Das könnte Ihnen auch gefallen
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryVon EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryBewertung: 3.5 von 5 Sternen3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)Von EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Bewertung: 4.5 von 5 Sternen4.5/5 (120)
- Grit: The Power of Passion and PerseveranceVon EverandGrit: The Power of Passion and PerseveranceBewertung: 4 von 5 Sternen4/5 (588)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaVon EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaBewertung: 4.5 von 5 Sternen4.5/5 (266)
- The Little Book of Hygge: Danish Secrets to Happy LivingVon EverandThe Little Book of Hygge: Danish Secrets to Happy LivingBewertung: 3.5 von 5 Sternen3.5/5 (399)
- Never Split the Difference: Negotiating As If Your Life Depended On ItVon EverandNever Split the Difference: Negotiating As If Your Life Depended On ItBewertung: 4.5 von 5 Sternen4.5/5 (838)
- Shoe Dog: A Memoir by the Creator of NikeVon EverandShoe Dog: A Memoir by the Creator of NikeBewertung: 4.5 von 5 Sternen4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerVon EverandThe Emperor of All Maladies: A Biography of CancerBewertung: 4.5 von 5 Sternen4.5/5 (271)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeVon EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeBewertung: 4 von 5 Sternen4/5 (5794)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyVon EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyBewertung: 3.5 von 5 Sternen3.5/5 (2259)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersVon EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersBewertung: 4.5 von 5 Sternen4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnVon EverandTeam of Rivals: The Political Genius of Abraham LincolnBewertung: 4.5 von 5 Sternen4.5/5 (234)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreVon EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreBewertung: 4 von 5 Sternen4/5 (1090)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceVon EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceBewertung: 4 von 5 Sternen4/5 (895)
- Her Body and Other Parties: StoriesVon EverandHer Body and Other Parties: StoriesBewertung: 4 von 5 Sternen4/5 (821)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureVon EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureBewertung: 4.5 von 5 Sternen4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaVon EverandThe Unwinding: An Inner History of the New AmericaBewertung: 4 von 5 Sternen4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)Von EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Bewertung: 4 von 5 Sternen4/5 (98)
- On Fire: The (Burning) Case for a Green New DealVon EverandOn Fire: The (Burning) Case for a Green New DealBewertung: 4 von 5 Sternen4/5 (73)
- A Fuzzy Logic Temperature Controller For Preterm NeonateDokument16 SeitenA Fuzzy Logic Temperature Controller For Preterm Neonatebudi_umm100% (1)
- ALFM001-3.02 - Solutions For Exercise 1Dokument6 SeitenALFM001-3.02 - Solutions For Exercise 1Ayisha A. GillNoch keine Bewertungen
- Tutorial 1Dokument3 SeitenTutorial 1Shiva YadavNoch keine Bewertungen
- HouseholderDokument9 SeitenHouseholderKhairil Sangbima100% (1)
- Accord Info Matrix: Programming QuestionsDokument19 SeitenAccord Info Matrix: Programming QuestionsSandy Santhosh eNoch keine Bewertungen
- Pima Indian Dibatets - Group Presentation - AiDokument18 SeitenPima Indian Dibatets - Group Presentation - AiMuhammad NomanNoch keine Bewertungen
- LAB 10 - Implementation of Discrete-Time FiltersDokument13 SeitenLAB 10 - Implementation of Discrete-Time FiltersM Hassan BashirNoch keine Bewertungen
- Date Subject Unit Topic Name: Overview of SQL InjectionDokument4 SeitenDate Subject Unit Topic Name: Overview of SQL InjectionKshitija KulkarniNoch keine Bewertungen
- AI Foundations and Applications: 4. Linear RegressionDokument31 SeitenAI Foundations and Applications: 4. Linear RegressionLavidaNoch keine Bewertungen
- Controller Tuning With EvDokument228 SeitenController Tuning With EvCONTROLLER ENGENHARIANoch keine Bewertungen
- Fourier AnalysisDokument7 SeitenFourier AnalysisThato Will MongaleNoch keine Bewertungen
- The German eID-Card by Jens BenderDokument42 SeitenThe German eID-Card by Jens BenderPoomjit SirawongprasertNoch keine Bewertungen
- Operation Research - II Goal Programming Industrial III Yr: Topic: Branch & YearDokument26 SeitenOperation Research - II Goal Programming Industrial III Yr: Topic: Branch & YearPrajwal RahangdaleNoch keine Bewertungen
- R Programming Exam: InstructionsDokument2 SeitenR Programming Exam: InstructionsMicheal GoNoch keine Bewertungen
- Credit Card Fraud DetectDokument19 SeitenCredit Card Fraud DetectVikas BankarNoch keine Bewertungen
- CS402 FinalTerm Solved Subjective by MoaazDokument18 SeitenCS402 FinalTerm Solved Subjective by MoaazKinza100% (2)
- SYSC 3500 Lab 4 F21Dokument2 SeitenSYSC 3500 Lab 4 F21Muhammad YousafNoch keine Bewertungen
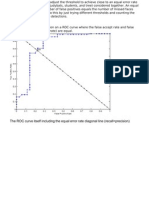
- The ROC Curve Itself Including The Equal Error Rate Diagonal Line (Recall Precision)Dokument3 SeitenThe ROC Curve Itself Including The Equal Error Rate Diagonal Line (Recall Precision)OndelettaNoch keine Bewertungen
- Java Assignment 1Dokument4 SeitenJava Assignment 1Sonaal KalraNoch keine Bewertungen
- Numerical Analysis: Prof. Dr. Süheyla ÇEHRELİDokument15 SeitenNumerical Analysis: Prof. Dr. Süheyla ÇEHRELİEzgi GeyikNoch keine Bewertungen
- Ann PMDokument1 SeiteAnn PMfaizanNoch keine Bewertungen
- VL2020210104311 Fat PDFDokument6 SeitenVL2020210104311 Fat PDFviswaNoch keine Bewertungen
- Polynomial-Basic ConceptsDokument15 SeitenPolynomial-Basic ConceptsPOke wOrlDNoch keine Bewertungen
- Midterm SolutionDokument6 SeitenMidterm SolutionYu LindaNoch keine Bewertungen
- Problem Bank 06: Assignment IDokument10 SeitenProblem Bank 06: Assignment IPuneethHjNoch keine Bewertungen
- Entropy PDFDokument19 SeitenEntropy PDFcarlogarroNoch keine Bewertungen
- Problem Formulation: Day-Ahead ESS Scheduling ModelDokument1 SeiteProblem Formulation: Day-Ahead ESS Scheduling ModelxuxuNoch keine Bewertungen
- Simulated Annealing For The Optimisation of A Constrained Simulation Model in ExcellDokument19 SeitenSimulated Annealing For The Optimisation of A Constrained Simulation Model in Excelllcm3766lNoch keine Bewertungen
- Biogpt: Generative Pre-Trained Transformer For Biomedical Text Generation and MiningDokument12 SeitenBiogpt: Generative Pre-Trained Transformer For Biomedical Text Generation and MiningAnna Haratym-RojekNoch keine Bewertungen
- Quantization and Sampling Using MatlabDokument3 SeitenQuantization and Sampling Using MatlabAbdullah SalemNoch keine Bewertungen