Das könnte Ihnen auch gefallen
- Recomendaciones de Seguridad Anexado Al Contrato de Trabajo. - 3Dokument3 SeitenRecomendaciones de Seguridad Anexado Al Contrato de Trabajo. - 3Nil Córdova78% (9)
- Examen - 6Dokument3 SeitenExamen - 6roger arieñ0% (2)
- HIPOGLUCEMIADokument5 SeitenHIPOGLUCEMIAilmedici100% (2)
- Ensayo Educativo Sobre Estrellas Sobre La TierraDokument3 SeitenEnsayo Educativo Sobre Estrellas Sobre La TierraLizz50% (4)
- Medidas EpidemiológicasDokument18 SeitenMedidas EpidemiológicasJercy Espinoza CastroNoch keine Bewertungen
- Historia y manifestaciones clínicas del mieloma múltipleDokument67 SeitenHistoria y manifestaciones clínicas del mieloma múltipleJaime Salazar100% (1)
- PermanecerEnCristoDokument91 SeitenPermanecerEnCristoEdwin Torres GomezNoch keine Bewertungen
- Eunacom Preparacion Salud PublicaDokument9 SeitenEunacom Preparacion Salud Publicavictorurrutiar100% (4)
- Medidas de Frecuencia en SaludDokument41 SeitenMedidas de Frecuencia en SaludRaquel CruzNoch keine Bewertungen
- Salud PublicaDokument35 SeitenSalud PublicaRider L. Flores A.Noch keine Bewertungen
- Bavette - Es-Tarta de Limón y Merengue SuizoDokument4 SeitenBavette - Es-Tarta de Limón y Merengue SuizoDulce RamirezNoch keine Bewertungen
- Practica 4Dokument9 SeitenPractica 4LUCIA MARIELENA AREVALO GRADOSNoch keine Bewertungen
- 3 Ero - Experiencia 6Dokument10 Seiten3 Ero - Experiencia 6Manuel Enrique Rodriguez CabreraNoch keine Bewertungen
- Observa El Siguiente Video:: V tju95fjc9GADokument10 SeitenObserva El Siguiente Video:: V tju95fjc9GAclaudio lopez alvaNoch keine Bewertungen
- Unidad 8 Actividad 2Dokument4 SeitenUnidad 8 Actividad 2Evelyn CorreaNoch keine Bewertungen
- CRECIMIENTOCURVASDokument57 SeitenCRECIMIENTOCURVASManuel CruzNoch keine Bewertungen
- Niveles de hemoglobina y medidas de tendencia central en adolescentesDokument5 SeitenNiveles de hemoglobina y medidas de tendencia central en adolescentesAlexander Martinez CullancoNoch keine Bewertungen
- Informe de Pensamiento Lógico - Grupo 3Dokument14 SeitenInforme de Pensamiento Lógico - Grupo 3CIELO DANIRA LA ROSA SOLISNoch keine Bewertungen
- Anemia en NinosDokument10 SeitenAnemia en NinosVladimir De La Cruz RamosNoch keine Bewertungen
- Ficha de Trabajo Estudiante - 2Dokument5 SeitenFicha de Trabajo Estudiante - 2MeliiʚïɞDllNoch keine Bewertungen
- Proyecto AnemiaDokument16 SeitenProyecto AnemiaKenyi Gonzales MachadoNoch keine Bewertungen
- Trabajo de EstadisticaDokument5 SeitenTrabajo de EstadisticaDiogenes salazarNoch keine Bewertungen
- Prevalencia de Sobrepeso y Obesidad en Ninos Escolares RevistaDokument7 SeitenPrevalencia de Sobrepeso y Obesidad en Ninos Escolares RevistajuanisNoch keine Bewertungen
- Practica de RiesgoDokument3 SeitenPractica de RiesgoMarlene Reyes GragedaNoch keine Bewertungen
- Presentación r1 2024 YoDokument18 SeitenPresentación r1 2024 YoBrunoNoch keine Bewertungen
- Clases MIP ABCDokument56 SeitenClases MIP ABCAnthoonio RomanoNoch keine Bewertungen
- Biología exámenes pasados intervalo confianza distribuciónDokument3 SeitenBiología exámenes pasados intervalo confianza distribuciónLeoy ZerimarNoch keine Bewertungen
- Taller Variables 1-22Dokument2 SeitenTaller Variables 1-22MIGUEL ENRIQUE OCHOA VERANoch keine Bewertungen
- Obesidad Infantil DiapositivasDokument21 SeitenObesidad Infantil DiapositivasFabiola CastilloNoch keine Bewertungen
- Proyecto de InvestigaciónDokument11 SeitenProyecto de InvestigaciónCarlos Moyon GrandaNoch keine Bewertungen
- Preguntas de Estudios DescriptivosDokument4 SeitenPreguntas de Estudios DescriptivosCecilia ArgañarazNoch keine Bewertungen
- Cuadernillo de Ejercitacion Epidemiologia Unlam - 2021 - 1Dokument23 SeitenCuadernillo de Ejercitacion Epidemiologia Unlam - 2021 - 1Luciana BerriNoch keine Bewertungen
- Caso 2 EpidemiologiaDokument4 SeitenCaso 2 EpidemiologiaLk KNoch keine Bewertungen
- Bioestadística EjerciciosDokument2 SeitenBioestadística Ejercicioscocomz2005Noch keine Bewertungen
- Ses and UndernutritionDokument5 SeitenSes and UndernutritionRaul Morales VillegasNoch keine Bewertungen
- LUISANADokument14 SeitenLUISANALuisana RamayoNoch keine Bewertungen
- RF Articulo 445Dokument7 SeitenRF Articulo 445esteysi floresNoch keine Bewertungen
- Taller2 BioestDokument4 SeitenTaller2 BioestAntonio Barrios Perez100% (1)
- UNIDAD 2 - Actividad 2Dokument13 SeitenUNIDAD 2 - Actividad 2cecyvzNoch keine Bewertungen
- Ejemplos Clase 1 - Conceptos Básicos de EstadísticaDokument6 SeitenEjemplos Clase 1 - Conceptos Básicos de EstadísticaSebastián García TerronesNoch keine Bewertungen
- Plan de Tabulacion y AnalisisDokument9 SeitenPlan de Tabulacion y AnalisisfrandiNoch keine Bewertungen
- Consejería Genética - López Diego y Méndez Steven - PreterminadoDokument55 SeitenConsejería Genética - López Diego y Méndez Steven - PreterminadoSTEVEN WILTER JUNIOR MENDEZ ALVARADONoch keine Bewertungen
- Artículo Sobre Anemia y Eduación Alimentaria 2022Dokument9 SeitenArtículo Sobre Anemia y Eduación Alimentaria 2022Jonatan Zapata CarrascoNoch keine Bewertungen
- Copia de Tema 2. Guía de Ejercicios.2015-C.digDokument4 SeitenCopia de Tema 2. Guía de Ejercicios.2015-C.digSimonet NeumanNoch keine Bewertungen
- Evaluacion Crecimiento y DesarrolloDokument109 SeitenEvaluacion Crecimiento y DesarrolloRaquel ChaupiNoch keine Bewertungen
- Matematic (1 - 2) - Sem29 Experiencia8 Actividad7 Estadistica Ccesa007Dokument13 SeitenMatematic (1 - 2) - Sem29 Experiencia8 Actividad7 Estadistica Ccesa007Demetrio Ccesa Rayme100% (1)
- Factores sociodemográficosDokument10 SeitenFactores sociodemográficosTAIPE VILLAVERDE ROBERTHNoch keine Bewertungen
- Pediatric Diabetic Emergencies - En.esDokument24 SeitenPediatric Diabetic Emergencies - En.eslunadraco9Noch keine Bewertungen
- CLASE S2 Medición en Epidemiología 2023 - 2Dokument61 SeitenCLASE S2 Medición en Epidemiología 2023 - 2AngieNoch keine Bewertungen
- MCcaqubcDokument52 SeitenMCcaqubcSoledad Rosario Vilca RiveraNoch keine Bewertungen
- Informe AnorexiaDokument4 SeitenInforme AnorexiaMartín Raid GARCIA COLLAHUASONoch keine Bewertungen
- Epidemiologia IntroDokument26 SeitenEpidemiologia IntroTiago AngrisaniNoch keine Bewertungen
- Guia de TP de Epidemio'final 2017Dokument26 SeitenGuia de TP de Epidemio'final 2017Lucina BavosaNoch keine Bewertungen
- Salud PublicaDokument13 SeitenSalud PublicaJosé Luis Loor C.Noch keine Bewertungen
- BioestadisticaDokument13 SeitenBioestadisticaLiz KatherineNoch keine Bewertungen
- ANTEPROYECTODokument22 SeitenANTEPROYECTODarwin Dario De la CruzNoch keine Bewertungen
- Tema 11 MorfopatoDokument4 SeitenTema 11 Morfopatoarianna escalonaNoch keine Bewertungen
- Anteproyecto 13-7-2018Dokument85 SeitenAnteproyecto 13-7-2018fabiolaNoch keine Bewertungen
- Factores Socioeconómicos y Alimentarios Asociados Al Niño Alto Juarense en Edad PreescolarDokument44 SeitenFactores Socioeconómicos y Alimentarios Asociados Al Niño Alto Juarense en Edad PreescolarRUT SICLLA V.Noch keine Bewertungen
- Factores asociados a la duración de la lactancia maternaDokument16 SeitenFactores asociados a la duración de la lactancia maternaTerapia de lenguaje PsicopedagogíaNoch keine Bewertungen
- PNNAS-PLANTILLA INF TEMBLADOR Cuatro Muestras18-19Dokument18 SeitenPNNAS-PLANTILLA INF TEMBLADOR Cuatro Muestras18-19Roselena EspinozaNoch keine Bewertungen
- AnemiaPediatríaDokument22 SeitenAnemiaPediatríaMariangel AlcarraNoch keine Bewertungen
- Tema 6-Asesoramiento Genetico-Historia Clinica en Genetica-Diplomado en BiologiaDokument73 SeitenTema 6-Asesoramiento Genetico-Historia Clinica en Genetica-Diplomado en BiologiaMarisabel Calle SolizNoch keine Bewertungen
- Precio, Insumos y Comercializacion de Enrgizante de ChíaDokument4 SeitenPrecio, Insumos y Comercializacion de Enrgizante de ChíaANABEL TERESA TITO ASCUENoch keine Bewertungen
- ENSAYO La GobernabilidadDokument2 SeitenENSAYO La GobernabilidadANABEL TERESA TITO ASCUENoch keine Bewertungen
- Diferencias entre acciones y bonos: tipos de accionesDokument3 SeitenDiferencias entre acciones y bonos: tipos de accionesANABEL TERESA TITO ASCUENoch keine Bewertungen
- INCOTERMS TareaDokument3 SeitenINCOTERMS TareaANABEL TERESA TITO ASCUENoch keine Bewertungen
- La Anemia en El PeruDokument13 SeitenLa Anemia en El PeruANABEL TERESA TITO ASCUENoch keine Bewertungen
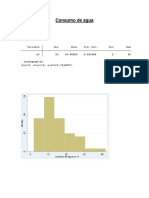
- Consumo de AguaDokument2 SeitenConsumo de AguaANABEL TERESA TITO ASCUENoch keine Bewertungen
- INCOTERMS TareaDokument3 SeitenINCOTERMS TareaANABEL TERESA TITO ASCUENoch keine Bewertungen
- Estado y GobiernoDokument2 SeitenEstado y GobiernoANABEL TERESA TITO ASCUENoch keine Bewertungen
- Consumo de AguaDokument2 SeitenConsumo de AguaANABEL TERESA TITO ASCUENoch keine Bewertungen
- Alicia en El Pais de Las MaravillasDokument56 SeitenAlicia en El Pais de Las MaravillasCarlos AvilaNoch keine Bewertungen
- ACFrOgCK 3kJSRds4AHj-XLyfeEuSTA5-UTNtL4hlqB2DgpSMz5tbrPKTvyQsKUi3ncBtl4dswnY5ikUyEujXztg WSGG-Q Ss02 Aaj4M183c3 FfUSKu1FEA2qdFADokument7 SeitenACFrOgCK 3kJSRds4AHj-XLyfeEuSTA5-UTNtL4hlqB2DgpSMz5tbrPKTvyQsKUi3ncBtl4dswnY5ikUyEujXztg WSGG-Q Ss02 Aaj4M183c3 FfUSKu1FEA2qdFAJuan Sebastian Lobato NavarreteNoch keine Bewertungen
- ObjetivoDokument5 SeitenObjetivoKarla Dayana AriasNoch keine Bewertungen
- BROCHURE - J&F 2023 Junio00Dokument7 SeitenBROCHURE - J&F 2023 Junio00Freddy SitoNoch keine Bewertungen
- 7 Dictamen Farini Dugan PDFDokument9 Seiten7 Dictamen Farini Dugan PDFdaniela herreroNoch keine Bewertungen
- Lenguaje Ensamblador - Semana 3 y 4 - PDokument3 SeitenLenguaje Ensamblador - Semana 3 y 4 - PManuel Ventura OlánNoch keine Bewertungen
- Segunda Distribución Año 2017. Eduardo SierraDokument34 SeitenSegunda Distribución Año 2017. Eduardo SierraAlfredo CasanovaNoch keine Bewertungen
- Metodologia Del Entrenamiento DeportivoDokument3 SeitenMetodologia Del Entrenamiento DeportivoyolimarNoch keine Bewertungen
- Clase y Guía de HistoriaDokument6 SeitenClase y Guía de HistoriaVerónica AndreaNoch keine Bewertungen
- Copia de FICHA DE SEGURIDAD GRANALLA ECOLOGICADokument3 SeitenCopia de FICHA DE SEGURIDAD GRANALLA ECOLOGICAIgnacio OneilNoch keine Bewertungen
- Veterinaria Atoxoplasmosis OMarinDokument2 SeitenVeterinaria Atoxoplasmosis OMarinlobo20110% (1)
- Certificado Rupe 1740223Dokument2 SeitenCertificado Rupe 1740223Juan Pablo Romero MorenoNoch keine Bewertungen
- Tema 1 - La Ilustración y La EducaciónDokument6 SeitenTema 1 - La Ilustración y La Educaciónluis 2002Noch keine Bewertungen
- HojaVida IngenieroMecánicoDokument14 SeitenHojaVida IngenieroMecánicoMauricio PerezNoch keine Bewertungen
- Identifica Los Hormigones de Una Obra de Construcción en Función de LaDokument6 SeitenIdentifica Los Hormigones de Una Obra de Construcción en Función de LaFranco IgnacioNoch keine Bewertungen
- Manifestación de Impacto Ambiental Del Megaproyecto Ecocida MirasierraDokument718 SeitenManifestación de Impacto Ambiental Del Megaproyecto Ecocida MirasierraComité SalvabosqueNoch keine Bewertungen
- HOMÓNIMOSDokument3 SeitenHOMÓNIMOSJack Brothers100% (1)
- Plan de Trabajo de La Semana 2 Del 05 Al 09 de SeptiembreDokument22 SeitenPlan de Trabajo de La Semana 2 Del 05 Al 09 de SeptiembreBen MosheNoch keine Bewertungen
- Clase 33A Excel BASICO - INTERMEDIO - AVANZADO - Ejercicios de Algunos Temas AnterioresDokument6 SeitenClase 33A Excel BASICO - INTERMEDIO - AVANZADO - Ejercicios de Algunos Temas AnterioresLuis PalacioNoch keine Bewertungen
- C Automatas ProgramablesDokument23 SeitenC Automatas ProgramablesEduardo Marcelo RecobaNoch keine Bewertungen
- Benjamin y La Cuestión de La AnimalidadDokument7 SeitenBenjamin y La Cuestión de La AnimalidadAnabella Di PegoNoch keine Bewertungen
- TLR 12020 21 IMM FinalDokument113 SeitenTLR 12020 21 IMM FinalAndrea BonillaNoch keine Bewertungen
- 0 F 809 CDokument12 Seiten0 F 809 CVivían tezNoch keine Bewertungen