Das könnte Ihnen auch gefallen
- p90x Xbox Nutrition Guide PDFDokument133 Seitenp90x Xbox Nutrition Guide PDFAlfie Roel Gutierrez100% (2)
- p90x Xbox Nutrition Guide PDFDokument133 Seitenp90x Xbox Nutrition Guide PDFAlfie Roel Gutierrez100% (2)
- 1010 Analytical Data-Interpretation and Treatment UspDokument29 Seiten1010 Analytical Data-Interpretation and Treatment Uspalexanderaristizabal100% (1)
- Manual de Despiece Honda Beat 100Dokument84 SeitenManual de Despiece Honda Beat 100jorgeeu8833% (3)
- Meta-Analyses of Experimental DataDokument12 SeitenMeta-Analyses of Experimental DataMevlut GunalNoch keine Bewertungen
- Art Meta-Analyses of Experimental Data in An PDFDokument12 SeitenArt Meta-Analyses of Experimental Data in An PDFIonela HoteaNoch keine Bewertungen
- GUID - 5 en-USDokument29 SeitenGUID - 5 en-USAndrés Ignacio Solano SeravalliNoch keine Bewertungen
- Bonifacio V. Romero High School Senior High School DepartmentDokument2 SeitenBonifacio V. Romero High School Senior High School DepartmentThons Nacu LisingNoch keine Bewertungen
- Assignment 3Dokument10 SeitenAssignment 3scarynumbers999Noch keine Bewertungen
- Ajhp2276 (Tambahan 3)Dokument9 SeitenAjhp2276 (Tambahan 3)rachmairma345Noch keine Bewertungen
- 〈1010〉 Analytical Data-Interpretation and TreatmentDokument29 Seiten〈1010〉 Analytical Data-Interpretation and TreatmentMohamad AbdulmajeedNoch keine Bewertungen
- Principles of Drug Literature Evaluation For Observational Study DesignsDokument13 SeitenPrinciples of Drug Literature Evaluation For Observational Study Designs李姵瑩Noch keine Bewertungen
- Official: Á1010Ñ Analytical Data-Interpretation and TreatmentDokument29 SeitenOfficial: Á1010Ñ Analytical Data-Interpretation and TreatmentDilawar BakhtNoch keine Bewertungen
- Quantitative Analysis Is Often Associated With Numerical Analysis Where Data Is Collected, Classified, andDokument2 SeitenQuantitative Analysis Is Often Associated With Numerical Analysis Where Data Is Collected, Classified, andKim Emmanuel Castro CañazaresNoch keine Bewertungen
- Meta AnalysisofPrevalenceStudiesusingR August2021Dokument6 SeitenMeta AnalysisofPrevalenceStudiesusingR August2021Juris JustinNoch keine Bewertungen
- Chapter 1 What Is Quantitative ResearchDokument10 SeitenChapter 1 What Is Quantitative ResearchManoy KulaNoch keine Bewertungen
- Handouts in Research 2Dokument5 SeitenHandouts in Research 2nona yamutNoch keine Bewertungen
- Ares ReviewerDokument53 SeitenAres Reviewerkaye arcedeNoch keine Bewertungen
- Statistical Analysis of Experimental Designs Applied To Biological AssaysDokument42 SeitenStatistical Analysis of Experimental Designs Applied To Biological AssaysMuhammad Masoom AkhtarNoch keine Bewertungen
- Quantitative ResearchDokument8 SeitenQuantitative ResearchApril MaeNoch keine Bewertungen
- Monitoring Quality Control: Can We Get Better Data?Dokument7 SeitenMonitoring Quality Control: Can We Get Better Data?HECTORIBZAN ACERO SANDOVALNoch keine Bewertungen
- PR2 Reviewer (A4)Dokument10 SeitenPR2 Reviewer (A4)G-03 Aldovino, Aleaseya Faye A.Noch keine Bewertungen
- Ares2 Lesson1Dokument7 SeitenAres2 Lesson1Jochene Eve AldamiaNoch keine Bewertungen
- Part 8Dokument4 SeitenPart 8nguyendung0917Noch keine Bewertungen
- Validity and Reliability of Measurement Instruments Used in ResearchDokument10 SeitenValidity and Reliability of Measurement Instruments Used in ResearchNovitaSariNoch keine Bewertungen
- Improving Oncology Trials Through Adaptive Trial Design - ACT-Oncology-eBook-2016-MayDokument7 SeitenImproving Oncology Trials Through Adaptive Trial Design - ACT-Oncology-eBook-2016-MayRaviprakash MadhyasthaNoch keine Bewertungen
- Quantitative Research FinalDokument9 SeitenQuantitative Research FinalRohit SinghNoch keine Bewertungen
- NG Writing A Title and Describing Background of ResearchDokument10 SeitenNG Writing A Title and Describing Background of Researchchristinebadeo000Noch keine Bewertungen
- Meta-Analyses of Experimental Data in Animal Nutrition : D. Sauvant, P. Schmidely, J. J. Daudin and N. R. St-PierreDokument12 SeitenMeta-Analyses of Experimental Data in Animal Nutrition : D. Sauvant, P. Schmidely, J. J. Daudin and N. R. St-PierreAndres Suarez UsbeckNoch keine Bewertungen
- BiostaticsDokument9 SeitenBiostaticsSana ShabirNoch keine Bewertungen
- Ittner (2014)Dokument5 SeitenIttner (2014)Luuk VisserNoch keine Bewertungen
- Group 2 - QUANTITATIVE RESEARCHDokument12 SeitenGroup 2 - QUANTITATIVE RESEARCHTanaka Majoboro100% (1)
- 1 s2.0 S0022030281828469 MainDokument7 Seiten1 s2.0 S0022030281828469 MainChirila IoanaNoch keine Bewertungen
- Chapter 3 Research MethodologyDokument9 SeitenChapter 3 Research MethodologyAnya Evangelista100% (1)
- 2 Quantitative Research - IntroductionDokument8 Seiten2 Quantitative Research - IntroductionRopafadzo MashingaidzeNoch keine Bewertungen
- Lavendia Portfolio PR2 ABM12 4Dokument28 SeitenLavendia Portfolio PR2 ABM12 4PresydenteNoch keine Bewertungen
- Research Methods (Week 9-10) ExerciseDokument6 SeitenResearch Methods (Week 9-10) ExerciseISAAC OURIENNoch keine Bewertungen
- Week 3 Task 2 Critically Compare and Contrast The Two Main Research Approaches With Special Focus On Their Differences 22may 2022Dokument11 SeitenWeek 3 Task 2 Critically Compare and Contrast The Two Main Research Approaches With Special Focus On Their Differences 22may 2022AMTRISNoch keine Bewertungen
- ResourcesDokument1 SeiteResourcesZoe YellowNoch keine Bewertungen
- Approaching Microbiological Method Validation-1Dokument19 SeitenApproaching Microbiological Method Validation-1Apar DholakiaNoch keine Bewertungen
- Characteristics of Quantitative Research 1. SystematicDokument12 SeitenCharacteristics of Quantitative Research 1. SystematicisseylimboNoch keine Bewertungen
- Invited Review: Sensory Analysis of Dairy Foods: J. Dairy Sci. 90:4925-4937 Doi:10.3168/jds.2007-0332Dokument13 SeitenInvited Review: Sensory Analysis of Dairy Foods: J. Dairy Sci. 90:4925-4937 Doi:10.3168/jds.2007-0332Beatriz FerreiraNoch keine Bewertungen
- Writing Chapter 3: The MethodologyDokument5 SeitenWriting Chapter 3: The MethodologyAnonymous 1VhXp1Noch keine Bewertungen
- Week 2 OverviewDokument44 SeitenWeek 2 Overviewbailey ButcherNoch keine Bewertungen
- Chapter 2 - Introduction To Quantitative ResearchDokument62 SeitenChapter 2 - Introduction To Quantitative ResearchIconMaicoNoch keine Bewertungen
- Food Journal 6Dokument13 SeitenFood Journal 6Etiniabasi UmoinyangNoch keine Bewertungen
- Impacts of Improved Agricultural Technology Adoption On Welfare I - 2023 - HeliyDokument16 SeitenImpacts of Improved Agricultural Technology Adoption On Welfare I - 2023 - HeliySweetzy Ann DughoNoch keine Bewertungen
- Fcm3-g4 Critical AppraisalDokument18 SeitenFcm3-g4 Critical AppraisalDenise CedeñoNoch keine Bewertungen
- Peer Reviewed: Microbiology: Approaching Microbiological Method Validation - IVTDokument18 SeitenPeer Reviewed: Microbiology: Approaching Microbiological Method Validation - IVTPrashanth KumarNoch keine Bewertungen
- LAGMANDokument61 SeitenLAGMANJenny Grace IbardolazaNoch keine Bewertungen
- Times Series and Risk Adjusted Control ChartsDokument2 SeitenTimes Series and Risk Adjusted Control Chartselo ochoa coronaNoch keine Bewertungen
- Descriptive Sensory AnalysisDokument11 SeitenDescriptive Sensory AnalysisJulio Cesar EpiclesisNoch keine Bewertungen
- Printed AHS 2307 Experimental Design NotesDokument43 SeitenPrinted AHS 2307 Experimental Design NotesBancy k.Noch keine Bewertungen
- Math 212 Module 1Dokument5 SeitenMath 212 Module 1Jefone Jade GuzonNoch keine Bewertungen
- Udd Med Filipino Summer Final ExamDokument6 SeitenUdd Med Filipino Summer Final Exambryl john lawrence villamarNoch keine Bewertungen
- Approaching Microbiological Method Validation IVTDokument18 SeitenApproaching Microbiological Method Validation IVTPiruzi MaghlakelidzeNoch keine Bewertungen
- Module 3-Health Technology, Assessment Study Designs, and EvidencesDokument9 SeitenModule 3-Health Technology, Assessment Study Designs, and EvidencesLou CalderonNoch keine Bewertungen
- Practical Research 2 NotesDokument16 SeitenPractical Research 2 Notesprincessbiana07Noch keine Bewertungen
- Hassan - Andwang.2017.ebm - Bmj. Guidelines For Reporting Meta-Epidemiological Methodology ResearchDokument4 SeitenHassan - Andwang.2017.ebm - Bmj. Guidelines For Reporting Meta-Epidemiological Methodology ResearchmichaellouisgrecoNoch keine Bewertungen
- 57 Article+Text 264 0 10 20190302Dokument6 Seiten57 Article+Text 264 0 10 20190302linksheildNoch keine Bewertungen
- Chemometrics in Brewinga Review 2001Dokument11 SeitenChemometrics in Brewinga Review 2001fgdoro6668Noch keine Bewertungen
- Statistical Method from the Viewpoint of Quality ControlVon EverandStatistical Method from the Viewpoint of Quality ControlBewertung: 4.5 von 5 Sternen4.5/5 (5)
- NIH Public Access: Author ManuscriptDokument9 SeitenNIH Public Access: Author ManuscriptDiego Vargas DNoch keine Bewertungen
- Useful Numbers Y14472 Useful NmbrsDokument1 SeiteUseful Numbers Y14472 Useful NmbrsnanopearlNoch keine Bewertungen
- Mobile Computer MC93 - NI: DatasheetDokument3 SeitenMobile Computer MC93 - NI: DatasheetDiego Vargas DNoch keine Bewertungen
- Richter MNKDokument6 SeitenRichter MNKDiego Vargas DNoch keine Bewertungen
- Biomarcadores Clase PDFDokument17 SeitenBiomarcadores Clase PDFDiego Vargas DNoch keine Bewertungen
- Mobile Computer MC93 - NI: DatasheetDokument3 SeitenMobile Computer MC93 - NI: DatasheetDiego Vargas DNoch keine Bewertungen
- Useful Numbers Y14472 Useful NmbrsDokument1 SeiteUseful Numbers Y14472 Useful NmbrsnanopearlNoch keine Bewertungen
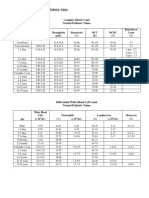
- 30a2131 Complete Blood Count Normal Pediatric Values PDFDokument1 Seite30a2131 Complete Blood Count Normal Pediatric Values PDFReziel Basilan Manalo100% (2)
- 30a2131 Complete Blood Count Normal Pediatric Values PDFDokument1 Seite30a2131 Complete Blood Count Normal Pediatric Values PDFReziel Basilan Manalo100% (2)
- ACFrOgDaDf6giEf-Qwdk4J4eCXZNfl8dO8qlTOSHMeaWT4gqnb3bbFgrW1q HeRAKnr2cN hKaAOGtKWpFvgbZ45gQNLi1IO-LQpoEEKrejMugQPySHs9eev5EJ9 LyDokument8 SeitenACFrOgDaDf6giEf-Qwdk4J4eCXZNfl8dO8qlTOSHMeaWT4gqnb3bbFgrW1q HeRAKnr2cN hKaAOGtKWpFvgbZ45gQNLi1IO-LQpoEEKrejMugQPySHs9eev5EJ9 LyDiego Vargas DNoch keine Bewertungen
- LOPA Misapplied - CommonErrors Can Lead ToIncorrect ConclusionsDokument8 SeitenLOPA Misapplied - CommonErrors Can Lead ToIncorrect ConclusionsDiego Vargas DNoch keine Bewertungen
- Key Issues With Implementing LOPADokument5 SeitenKey Issues With Implementing LOPADiego Vargas D100% (1)
- 11.3 D15c - Manual CommissioningDokument2 Seiten11.3 D15c - Manual CommissioningDiego Vargas DNoch keine Bewertungen
- Table of ContentsDokument1 SeiteTable of ContentsDiego Vargas DNoch keine Bewertungen
- Medical Clinics of North America Volume 101 Issue 3 2017 (Doi 10.1016 - J.mcna.2016.12.011) Fayfman, Maya Pasquel, Francisco J. Umpierrez, Guillermo E. - Management of Hyperglycemic CrisesDokument20 SeitenMedical Clinics of North America Volume 101 Issue 3 2017 (Doi 10.1016 - J.mcna.2016.12.011) Fayfman, Maya Pasquel, Francisco J. Umpierrez, Guillermo E. - Management of Hyperglycemic CrisesBlanca Herrera MoralesNoch keine Bewertungen
- 11.3 D15c - Manual CommissioningDokument2 Seiten11.3 D15c - Manual CommissioningDiego Vargas DNoch keine Bewertungen
- Table of ContentsDokument1 SeiteTable of ContentsDiego Vargas DNoch keine Bewertungen
- Tri-Phase TrainingDokument49 SeitenTri-Phase TrainingSixp8ck100% (1)
- PDEng BrochureDokument4 SeitenPDEng BrochureDiego Vargas DNoch keine Bewertungen
- El LibtoDokument113 SeitenEl LibtoDiego Vargas DNoch keine Bewertungen
- Tri-Phase TrainingDokument49 SeitenTri-Phase TrainingSixp8ck100% (1)
- Basic Anabolic: Hypertrophy TrainingDokument23 SeitenBasic Anabolic: Hypertrophy TrainingDiego Vargas DNoch keine Bewertungen
- Castromayorga2018 (2) - Pages-1-10Dokument10 SeitenCastromayorga2018 (2) - Pages-1-10Diego Vargas DNoch keine Bewertungen
- DR P Muredzisreviewpaper5Dokument311 SeitenDR P Muredzisreviewpaper5Diego Vargas DNoch keine Bewertungen
- Chicago NarcoticsDokument1.638 SeitenChicago NarcoticsPablo MorenoNoch keine Bewertungen
- Structural Basis of GD2 Ganglioside and Mimetic Peptide Recognition by 14g2a AntibodyDokument15 SeitenStructural Basis of GD2 Ganglioside and Mimetic Peptide Recognition by 14g2a AntibodyDiego Vargas DNoch keine Bewertungen
- Structural Basis of GD2 Ganglioside and Mimetic Peptide Recognition by 14g2a AntibodyDokument14 SeitenStructural Basis of GD2 Ganglioside and Mimetic Peptide Recognition by 14g2a AntibodyDiego Vargas DNoch keine Bewertungen
- Hinomoto Tractor Parts Catalogue 2018 C144, C174, E150, E180, E230, E250, E280, E384Dokument63 SeitenHinomoto Tractor Parts Catalogue 2018 C144, C174, E150, E180, E230, E250, E280, E384Monica Mascarenhas0% (1)
- Worksheet 3 (Partial Pressures)Dokument2 SeitenWorksheet 3 (Partial Pressures)Jose Ruben SortoNoch keine Bewertungen
- Hazard & Turn Signal Lamp CircuitDokument2 SeitenHazard & Turn Signal Lamp CircuitTanya PiriyabunharnNoch keine Bewertungen
- Uptime KitsDokument3 SeitenUptime KitsMtto Materia PrimaNoch keine Bewertungen
- Immunology 2Dokument50 SeitenImmunology 2niripsaNoch keine Bewertungen
- Infant of A Diabetic MotherDokument17 SeitenInfant of A Diabetic MotherLovina Falendini AndriNoch keine Bewertungen
- Fact Sheeton Canola OilDokument15 SeitenFact Sheeton Canola OilMonika ThadeaNoch keine Bewertungen
- VF (Kyhkkjrh VK Qfozkkulalfkku) - F'KDS"K) MRRJK (K.M& 249201Dokument3 SeitenVF (Kyhkkjrh VK Qfozkkulalfkku) - F'KDS"K) MRRJK (K.M& 249201RajaNoch keine Bewertungen
- A Very Old MachineDokument20 SeitenA Very Old MachineSwathi G. SalemNoch keine Bewertungen
- Factorisation PDFDokument3 SeitenFactorisation PDFRaj Kumar0% (1)
- Symmetry & Space GroupsDokument49 SeitenSymmetry & Space GroupsfaysaljamilNoch keine Bewertungen
- Strength of Materials: 2. Assume Missing Data, If Any, SuitablyDokument2 SeitenStrength of Materials: 2. Assume Missing Data, If Any, SuitablynvnrevNoch keine Bewertungen
- EPTT5100 - Pressure - Temperature Sensor - 1308 - GDokument2 SeitenEPTT5100 - Pressure - Temperature Sensor - 1308 - GHendry Putra RahadiNoch keine Bewertungen
- BNB SB0114Dokument4 SeitenBNB SB0114graziana100% (2)
- Power and Propulsion PDFDokument13 SeitenPower and Propulsion PDFahmedalgaloNoch keine Bewertungen
- Fire AlarmDokument18 SeitenFire AlarmgauriNoch keine Bewertungen
- CP Lithium Ion BatteriesDokument4 SeitenCP Lithium Ion BatteriesvaseemalikhanNoch keine Bewertungen
- Barge 180Ft Deck Load Capacity & Strength-Rev1Dokument52 SeitenBarge 180Ft Deck Load Capacity & Strength-Rev1Wahyu Codyr86% (7)
- Buk Uuuuuu UuuuuuuDokument92 SeitenBuk Uuuuuu UuuuuuuJanaliyaNoch keine Bewertungen
- Measuring Salinity in Crude Oils Evaluation of MetDokument9 SeitenMeasuring Salinity in Crude Oils Evaluation of Metarmando fuentesNoch keine Bewertungen
- Iso TR 16922 2013 (E)Dokument18 SeitenIso TR 16922 2013 (E)Freddy Santiago Cabarcas LandinezNoch keine Bewertungen
- Ded Deliverable List: As Per 19-08-2016Dokument2 SeitenDed Deliverable List: As Per 19-08-2016Isna MuthoharohNoch keine Bewertungen
- J. Agric. Food Chem. 2005, 53, 9010-9016Dokument8 SeitenJ. Agric. Food Chem. 2005, 53, 9010-9016Jatyr OliveiraNoch keine Bewertungen
- Assay - Alumina and Magnesia Oral SuspensionDokument3 SeitenAssay - Alumina and Magnesia Oral SuspensionmaimaiNoch keine Bewertungen
- C P P P: Rain'S Etrophysical Ocket ALDokument54 SeitenC P P P: Rain'S Etrophysical Ocket ALviya7100% (4)
- Sample Paper English: Kendriya Vidyalaya SangathanDokument7 SeitenSample Paper English: Kendriya Vidyalaya SangathanVines and ScienceNoch keine Bewertungen
- Danas Si Moja I BozijaDokument1 SeiteDanas Si Moja I BozijaMoj DikoNoch keine Bewertungen
- 1Dokument3 Seiten1Pradeep PunterNoch keine Bewertungen
- Honda XL700VA9 Parts Catalogue Final PDFDokument78 SeitenHonda XL700VA9 Parts Catalogue Final PDFangeloNoch keine Bewertungen