Das könnte Ihnen auch gefallen
- Proc de Datos MasivosDokument5 SeitenProc de Datos MasivosLaura Mariana LiedtkeNoch keine Bewertungen
- Caracteristicas BIG DATA PDFDokument31 SeitenCaracteristicas BIG DATA PDFfrankNoch keine Bewertungen
- BigdataDokument20 SeitenBigdataMERARI ANGELICA PERDOMO FIGUEROANoch keine Bewertungen
- Big Data Preprocesamiento y Calidad de DatosDokument5 SeitenBig Data Preprocesamiento y Calidad de Datostatiana bautistaNoch keine Bewertungen
- Big data, machine learning y data science en pythonVon EverandBig data, machine learning y data science en pythonNoch keine Bewertungen
- Big Data ModelosDokument17 SeitenBig Data ModelosGERLING ROBINSON MORENO FERNANDEZNoch keine Bewertungen
- Conceptos y Aplicaciones de Big DataDokument6 SeitenConceptos y Aplicaciones de Big Dataenanobrillante-1Noch keine Bewertungen
- Tema03-Minería de Datos-Ciencia de Datos - 2015-16Dokument131 SeitenTema03-Minería de Datos-Ciencia de Datos - 2015-16karen dejoNoch keine Bewertungen
- Revista Dialnet Big Data PDFDokument24 SeitenRevista Dialnet Big Data PDFDaniel WesteNoch keine Bewertungen
- Dialnet BigData 5920780Dokument24 SeitenDialnet BigData 5920780Daniel WesteNoch keine Bewertungen
- Macrodatos - Wikipedia, La Enciclopedia LibreDokument1 SeiteMacrodatos - Wikipedia, La Enciclopedia LibreNieves LizaurNoch keine Bewertungen
- Big Data TFIDokument10 SeitenBig Data TFIfamsuaherr famsuaherrNoch keine Bewertungen
- Proyecto Bigdata HadoopDokument16 SeitenProyecto Bigdata HadoopJamesNoch keine Bewertungen
- Fic1603 s7 Big Data PDFDokument17 SeitenFic1603 s7 Big Data PDFBastianNoch keine Bewertungen
- Tema 5Dokument11 SeitenTema 5AngelDavidSotoArnaezNoch keine Bewertungen
- Tema 5Dokument11 SeitenTema 5AngelDavidSotoArnaezNoch keine Bewertungen
- Adrian Alcantara E2.1Dokument10 SeitenAdrian Alcantara E2.1Adrian Alcantara ReyesNoch keine Bewertungen
- Documento Sin TítuloDokument8 SeitenDocumento Sin Títulofrancisco javier reyes vargasNoch keine Bewertungen
- MacrodatosDokument28 SeitenMacrodatosItalo FerraraNoch keine Bewertungen
- 1 Intro Ciencia Datos - ACMDokument88 Seiten1 Intro Ciencia Datos - ACMManuel Alejandro Contreras CortezNoch keine Bewertungen
- Big DataDokument6 SeitenBig DataIan Espejo LuqueNoch keine Bewertungen
- Nuevo Documento de Microsoft WordDokument7 SeitenNuevo Documento de Microsoft WordRene saltosNoch keine Bewertungen
- Encuentro No 1 Consulta ReflexivaDokument7 SeitenEncuentro No 1 Consulta ReflexivaJason PeñuelaNoch keine Bewertungen
- Ensayo Big DataDokument15 SeitenEnsayo Big DataTatiana MoraNoch keine Bewertungen
- (22140146) Yerson CharcaDokument3 Seiten(22140146) Yerson CharcaMOISES CHACOLLA SOTONoch keine Bewertungen
- Conociendo Big DataDokument13 SeitenConociendo Big DataJhon Dalton Cáceres QuispeNoch keine Bewertungen
- Conociendo Big DataDokument16 SeitenConociendo Big DataEdgar Cruz GomezNoch keine Bewertungen
- Big DataDokument25 SeitenBig DataAli Hdez BlanchNoch keine Bewertungen
- Resumen Paper - Big DataDokument9 SeitenResumen Paper - Big DataNiikoo MoralesNoch keine Bewertungen
- MacrodatosDokument24 SeitenMacrodatosDenis Rios RamosNoch keine Bewertungen
- CPDokument8 SeitenCPrafael montañoNoch keine Bewertungen
- BrochureBigData PDFDokument14 SeitenBrochureBigData PDFAndres TeranNoch keine Bewertungen
- MacrodatosDokument29 SeitenMacrodatosSaúl GuachaminNoch keine Bewertungen
- 8451 44403 2 PBDokument12 Seiten8451 44403 2 PBAlex Minguzzi100% (1)
- Big Data 2Dokument26 SeitenBig Data 2David GomezNoch keine Bewertungen
- Datos GeneralesDokument3 SeitenDatos Generaleskarelly molinaNoch keine Bewertungen
- Big Data FinalDokument22 SeitenBig Data Finalcesar henriquezNoch keine Bewertungen
- Big Data para Ejecutivos y Profesionales: Big Data, #1Von EverandBig Data para Ejecutivos y Profesionales: Big Data, #1Noch keine Bewertungen
- Actividad 2Dokument17 SeitenActividad 2BRYAN KEVIN MURGA GUEVARANoch keine Bewertungen
- Ensayo Big DataDokument6 SeitenEnsayo Big Datatatiana bautistaNoch keine Bewertungen
- Concepto de BigDataDokument36 SeitenConcepto de BigDataEsteban VasquezNoch keine Bewertungen
- Big Data Grupo 6Dokument12 SeitenBig Data Grupo 6Juan QuinchiguangoNoch keine Bewertungen
- 1.3perfiles Profesionales Del Big DataDokument6 Seiten1.3perfiles Profesionales Del Big DataFacundo MartinezNoch keine Bewertungen
- Big Data Analytics Oportunidades Retos PDFDokument20 SeitenBig Data Analytics Oportunidades Retos PDFsoniarodasNoch keine Bewertungen
- A14 DGRDokument5 SeitenA14 DGRXime RangelNoch keine Bewertungen
- Cuestionario DiagnósticoDokument3 SeitenCuestionario DiagnósticoAvendaño Avendaño ViridianaNoch keine Bewertungen
- Articulo Big Data de Angel Gomez DegravesDokument17 SeitenArticulo Big Data de Angel Gomez DegravesWalter EliasNoch keine Bewertungen
- FHerreraDokument26 SeitenFHerreramariaNoch keine Bewertungen
- A12 Investigación Big Data Grupo 6Dokument17 SeitenA12 Investigación Big Data Grupo 6Samuel ArguetaNoch keine Bewertungen
- Big DataDokument19 SeitenBig DataEdwin MedinaNoch keine Bewertungen
- PresentacionDokument3 SeitenPresentacionricardo cruz montillaNoch keine Bewertungen
- Big DataDokument6 SeitenBig DataSergio OrtegaNoch keine Bewertungen
- Clase 0 - Introducción A La Ciencia de DatosDokument61 SeitenClase 0 - Introducción A La Ciencia de DatosJuan Cortez ZamarNoch keine Bewertungen
- Trabajo Big DataDokument6 SeitenTrabajo Big DataAnibal ReyesNoch keine Bewertungen
- Tema I-Introducción A La Minería de DatosDokument5 SeitenTema I-Introducción A La Minería de DatosCristhopher JimenezNoch keine Bewertungen
- Ensayo Tutoria 1Dokument7 SeitenEnsayo Tutoria 1Andres FierroNoch keine Bewertungen
- Trabajo Final Cloud Frank OtoroncoDokument13 SeitenTrabajo Final Cloud Frank OtoroncoCristian alexsander nieto MartínezNoch keine Bewertungen
- Unidad-1 Big Data-1Dokument29 SeitenUnidad-1 Big Data-1UnMinutoConROBERTNoch keine Bewertungen
- Equipo #7 A12Dokument16 SeitenEquipo #7 A12Samuel ArguetaNoch keine Bewertungen
- Ciencia de datos: La serie de conocimientos esenciales de MIT PressVon EverandCiencia de datos: La serie de conocimientos esenciales de MIT PressBewertung: 5 von 5 Sternen5/5 (1)
- Guia Buenas Practicas Voladuras BancoDokument130 SeitenGuia Buenas Practicas Voladuras BancoAna Abanto AraujoNoch keine Bewertungen
- Perforacion Con Martillo de Fondo SIPERVOR 2011 ADokument74 SeitenPerforacion Con Martillo de Fondo SIPERVOR 2011 ADinoYancachajllaNoch keine Bewertungen
- Vola DurasDokument12 SeitenVola DurasRodrigo González Silva100% (1)
- Analisis y Optimizacion Del Proceso de Perforacion y Tronadura en CML PDFDokument161 SeitenAnalisis y Optimizacion Del Proceso de Perforacion y Tronadura en CML PDFDinoYancachajllaNoch keine Bewertungen
- Rumbo Minero Ed.109Dokument204 SeitenRumbo Minero Ed.109DinoYancachajllaNoch keine Bewertungen
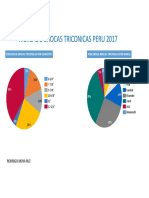
- Mercado Brocas Triconicas Peru 2017Dokument3 SeitenMercado Brocas Triconicas Peru 2017DinoYancachajllaNoch keine Bewertungen
- Dimensionamiento Optimo de Flotas SGEDokument7 SeitenDimensionamiento Optimo de Flotas SGEOscar E. Figueroa BeltránNoch keine Bewertungen
- Manual para El Control y Diseno de Voladuras en Obras de Carreteras - MOPTDokument378 SeitenManual para El Control y Diseno de Voladuras en Obras de Carreteras - MOPTDinoYancachajllaNoch keine Bewertungen
- RM99 ComprimidoDokument294 SeitenRM99 ComprimidoDinoYancachajllaNoch keine Bewertungen
- Agamben - Experimentum LinguaeDokument7 SeitenAgamben - Experimentum LinguaeSilvana JordánNoch keine Bewertungen
- Bases Del Concurso Talent Show 2021 Por Aniversario Del MIDISDokument7 SeitenBases Del Concurso Talent Show 2021 Por Aniversario Del MIDISmayraNoch keine Bewertungen
- Informe de ConductaDokument7 SeitenInforme de ConductaNemy RamirezNoch keine Bewertungen
- Historia de LKDokument15 SeitenHistoria de LKJesús Luis Zamudio Bernabe100% (1)
- Copia de Factores Que Influyen en La Elección de Carrera Universitaria de La Mujer - DANNA ALEJANDRA DURAN DUARTEDokument93 SeitenCopia de Factores Que Influyen en La Elección de Carrera Universitaria de La Mujer - DANNA ALEJANDRA DURAN DUARTEtaher aiffaNoch keine Bewertungen
- Consejo de Educación Secundaria. BPS #Empresa: 3599021 C.I.: Nombre: Administración Nacional de Educación PúblicaDokument1 SeiteConsejo de Educación Secundaria. BPS #Empresa: 3599021 C.I.: Nombre: Administración Nacional de Educación PúblicaMarcelo CassinelliNoch keine Bewertungen
- Sebastián Picasso 1257Dokument15 SeitenSebastián Picasso 1257TâmaraBritoNoch keine Bewertungen
- MuralDokument1 SeiteMuralDiana MHNoch keine Bewertungen
- Valls 2017Dokument44 SeitenValls 2017aadriNoch keine Bewertungen
- Informe de Actividades de Fin de Curso Informática 2009 - 2010Dokument10 SeitenInforme de Actividades de Fin de Curso Informática 2009 - 2010Ing. Gerardo Sánchez Nájera50% (4)
- Encuesta EmocionalDokument3 SeitenEncuesta EmocionalOmar ArteagaNoch keine Bewertungen
- Articulo 3 - Salud Mental y OcupacionDokument30 SeitenArticulo 3 - Salud Mental y OcupacionMarcela IzquierdoNoch keine Bewertungen
- Exposicion de Artes PlasticasDokument18 SeitenExposicion de Artes PlasticasGabriela Paredes ArocaNoch keine Bewertungen
- "La Escuela Tradicional Es Castradora, Mata Expectativas" - Formación - Economía - EL PAÍSDokument9 Seiten"La Escuela Tradicional Es Castradora, Mata Expectativas" - Formación - Economía - EL PAÍSDerivadas e Integrales sin complicacionesNoch keine Bewertungen
- AutoresDokument60 SeitenAutoresrobertobolivar2021Noch keine Bewertungen
- Desarrollo OrganizacionalDokument9 SeitenDesarrollo OrganizacionalPol TintayaNoch keine Bewertungen
- La Experiencia Del Cuerpo AcuáTico 2Dokument10 SeitenLa Experiencia Del Cuerpo AcuáTico 2Vikyy HernandezNoch keine Bewertungen
- Capítulo IVDokument5 SeitenCapítulo IVKEVIN MAURICIO LÓPEZ MEZANoch keine Bewertungen
- Mono ArgDokument32 SeitenMono ArgLucia Belen MetcalfNoch keine Bewertungen
- Análisis de Objeto Técnico: Impresora de Inyección de TintaDokument15 SeitenAnálisis de Objeto Técnico: Impresora de Inyección de TintaIng. Gerardo Sánchez Nájera100% (22)
- CIRCULAR #006 de 2021 Padres de Familia.Dokument1 SeiteCIRCULAR #006 de 2021 Padres de Familia.303 - ISABELA ALEJANDRA GARCIA ARGUMERONoch keine Bewertungen
- De Las Ordenes Ley 1015 de 2006Dokument5 SeitenDe Las Ordenes Ley 1015 de 2006pedro sierraNoch keine Bewertungen
- Colombia Un País Por ConstruirDokument2 SeitenColombia Un País Por ConstruirFRANKLINNoch keine Bewertungen
- Entrevista A Tiempo Parcial Dialogo InglesDokument3 SeitenEntrevista A Tiempo Parcial Dialogo InglesmpandiapumaNoch keine Bewertungen
- Fichas Bibliográficas LLCDokument3 SeitenFichas Bibliográficas LLCFlor MallquiNoch keine Bewertungen
- Planificacion Unidad Profesiones y Oficios Medio Mayor ADokument20 SeitenPlanificacion Unidad Profesiones y Oficios Medio Mayor AclamolinafNoch keine Bewertungen
- Wa0002Dokument16 SeitenWa0002Luis Miguel POLO SIMÓNNoch keine Bewertungen
- S-2024-2002-0362411-DPS - Petición Respuesta Firma Mecánica-11475981.pdf - S-2024-2002-0362411Dokument16 SeitenS-2024-2002-0362411-DPS - Petición Respuesta Firma Mecánica-11475981.pdf - S-2024-2002-0362411franciscojavierjaramillopazNoch keine Bewertungen
- Catedra ViveroDokument40 SeitenCatedra ViverosdvsdbrNoch keine Bewertungen
- Tesis de Grado: Ingeniería en Gestión de Gobiernos SeccionalesDokument89 SeitenTesis de Grado: Ingeniería en Gestión de Gobiernos SeccionalesFenix Esoterismo BrujeriaNoch keine Bewertungen