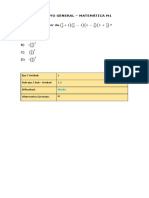
Das könnte Ihnen auch gefallen
- Tarea 3 Regresión Lineal MúltipleDokument17 SeitenTarea 3 Regresión Lineal MúltipleFernanda S.100% (2)
- Analisis ResidualDokument3 SeitenAnalisis ResidualRodrigo Cristóbal0% (1)
- Regresión Lineal Simple y MúltipleDokument6 SeitenRegresión Lineal Simple y MúltipleIsrael Aguirre100% (2)
- Ejercicios Resueltos de Regresion Lineal MultipleDokument24 SeitenEjercicios Resueltos de Regresion Lineal Multiplegriselda rojas67% (3)
- Pruebas de Bondad de Ajuste y Rpeubas No ParamétricasDokument38 SeitenPruebas de Bondad de Ajuste y Rpeubas No ParamétricasGely Rosas100% (1)
- Estadistica Inferencial 5 UnidadDokument18 SeitenEstadistica Inferencial 5 UnidadJair RiveraNoch keine Bewertungen
- Regresion No LinealDokument32 SeitenRegresion No LinealEdson Valery Ramos PeñalozaNoch keine Bewertungen
- Modelo de Regresión Lineal MúltipleDokument28 SeitenModelo de Regresión Lineal MúltipleOmar Hidalgo100% (2)
- 2Dokument8 Seiten2Wilfredo PariNoch keine Bewertungen
- 5.1 Inferencia Estadística Concepto, Estimación, Prueba de HipótesisDokument3 Seiten5.1 Inferencia Estadística Concepto, Estimación, Prueba de HipótesisAngel GonzalezNoch keine Bewertungen
- 417 - Modelos de RegresiónDokument16 Seiten417 - Modelos de RegresiónpuanNoch keine Bewertungen
- Unidad V Regresion Lineal Equipo 5Dokument11 SeitenUnidad V Regresion Lineal Equipo 5Alain A. Gómez CárdenasNoch keine Bewertungen
- Regresión Lineal SimpleDokument9 SeitenRegresión Lineal SimpleJorgeNoch keine Bewertungen
- Regresion No LinealDokument10 SeitenRegresion No LinealSan Marcos Estadistica80% (5)
- Regresion Lineal Simple y MultipleDokument31 SeitenRegresion Lineal Simple y MultiplejoelNoch keine Bewertungen
- Calidad del ajuste en regresión lineal simple: R2 y su interpretaciónDokument3 SeitenCalidad del ajuste en regresión lineal simple: R2 y su interpretaciónHector UchihaNoch keine Bewertungen
- Prueba de Hipotesis para La VarianzaDokument3 SeitenPrueba de Hipotesis para La VarianzaCristina RiosNoch keine Bewertungen
- Distribución Muestral de La Diferencia de Medias PDFDokument16 SeitenDistribución Muestral de La Diferencia de Medias PDFcyndi susana75% (16)
- 5.2 y 5.3 Investigación de OperacionesDokument27 Seiten5.2 y 5.3 Investigación de OperacionesCarlos Ermilo Chan SantosNoch keine Bewertungen
- Regresión Lineal Simple FormularioDokument5 SeitenRegresión Lineal Simple Formularioniti100% (1)
- Unidad 4 CanulDokument10 SeitenUnidad 4 CanulBarrios Rodriguez Irving ArturoNoch keine Bewertungen
- Regresión Lineal Multiple EI2Dokument13 SeitenRegresión Lineal Multiple EI2Dulce María GarcíaNoch keine Bewertungen
- Análisis de serie de tiempo para predecir turismoDokument16 SeitenAnálisis de serie de tiempo para predecir turismoMaria Fernanda DiazNoch keine Bewertungen
- Correlacion 1Dokument20 SeitenCorrelacion 1Mario GómezNoch keine Bewertungen
- La Distribución UniformeDokument16 SeitenLa Distribución UniformeMIGUELHG123Noch keine Bewertungen
- Unidad 2 EstimaciónDokument10 SeitenUnidad 2 EstimaciónJason FoleyNoch keine Bewertungen
- Unidad V: Regresión Lineal Simple.Dokument24 SeitenUnidad V: Regresión Lineal Simple.Jorge Anfibio Garduza AlorNoch keine Bewertungen
- Pruebas de Bondad de AjusteDokument6 SeitenPruebas de Bondad de AjusteRobby Ryan100% (1)
- Prueba de Bondad de AjusteDokument12 SeitenPrueba de Bondad de AjusteRodrigo De La Cruz100% (3)
- Regresion Lineal Múltiple (RLM)Dokument12 SeitenRegresion Lineal Múltiple (RLM)Grecia LópezNoch keine Bewertungen
- Prueba de hipótesis varianzaDokument13 SeitenPrueba de hipótesis varianzaKevin DominguezchavezNoch keine Bewertungen
- Regresión Lineal MultipleDokument10 SeitenRegresión Lineal MultipleLeo Jimenez100% (1)
- Regresión MúltipleDokument15 SeitenRegresión MúltipleFrancisco JavierNoch keine Bewertungen
- Estimación de La Proporción de La PoblaciónDokument4 SeitenEstimación de La Proporción de La PoblaciónMariaAlejandraLineroNoch keine Bewertungen
- Unidad 4 Estadistica InferencialDokument6 SeitenUnidad 4 Estadistica InferencialIzamar Garcia Rodriguez75% (4)
- Equipo 8 EstadisticaDokument5 SeitenEquipo 8 EstadisticaAngel Barragan Robles0% (1)
- Analisis Varianza 2009Dokument74 SeitenAnalisis Varianza 2009cr_2211Noch keine Bewertungen
- Gráficos NP monitorean defectosDokument5 SeitenGráficos NP monitorean defectosVivian HernándezNoch keine Bewertungen
- Aproximación de La Nomial A La BinomialDokument15 SeitenAproximación de La Nomial A La BinomialKeimer SapatangaNoch keine Bewertungen
- Unidad II EstimacionDokument25 SeitenUnidad II EstimacionMarco Saldaña50% (2)
- Regresión Lineal Simple y MultipleDokument26 SeitenRegresión Lineal Simple y Multiplecristopher leon marceloNoch keine Bewertungen
- Correlacion y Regresion LinealDokument13 SeitenCorrelacion y Regresion LinealProfe Alexis RojasNoch keine Bewertungen
- Pruebas de Bondad de AjusteDokument5 SeitenPruebas de Bondad de AjusteDennis Chacón LópezNoch keine Bewertungen
- Intervalos de Confianza para Dos MuestrasDokument4 SeitenIntervalos de Confianza para Dos MuestrasLuis Perez MarquezNoch keine Bewertungen
- CAPITULO4 Supuestos de NormalidadDokument11 SeitenCAPITULO4 Supuestos de NormalidadFlor Chura YucraNoch keine Bewertungen
- Propiedades y Pruebas Estadísticas de Números Pseudo AleatoriosDokument9 SeitenPropiedades y Pruebas Estadísticas de Números Pseudo AleatoriosFélix Leobardo Sánchez VidalNoch keine Bewertungen
- 1.1.2 Calidad de Ajuste y 1.1.3 Intervalo de ConfianzaDokument8 Seiten1.1.2 Calidad de Ajuste y 1.1.3 Intervalo de ConfianzaUlises Diaz Castillo100% (1)
- Regresión lineal múltiple: introducción al modelo, estimación y predicciónDokument19 SeitenRegresión lineal múltiple: introducción al modelo, estimación y predicciónrogerfernandezhidalgNoch keine Bewertungen
- Regresión lineal simple peso-estaturaDokument42 SeitenRegresión lineal simple peso-estaturaYoselin Dayana Banegas HumireNoch keine Bewertungen
- Unidad 3 Analisis de Reg y Correlacion Multiple 2021Dokument10 SeitenUnidad 3 Analisis de Reg y Correlacion Multiple 2021Gaddiel UcNoch keine Bewertungen
- Contabilidad Financiera y Contabilidad AdministrativaDokument3 SeitenContabilidad Financiera y Contabilidad AdministrativaMario SalascruzNoch keine Bewertungen
- Intervalos de ConfianzaDokument29 SeitenIntervalos de Confianzaruben dario maza galofreNoch keine Bewertungen
- Unidad 1. Muestreo Estadístico HVMDokument37 SeitenUnidad 1. Muestreo Estadístico HVMOliver Espada CristobalNoch keine Bewertungen
- Análisis de Series de TiempoDokument32 SeitenAnálisis de Series de TiempoLuis DomenzainNoch keine Bewertungen
- Actividad 3 - Modelo de Regresión Lineal Simple 22Dokument11 SeitenActividad 3 - Modelo de Regresión Lineal Simple 22yira sahiraNoch keine Bewertungen
- Pruebas de HipotesisDokument37 SeitenPruebas de HipotesisPaulyna McCannNoch keine Bewertungen
- Ajustes de Curvas e InterpolacionDokument12 SeitenAjustes de Curvas e InterpolacionKae EikōNoch keine Bewertungen
- TRABAJO Corregido 2Dokument18 SeitenTRABAJO Corregido 2adrian montielNoch keine Bewertungen
- Ecuación Polinómica, Canónica y FactorizadaDokument4 SeitenEcuación Polinómica, Canónica y FactorizadaJazmin Veliz100% (1)
- Guia de Aprendizaje 1 - Matemáticas 6° - 2021Dokument18 SeitenGuia de Aprendizaje 1 - Matemáticas 6° - 2021Joan PalmarNoch keine Bewertungen
- Wa0080.Dokument8 SeitenWa0080.prirom2007Noch keine Bewertungen
- Mecánica de Fluidos - Ec Gen MFDokument19 SeitenMecánica de Fluidos - Ec Gen MFRafaelNoch keine Bewertungen
- Ejercicios Maryflor 2 - EstadísticaDokument3 SeitenEjercicios Maryflor 2 - EstadísticaLorenzo RodriguezNoch keine Bewertungen
- Ley SenoDokument2 SeitenLey SenoAngely AcevedoNoch keine Bewertungen
- Matemática M1: Ejercicios y problemas resueltosDokument65 SeitenMatemática M1: Ejercicios y problemas resueltosCamila ContrerasNoch keine Bewertungen
- Máster de Profesorado en Secundaria (Matemáticas) .: Marcosje@agt - Uva.esDokument2 SeitenMáster de Profesorado en Secundaria (Matemáticas) .: Marcosje@agt - Uva.esVIANEY PÉREZ ALAMILLANoch keine Bewertungen
- Funciones-matemáticas-tiposDokument2 SeitenFunciones-matemáticas-tiposLESLIE LUCIA FLOREZ AVILANoch keine Bewertungen
- Ecuaciones de 1° gradoDokument5 SeitenEcuaciones de 1° gradoBritani CruzNoch keine Bewertungen
- CVTema 06 Represetacion CurvasDokument32 SeitenCVTema 06 Represetacion CurvasDiego Yazha AntonioNoch keine Bewertungen
- Act. 8 - Trabajo de Investigación. Funciones CompuestasDokument5 SeitenAct. 8 - Trabajo de Investigación. Funciones CompuestasSergio Enrique Pérez RivasNoch keine Bewertungen
- Regresión lineal ventas vs publicidadDokument5 SeitenRegresión lineal ventas vs publicidadnuhansaileNoch keine Bewertungen
- Parcelador CalculoDokument3 SeitenParcelador CalculoJulián SantiagoNoch keine Bewertungen
- Suma de matricesDokument13 SeitenSuma de matricesjanierNoch keine Bewertungen
- Silabos para Convalidar CursosDokument148 SeitenSilabos para Convalidar CursosThaliaNoch keine Bewertungen
- Capitulo 1Dokument17 SeitenCapitulo 1perumiguelNoch keine Bewertungen
- Introduccion A Matrices de RedDokument41 SeitenIntroduccion A Matrices de RedFernando CervantesNoch keine Bewertungen
- Mini Ensayo 4Dokument9 SeitenMini Ensayo 4PatriciaNoch keine Bewertungen
- Ballesteros - Maynor-Trabajo de Teoria de Colas-Investigacion de OperacionesDokument18 SeitenBallesteros - Maynor-Trabajo de Teoria de Colas-Investigacion de OperacionesMaynorBallesterosVillamilNoch keine Bewertungen
- Funciones reales: tipos y dominiosDokument1 SeiteFunciones reales: tipos y dominiosRamiro O CFNoch keine Bewertungen
- Solucion Cap Vii Combinado PDFDokument8 SeitenSolucion Cap Vii Combinado PDFJhonn OrdoñezNoch keine Bewertungen
- Funciones Estandar en C++Dokument9 SeitenFunciones Estandar en C++Kike RoaNoch keine Bewertungen
- Curva SolucionDokument16 SeitenCurva SolucionArmando CamposNoch keine Bewertungen
- Clase 4 - Modelos Discretos de ProbabilidadDokument43 SeitenClase 4 - Modelos Discretos de ProbabilidadCamilo BotinaNoch keine Bewertungen
- Cuaderno GeoestadisticaDokument10 SeitenCuaderno GeoestadisticaJhon LupallanoNoch keine Bewertungen
- Resolución de ecuaciones diferenciales lineales de segundo orden no homogéneasDokument7 SeitenResolución de ecuaciones diferenciales lineales de segundo orden no homogéneasLihuelMujicaNoch keine Bewertungen
- Alphacam Menú 3DDokument11 SeitenAlphacam Menú 3DElísabet FarnsworthNoch keine Bewertungen
- Problemas 1.25-6.7 AQDokument11 SeitenProblemas 1.25-6.7 AQMariana TreviñoNoch keine Bewertungen
- Ejercicios de cálculo vectorial y derivadas direccionalesDokument4 SeitenEjercicios de cálculo vectorial y derivadas direccionalesCami TotoyNoch keine Bewertungen