale Your Containerized Applications with Microsoft Azure Kubernetes Service (English Edition)Noch keine Bewertungen
- AWS+Essentials+Student+Guide+Print+Out+V1 8Dokument56 SeitenAWS+Essentials+Student+Guide+Print+Out+V1 8princechennai50% (2)
- Certified Kubernetes Application Developer (CKAD) Exam Success Guide: Ace your career in Kubernetes development with CKAD certification (English Edition)Von EverandCertified Kubernetes Application Developer (CKAD) Exam Success Guide: Ace your career in Kubernetes development with CKAD certification (English Edition)Noch keine Bewertungen
- AWS Cloud Adoption FrameworkDokument23 SeitenAWS Cloud Adoption FrameworkMentalPROblemNoch keine Bewertungen
- AWS Certified Cloud Practitioner Study Guide: CLF-C01 ExamVon EverandAWS Certified Cloud Practitioner Study Guide: CLF-C01 ExamBewertung: 5 von 5 Sternen5/5 (1)
- MySQL Replication BlueprintDokument26 SeitenMySQL Replication BlueprintangieNoch keine Bewertungen
- Cflamp 1Dokument1 SeiteCflamp 1carloncho2012Noch keine Bewertungen
- Microsoft VirtualizationDokument211 SeitenMicrosoft VirtualizationKemploeNoch keine Bewertungen
- Pve Admin Guide PDFDokument370 SeitenPve Admin Guide PDFАлександр ПяткинNoch keine Bewertungen
- Welcome To The Dark Side - The Effect of Switching On CFL Measure LifeDokument12 SeitenWelcome To The Dark Side - The Effect of Switching On CFL Measure LifeKemploeNoch keine Bewertungen
- Irpllnr1: PowirlightDokument15 SeitenIrpllnr1: PowirlightKemploeNoch keine Bewertungen
- Data Analytics For Beginners - Paul Kinley - CreateSpace Independent Publishing Platform 2016 - IsBN 978-1-53989-673-9Dokument51 SeitenData Analytics For Beginners - Paul Kinley - CreateSpace Independent Publishing Platform 2016 - IsBN 978-1-53989-673-9Kemploe100% (2)
- Understanding Minimum Specified Compressive StrengthDokument2 SeitenUnderstanding Minimum Specified Compressive StrengthsasikumareNoch keine Bewertungen
- Twice The Bits, Twice The Trouble - Vulnerabilities Induced by Migrating To 64-Bit PlatformsDokument12 SeitenTwice The Bits, Twice The Trouble - Vulnerabilities Induced by Migrating To 64-Bit PlatformsKemploeNoch keine Bewertungen
- ZEHST Broschuere en 2014 V04Dokument8 SeitenZEHST Broschuere en 2014 V04KemploeNoch keine Bewertungen
- En - Protab 2 Ips - Manual Android 4.0Dokument12 SeitenEn - Protab 2 Ips - Manual Android 4.0XopermarkNoch keine Bewertungen
- System Administrator BiodataDokument3 SeitenSystem Administrator BiodataPankaj NinganiaNoch keine Bewertungen
- Urban Indian Voter Study 2013Dokument23 SeitenUrban Indian Voter Study 2013FirstpostNoch keine Bewertungen
- (LFC5000 VK Manual)Dokument12 Seiten(LFC5000 VK Manual)Peñaloz GustavoNoch keine Bewertungen
- Performance Testing of Java Engines Using IBM - Rational Performance TesterDokument39 SeitenPerformance Testing of Java Engines Using IBM - Rational Performance TesterpuranamravinderNoch keine Bewertungen
- Humorous Writing Exercise Using Internet Memes On English ClassesDokument12 SeitenHumorous Writing Exercise Using Internet Memes On English ClassesIrana IraNoch keine Bewertungen
- Career Planning & Development in ROBIDokument22 SeitenCareer Planning & Development in ROBIshironamhin_92Noch keine Bewertungen
- Home For Consumers: Avoid ScamsDokument4 SeitenHome For Consumers: Avoid ScamsAbang NurazlyNoch keine Bewertungen
- Understanding The New Role of IP Management Within The Digital Transformation in Industry and Commerce - IP For BusinessDokument17 SeitenUnderstanding The New Role of IP Management Within The Digital Transformation in Industry and Commerce - IP For BusinessMehmet TarakciogluNoch keine Bewertungen
- The Elder Scrolls V Skyrim FAQ-Walkthrough by Bkstunt - 31Dokument343 SeitenThe Elder Scrolls V Skyrim FAQ-Walkthrough by Bkstunt - 31Edis ŠarićNoch keine Bewertungen
- F-Shaped Pattern For Reading Web ContentDokument3 SeitenF-Shaped Pattern For Reading Web Contentbortles1Noch keine Bewertungen
- 1.1 Welcome To ZOCDokument143 Seiten1.1 Welcome To ZOCAvram Emilia100% (1)
- S50 IP PBX User ManualDokument104 SeitenS50 IP PBX User ManualRazabdeen MohammedNoch keine Bewertungen
- HP8594QDokument12 SeitenHP8594QewnatalNoch keine Bewertungen
- Anker Cables and Chargers Product ListingDokument4 SeitenAnker Cables and Chargers Product ListingMarcelo IbarraNoch keine Bewertungen
- 1756-En2T (EN2F) ControlLogix EtherNet-IP Bridge Module Release NotesDokument8 Seiten1756-En2T (EN2F) ControlLogix EtherNet-IP Bridge Module Release NotesJoshua PattersonNoch keine Bewertungen
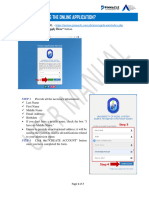
- URS Admission Online Application Step by Step Procedure URBODokument7 SeitenURS Admission Online Application Step by Step Procedure URBOerelleveNoch keine Bewertungen
- Backstory TemplateDokument4 SeitenBackstory TemplateD kingNoch keine Bewertungen
- Nine Components of Mission Statement: Mohamed Adib Nazim Bin Mohd Yusoff AP160521Dokument3 SeitenNine Components of Mission Statement: Mohamed Adib Nazim Bin Mohd Yusoff AP160521Adib NazimNoch keine Bewertungen
- IP Cameras User ManualDokument24 SeitenIP Cameras User ManualCristian RADULESCUNoch keine Bewertungen
- An 23Dokument12 SeitenAn 23ディエゴ水上Noch keine Bewertungen
- Data Communications Notes Unit 4Dokument13 SeitenData Communications Notes Unit 4narradoNoch keine Bewertungen
- Alexa, Amazon Web Services, Amazon Robotics, Amazon Prime AirNegative: High Capex and R&D costs. Risk of failure of new technologies. Difficulty in monetizing newtechnologiesDokument2 SeitenAlexa, Amazon Web Services, Amazon Robotics, Amazon Prime AirNegative: High Capex and R&D costs. Risk of failure of new technologies. Difficulty in monetizing newtechnologiesanushriNoch keine Bewertungen
- Internet Banking Project ReportDokument12 SeitenInternet Banking Project ReportT ANoch keine Bewertungen
- GSM SecurityDokument36 SeitenGSM Securityradislamy-1Noch keine Bewertungen
- RR N v5.8.3 20170706 Jfltexx Official ChangelogDokument10 SeitenRR N v5.8.3 20170706 Jfltexx Official ChangelogCrisdel dela CruzNoch keine Bewertungen
- Tema Engleza - CiornaDokument8 SeitenTema Engleza - CiornaNelu MacaveiNoch keine Bewertungen
- Jquery SummaryDokument8 SeitenJquery Summaryraj06740Noch keine Bewertungen
- DNS Interview Questions and AnswersDokument6 SeitenDNS Interview Questions and Answersasinha08Noch keine Bewertungen