Das könnte Ihnen auch gefallen
- Hardee's - Delivery Feasibility StudyDokument42 SeitenHardee's - Delivery Feasibility StudyZohaib H. Shah100% (6)
- DESHPANDE - FARLEY - InT J of RES MARKTNG - Org CULTURE, Market Orientation, Innovativeness, and Firm PERFORMANCE - An International Research OdysseyDokument20 SeitenDESHPANDE - FARLEY - InT J of RES MARKTNG - Org CULTURE, Market Orientation, Innovativeness, and Firm PERFORMANCE - An International Research Odysseyoushiza21Noch keine Bewertungen
- Tabla de Carta de ControlDokument1 SeiteTabla de Carta de ControlKeyLa MaEstre RiCaurteNoch keine Bewertungen
- EIRT Siswa EvaluasiDokument351 SeitenEIRT Siswa EvaluasiDimas Fadili RohmanNoch keine Bewertungen
- ResultDokument8 SeitenResultBinhNoch keine Bewertungen
- Gráficos 3Dokument4 SeitenGráficos 3Juan CampusanoNoch keine Bewertungen
- Gráficos 27Dokument4 SeitenGráficos 27Juan CampusanoNoch keine Bewertungen
- Gráficos 3Dokument4 SeitenGráficos 3Juan CampusanoNoch keine Bewertungen
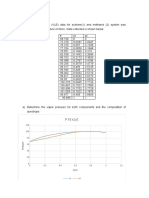
- Correccion: 6.00 7.00 F (X) 0.726895698x + 0.0736424496 R 0.9883306912 Correccion Linear (Correccion)Dokument9 SeitenCorreccion: 6.00 7.00 F (X) 0.726895698x + 0.0736424496 R 0.9883306912 Correccion Linear (Correccion)lolaNoch keine Bewertungen
- Gráficos 3Dokument4 SeitenGráficos 3Juan CampusanoNoch keine Bewertungen
- MSST Lec 4Dokument11 SeitenMSST Lec 4Debjit PaulNoch keine Bewertungen
- Statistical Methods in Nursing Research: Variabl Es Me An S. D. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 1 5Dokument13 SeitenStatistical Methods in Nursing Research: Variabl Es Me An S. D. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 1 5Shane ArroyoNoch keine Bewertungen
- Table A-4: Properties of Saturated LiquidsDokument13 SeitenTable A-4: Properties of Saturated Liquidsكرار عبدالحسين قاسم مسائي 23 BNoch keine Bewertungen
- TABLEZTDokument1 SeiteTABLEZTDave TanabordeeNoch keine Bewertungen
- Hidrostatis Hany BaruDokument12 SeitenHidrostatis Hany BaruRicard La'lang BumbunganNoch keine Bewertungen
- Hidrostatis Hany BaruDokument12 SeitenHidrostatis Hany BaruRicard La'lang BumbunganNoch keine Bewertungen
- Exploratory Factor AnalysisDokument2 SeitenExploratory Factor AnalysisJose Achicahuala MamaniNoch keine Bewertungen
- Database Celullose IBDokument10 SeitenDatabase Celullose IBErina Rizki NugrahaniNoch keine Bewertungen
- Appendix 01Dokument1 SeiteAppendix 01Salma AkhterNoch keine Bewertungen
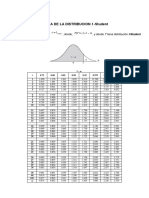
- Distribución T: Grados Área en La Cola Superior de Libertad 0.20 0.10 0.05 0.025 0.01 0.005Dokument3 SeitenDistribución T: Grados Área en La Cola Superior de Libertad 0.20 0.10 0.05 0.025 0.01 0.005nelsy.profe1012Noch keine Bewertungen
- Case SCAL Minggu 1 - Ahmad Akbar - 012 - Plug GDokument57 SeitenCase SCAL Minggu 1 - Ahmad Akbar - 012 - Plug GFREE ZONENoch keine Bewertungen
- Tabla T - StudentDokument1 SeiteTabla T - StudentBryan HidalgoNoch keine Bewertungen
- Pearson R XXXXDokument9 SeitenPearson R XXXXRendon StephenNoch keine Bewertungen
- Variable Control ChartsDokument1 SeiteVariable Control ChartsAhmed AymanNoch keine Bewertungen
- Distribuci On T de StudentDokument2 SeitenDistribuci On T de Studentsantiago marin peñaNoch keine Bewertungen
- Total Segments (N) Length of Segments (H) Integral Value (I)Dokument5 SeitenTotal Segments (N) Length of Segments (H) Integral Value (I)Iskandar Agung AgungNoch keine Bewertungen
- Integral Reiman Integral TrapezoidaDokument32 SeitenIntegral Reiman Integral TrapezoidalianNoch keine Bewertungen
- Tugas 3Dokument32 SeitenTugas 3lianNoch keine Bewertungen
- 04 - Statistic With Computer Application - T-TableDokument1 Seite04 - Statistic With Computer Application - T-TableAustin Capal Dela CruzNoch keine Bewertungen
- MTT 3TC and Tenofovir Day 14Dokument3 SeitenMTT 3TC and Tenofovir Day 14Suyash DhootNoch keine Bewertungen
- Obs. TableDokument2 SeitenObs. Tablemanoj_varma_1Noch keine Bewertungen
- Maths Table ValuesDokument6 SeitenMaths Table ValuesDamoNoch keine Bewertungen
- Bang Tra Xac SuatDokument5 SeitenBang Tra Xac SuatNgọc NguyễnNoch keine Bewertungen
- BgtraDokument5 SeitenBgtraLộc Phạm PhướcNoch keine Bewertungen
- Distributia T (Student)Dokument1 SeiteDistributia T (Student)adina nonameNoch keine Bewertungen
- ThermoooDokument15 SeitenThermoooNor Hamizah HassanNoch keine Bewertungen
- Bang Tra Xử Lý Số LiệuDokument8 SeitenBang Tra Xử Lý Số Liệuánh ngọc lê trầnNoch keine Bewertungen
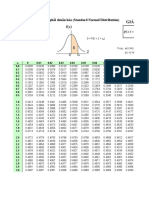
- Bảng tra phân phối chuẩn hóa (Standard Normal Distribution)Dokument8 SeitenBảng tra phân phối chuẩn hóa (Standard Normal Distribution)Nguyễn TrangNoch keine Bewertungen
- La Tabla Da Áreas 1 y Valores, Donde, 1) (, y Donde T Tiene Distribución T-Student Con R Grados de Libertad.Dokument1 SeiteLa Tabla Da Áreas 1 y Valores, Donde, 1) (, y Donde T Tiene Distribución T-Student Con R Grados de Libertad.Alexis Chan ChanNoch keine Bewertungen
- Table - Control ChartDokument1 SeiteTable - Control Chartmscoolmohit21Noch keine Bewertungen
- Percentage Points of The T-Distribution: This Table Was Generated Using ExcelDokument1 SeitePercentage Points of The T-Distribution: This Table Was Generated Using ExcelMohamaad SihatthNoch keine Bewertungen
- Computation of Multipliers: Specify The Survival Column, L (X), and The Cost of Care at Each AgeDokument7 SeitenComputation of Multipliers: Specify The Survival Column, L (X), and The Cost of Care at Each AgeJay WhiteNoch keine Bewertungen
- Tabla T StudentDokument1 SeiteTabla T StudentPatricia Elizabeth Vera FariasNoch keine Bewertungen
- Averages Ranges Number of Items Factors For Factors For Factors For in Sample Control Limits Central Line Control LimitsDokument1 SeiteAverages Ranges Number of Items Factors For Factors For Factors For in Sample Control Limits Central Line Control LimitsKeyur PopatNoch keine Bewertungen
- Test 4Dokument4 SeitenTest 4ROBERTO ANDRES GOMEZ MERCADONoch keine Bewertungen
- cp4 Mektan UlumDokument60 Seitencp4 Mektan UlumJoko WiratmonoNoch keine Bewertungen
- Horizontal Curve Setting Line/ Legs Distance (M) Station Chainage Deflection Angle Radius Tangent Length Length of Curve Apex (E) BC MC EC From ToDokument38 SeitenHorizontal Curve Setting Line/ Legs Distance (M) Station Chainage Deflection Angle Radius Tangent Length Length of Curve Apex (E) BC MC EC From ToRam Prasad NeupaneNoch keine Bewertungen
- Variance Explained: Dimensions / ItemsDokument14 SeitenVariance Explained: Dimensions / ItemsAditi AgrawalNoch keine Bewertungen
- Assignment 11 Team 4 Date 11/19/2018 Ananth Ramesh Qian Ciu Shikhar Goyal Tanish Gupta Vinay Sagar MudlapurDokument45 SeitenAssignment 11 Team 4 Date 11/19/2018 Ananth Ramesh Qian Ciu Shikhar Goyal Tanish Gupta Vinay Sagar MudlapurAnanth RameshNoch keine Bewertungen
- Lab Report E.coliDokument9 SeitenLab Report E.colihasanulfiqryNoch keine Bewertungen
- Gujrati T, F, Chi SQR TablesDokument9 SeitenGujrati T, F, Chi SQR TablesKavya SanjayNoch keine Bewertungen
- Cp4 Mektan JokoDokument60 SeitenCp4 Mektan JokoJoko WiratmonoNoch keine Bewertungen
- cp4 Mektan JokoDokument60 Seitencp4 Mektan JokoJoko WiratmonoNoch keine Bewertungen
- Task 7aDokument3 SeitenTask 7aJun Hao ChongNoch keine Bewertungen
- UntitledDokument1 SeiteUntitledAndres FuentesNoch keine Bewertungen
- Factors Control ChartsDokument1 SeiteFactors Control ChartsWendy BlancoNoch keine Bewertungen
- 3Dokument1 Seite3Hamed basalNoch keine Bewertungen
- UntitledDokument1 SeiteUntitledHamed basalNoch keine Bewertungen
- Math Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesVon EverandMath Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesBewertung: 5 von 5 Sternen5/5 (3)
- LetterDokument1 SeiteLetterAndrioNoch keine Bewertungen
- Buku Panduan LaporanDokument14 SeitenBuku Panduan LaporanAndrioNoch keine Bewertungen
- Min (Neg (W Min (Neg (W: Ak Ij K Ak Ij K Ak Ij KDokument2 SeitenMin (Neg (W Min (Neg (W: Ak Ij K Ak Ij K Ak Ij KAndrioNoch keine Bewertungen
- KnurlingDokument3 SeitenKnurlingAndrioNoch keine Bewertungen
- Pengaruh Literasi Keuangan Dan Literasi Digital TeDokument16 SeitenPengaruh Literasi Keuangan Dan Literasi Digital TeEndang purwaningsihNoch keine Bewertungen
- Applying Social Learning Theory To Police MisconductDokument20 SeitenApplying Social Learning Theory To Police MisconductvilladoloresNoch keine Bewertungen
- OutputDokument2 SeitenOutputMUHAMMED ASHIQ VNoch keine Bewertungen
- Introduction To Statistical Machine LearningDokument84 SeitenIntroduction To Statistical Machine LearningvdjohnNoch keine Bewertungen
- Basic Statistical Techniques in Research: April 2018Dokument37 SeitenBasic Statistical Techniques in Research: April 2018subashNoch keine Bewertungen
- Eco401 Learning ObjectivesDokument14 SeitenEco401 Learning ObjectivesphannyNoch keine Bewertungen
- Full Glossary of Statistics TermsDokument150 SeitenFull Glossary of Statistics Termsshahid 1shahNoch keine Bewertungen
- Defining The Allometry of Stem and Crown Diameter or Urban TreesDokument9 SeitenDefining The Allometry of Stem and Crown Diameter or Urban TreesMiguel XubiasNoch keine Bewertungen
- SSAC15 RP Finalist Graphical Model For Basketball Match Simulation PDFDokument8 SeitenSSAC15 RP Finalist Graphical Model For Basketball Match Simulation PDFVedad PalicNoch keine Bewertungen
- FKTRDokument6 SeitenFKTRKartika PuloguNoch keine Bewertungen
- Deluna2020 PDFDokument10 SeitenDeluna2020 PDFRey P. GumalingNoch keine Bewertungen
- Complexity Metrics For Statechart DiagramsDokument17 SeitenComplexity Metrics For Statechart DiagramsAnonymous rVWvjCRLGNoch keine Bewertungen
- Linear Regression and SVRDokument25 SeitenLinear Regression and SVRARCHANA RNoch keine Bewertungen
- QNT 561 Final Exam - QNT 561 Week 1 Practice Quiz 45 Questions - UOP StudentsDokument36 SeitenQNT 561 Final Exam - QNT 561 Week 1 Practice Quiz 45 Questions - UOP StudentsUOP StudentsNoch keine Bewertungen
- Keywords:-Corporate Income Tax, Profitability, LiquidityDokument12 SeitenKeywords:-Corporate Income Tax, Profitability, LiquidityInternational Journal of Innovative Science and Research TechnologyNoch keine Bewertungen
- 2022 - Top 3 - Predictive Effect of Business Permit Modalities On Selected Economic Indicators Among The Municipalities in The PhilippinesDokument22 Seiten2022 - Top 3 - Predictive Effect of Business Permit Modalities On Selected Economic Indicators Among The Municipalities in The PhilippinesJan Roger YunsalNoch keine Bewertungen
- Microfinance Banks and Economic Growth of NigeriaDokument6 SeitenMicrofinance Banks and Economic Growth of NigeriaRECTEM POLITICS AND GOVERNANCENoch keine Bewertungen
- Soal Uas Statistik Lanjutan Ganjil 2017 2018 Utk Sahril Dewi Ratna SjariDokument9 SeitenSoal Uas Statistik Lanjutan Ganjil 2017 2018 Utk Sahril Dewi Ratna SjariLuthfia Puspa wulandariNoch keine Bewertungen
- Brummet Reed Gentrification 2021Dokument47 SeitenBrummet Reed Gentrification 2021Felix RiveraNoch keine Bewertungen
- The Leadership Quarterly State of The Journal - 2019 - The Leadership QuarterlyDokument9 SeitenThe Leadership Quarterly State of The Journal - 2019 - The Leadership QuarterlyvijjaiksinghNoch keine Bewertungen
- Multiple RegressionDokument17 SeitenMultiple RegressionHazilah Mohd Amin100% (1)
- Simple Linear Regression With ExcelDokument39 SeitenSimple Linear Regression With ExcelAbimanyu ShenilNoch keine Bewertungen
- L2 数量课件Dokument196 SeitenL2 数量课件Ran XUNoch keine Bewertungen
- Ezike, J. E., & Oke, M. O. (2013) .Dokument14 SeitenEzike, J. E., & Oke, M. O. (2013) .Vita NataliaNoch keine Bewertungen
- Relationship Marketing and The Amount of The Cafe in Optimizing Customer Loyalty Oase CoffeeDokument6 SeitenRelationship Marketing and The Amount of The Cafe in Optimizing Customer Loyalty Oase CoffeeInternational Journal of Innovative Science and Research TechnologyNoch keine Bewertungen
- Evaluation Metrics For Regression: Dr. Jasmeet Singh Assistant Professor, Csed Tiet, PatialaDokument13 SeitenEvaluation Metrics For Regression: Dr. Jasmeet Singh Assistant Professor, Csed Tiet, PatialaDhananjay ChhabraNoch keine Bewertungen
- Investigation of Toxic Effect of Moringa PDFDokument9 SeitenInvestigation of Toxic Effect of Moringa PDFMiguel JuguilonNoch keine Bewertungen
- Predictive Analytics For Future Life Expectancy Using Machine LearningDokument6 SeitenPredictive Analytics For Future Life Expectancy Using Machine LearningPODILA PRAVALLIKA 0576Noch keine Bewertungen